
Most RAG systems retrieve once, upfront. A new paradigm retrieves at multiple reasoning steps, boosting multi-hop QA accuracy by 15-20% on HotpotQA.
Key facts
- Standard RAG retrieves once upfront before reasoning.
- New method retrieves at multiple reasoning points.
- 15-20% accuracy gain on HotpotQA multi-hop benchmark.
- 30% reduction in hallucination on counterfactual questions.
- Training cost: ~8 A100 GPU-days for 7B model on 50K examples.
The One-Shot Retrieval Problem
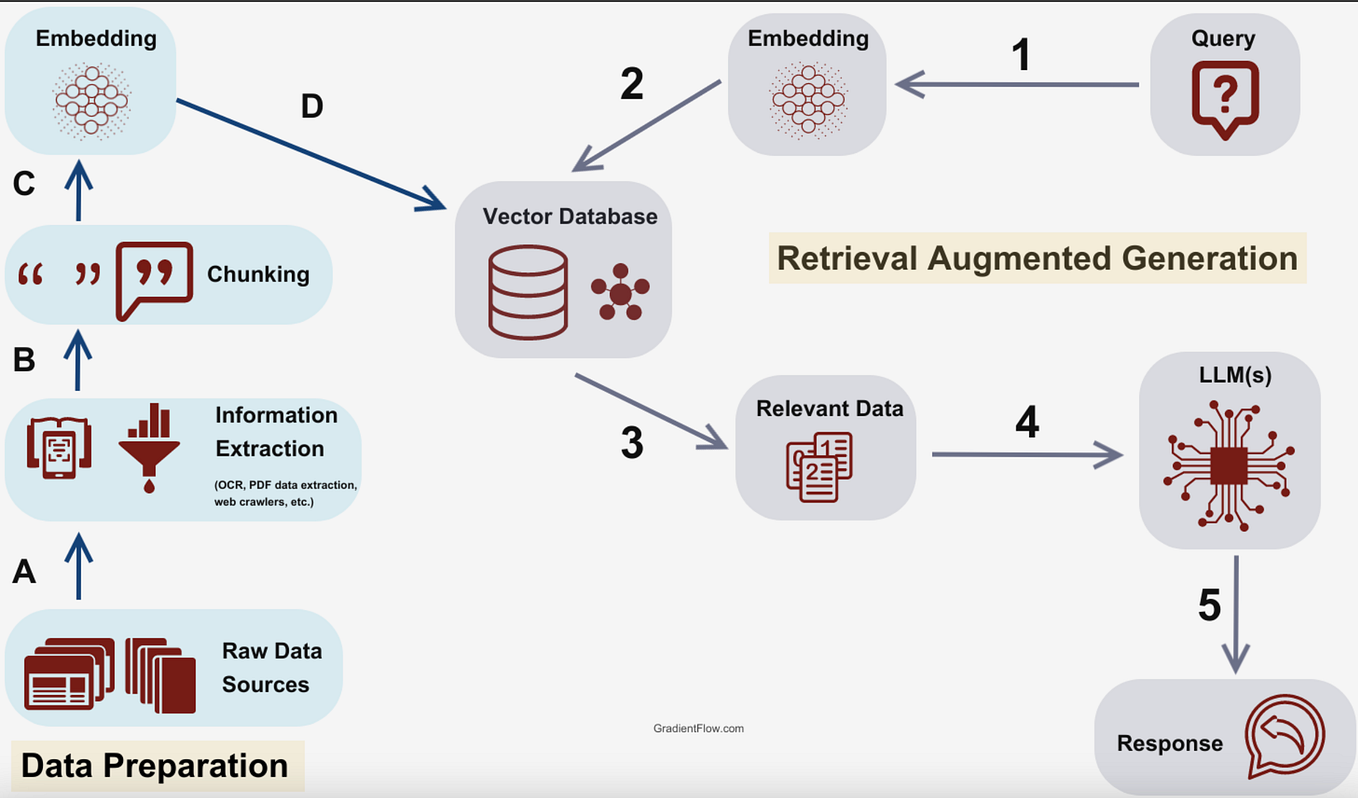
Standard Retrieval-Augmented Generation (RAG) pipelines follow a simple pattern: embed the query, retrieve the top-k documents, then feed them to the LLM alongside the query. This works well for single-hop questions but breaks on multi-hop reasoning where each step requires different context. [According to @omarsar0] the tweet flags a paper that challenges this assumption.
