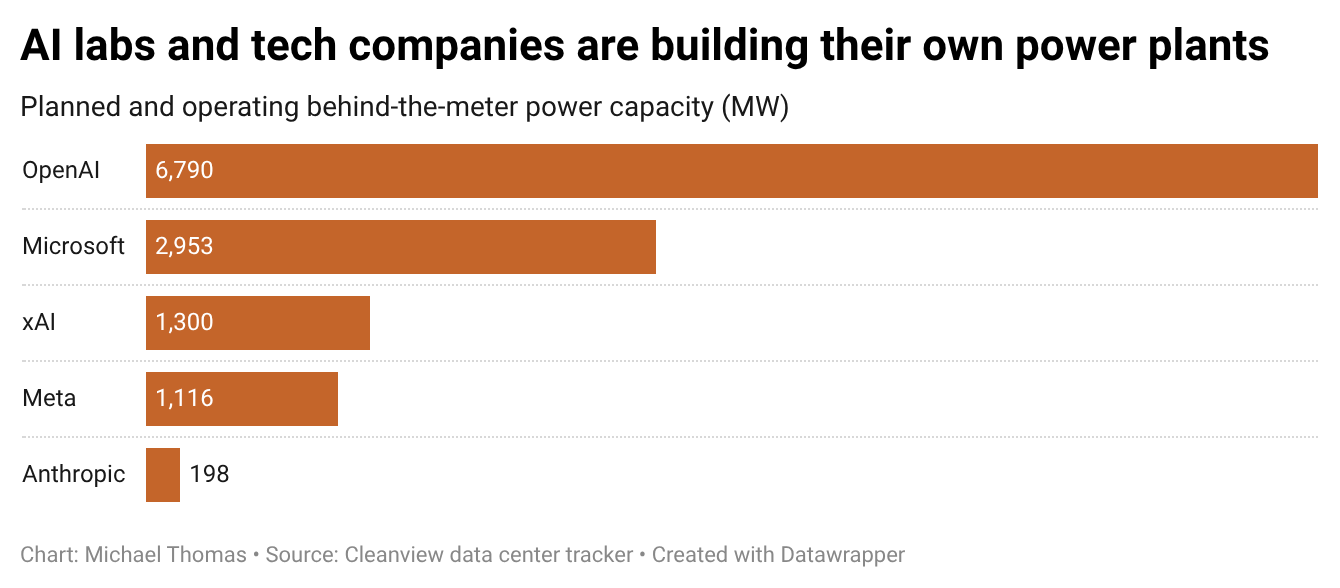
UniVidX, accepted at SIGGRAPH 2026, generates video across RGB, depth, and alpha channels after training on fewer than 1,000 samples. The framework uses diffusion priors with stochastic condition masking to achieve omni-directional generation from a single model.
Key facts
- Trained on fewer than 1,000 videos
- Accepted at SIGGRAPH 2026 conference
- Generates RGB, intrinsic maps, alpha channels
- Uses diffusion priors with stochastic masking
- No code or benchmark numbers released yet
UniVidX, a unified multimodal framework for versatile video generation, was announced via a tweet from @HuggingPapers. The model enables omni-directional generation across RGB, intrinsic maps, and alpha channels using diffusion priors with stochastic condition masking. Critically, it was trained on fewer than 1,000 videos for SIGGRAPH 2026.
The unique take: Most video generation models—like OpenAI's Sora or Google's Lumiere—require millions of video-text pairs and massive compute clusters. UniVidX's sub-1,000 video training set is orders of magnitude smaller, suggesting that diffusion priors combined with stochastic masking can dramatically compress the data needed for multimodal video generation. This could lower the barrier for custom video models in specialized domains (medical imaging, robotics simulation) where large datasets are unavailable.
[According to @HuggingPapers], the stochastic condition masking technique allows the model to handle diverse output modalities from a single unified framework. The paper was accepted at SIGGRAPH 2026, the premier computer graphics conference. No code or model weights have been released yet, nor have quantitative benchmarks (FVD, IS, CLIP score) been disclosed in the tweet.
Data Efficiency vs. Quality Tradeoff
Training on fewer than 1,000 videos raises questions about output quality and diversity. Without benchmark numbers, it's unclear whether the model matches SOTA quality from larger models. The diffusion prior may compensate for limited data, but ablation studies on mask ratios and prior strength would clarify the tradeoff.
Implications for Specialized Video Generation

If UniVidX generalizes beyond the demo domains, it could enable rapid fine-tuning for niche applications—synthetic data generation for robotics, medical video synthesis, or film pre-visualization—where collecting millions of videos is impractical. The SIGGRAPH acceptance lends credibility, but peer reviewers likely saw the full paper, not just the tweet.
What to watch
Watch for the full SIGGRAPH 2026 paper release, which should include quantitative benchmarks (FVD, CLIP score) and ablation studies on mask ratios. If code is open-sourced, replication attempts will reveal whether the data-efficiency claim holds across diverse video domains.