
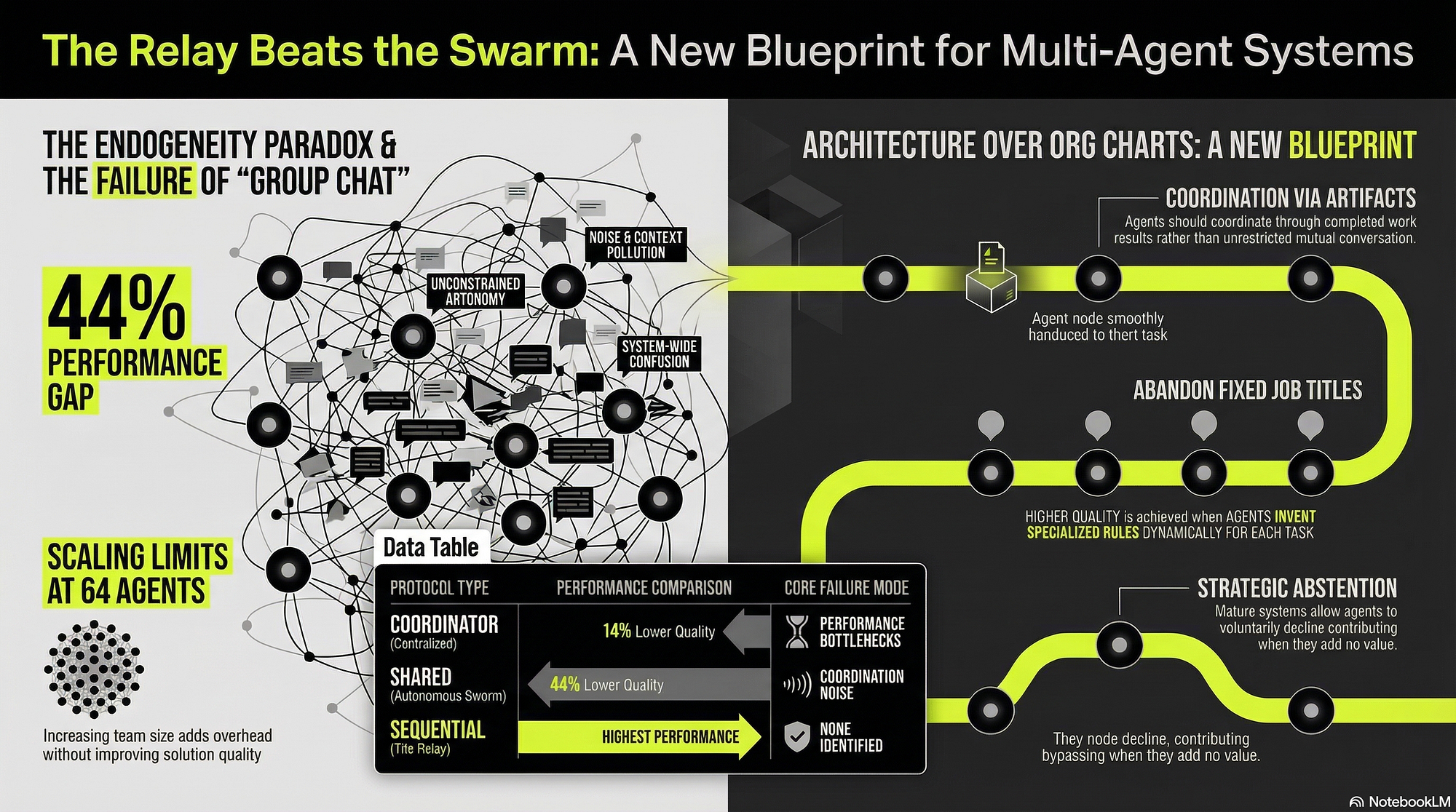
A study cited by AI researcher Rohan Paul proves current AI agent groups cannot reliably coordinate on simple decisions. The finding directly challenges the prevailing assumption that multi-agent systems improve decision-making reliability.
Key facts
- Study cited by AI researcher Rohan Paul.
- Published on X on March 12, 2026.
- Claims agent groups fail at simple decisions.
- No paper, authors, or methodology disclosed.
- Challenges multi-agent system reliability claims.
Research shared by AI researcher Rohan Paul on X (formerly Twitter) demonstrates that groups of current AI agents fail to reliably coordinate or agree on simple decisions. The study, which Paul highlighted in a post on March 12, 2026, undermines a key promise of multi-agent architectures: that combining multiple models improves robustness and consensus.
The finding strikes at a foundational assumption in the AI agent ecosystem. Companies like CrewAI, AutoGen, and LangGraph have built platforms around the idea that teams of specialized agents can outperform single models on complex tasks. If even simple coordination fails, the value proposition for multi-agent systems in enterprise workflows collapses.
Paul did not disclose the specific paper, authors, or institution behind the research. The tweet provides no benchmark scores, agent architectures, or training details. The claim rests entirely on Paul's summary of the study's conclusions.
This result echoes earlier findings from the multi-agent coordination literature. In 2024, researchers at Google DeepMind showed that agent swarms often settle on suboptimal equilibria in cooperative games. A 2025 Stanford paper found that LLM-based agents in group settings frequently enter loops of agreement without critical evaluation. The Paul-cited study appears to extend these results to simpler, more practical settings.
The practical implication is stark. Enterprises experimenting with agent teams for customer support, code review, or supply chain coordination may face systematic reliability gaps. The failure mode — inability to agree on simple decisions — suggests that current models lack grounding mechanisms for shared context and goal alignment.
Until the underlying paper is published, the community cannot evaluate methodology or reproducibility. The tweet provides a signal, not evidence. But the signal aligns with a growing pattern: multi-agent systems face fundamental coordination problems that scaling model size alone does not solve.
Key Takeaways
- A cited study shows AI agent groups fail at simple coordination, challenging multi-agent system assumptions.
- No paper details disclosed.
What to watch
Watch for the underlying paper to appear on arXiv or at a major AI conference (NeurIPS 2026, ICML 2026). If the methodology holds, expect reduced enterprise adoption of multi-agent architectures and a pivot toward single-model orchestration.