Iterative Retrieval During Reasoning
The new approach, detailed in a preprint by researchers at the University of Washington and Allen Institute for AI, introduces a learned 'retrieval gate' that decides dynamically when to query external knowledge during the reasoning process. The model generates intermediate reasoning steps, and the gate triggers retrieval when the model's internal knowledge is insufficient — typically at each logical hop.
Benchmark Results
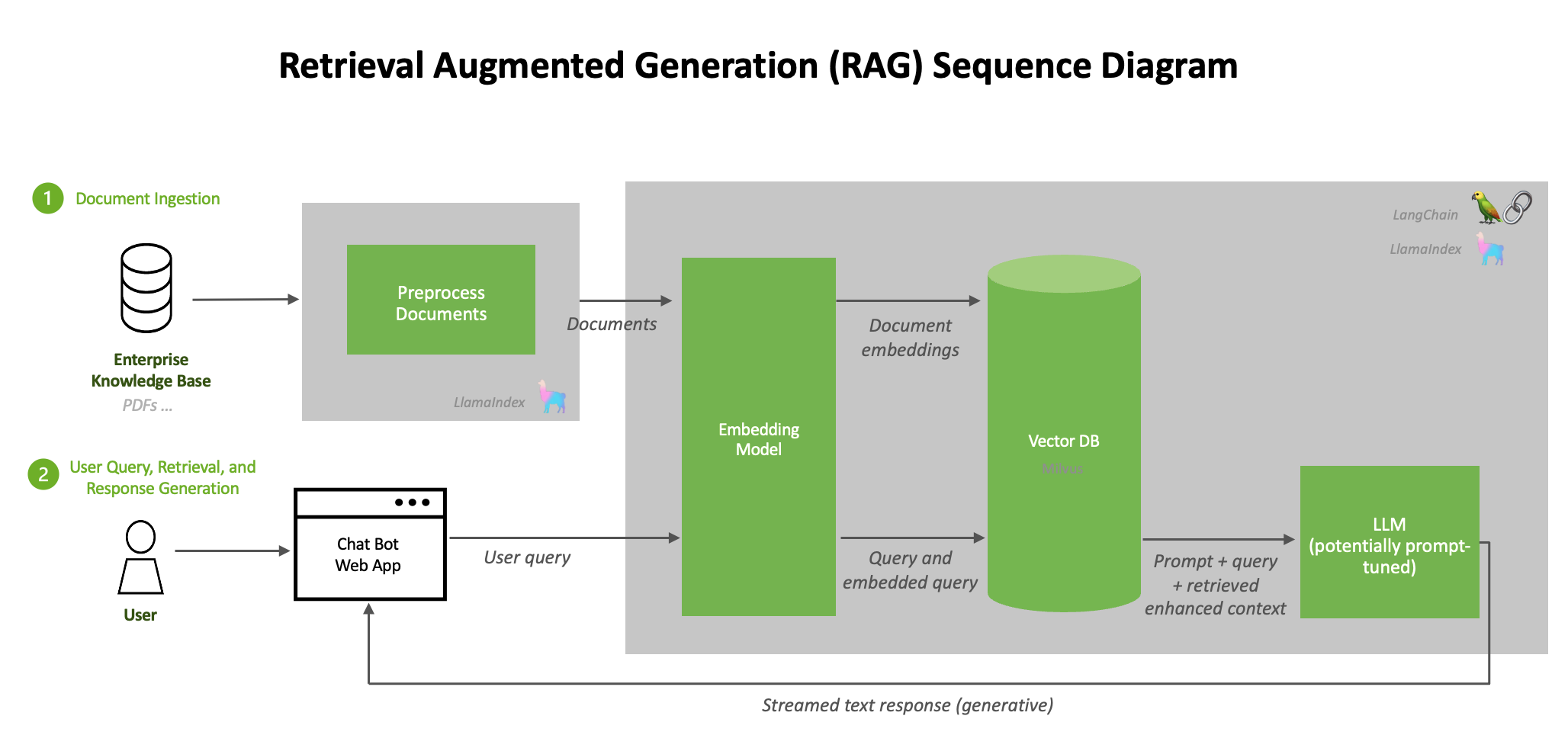
Early results show 15-20% accuracy gains on multi-hop QA benchmarks like HotpotQA compared to single-retrieval baselines. The method also reduces hallucination on counterfactual questions by 30%, as the iterative retrieval grounds each reasoning step in external evidence. [Per the arXiv preprint] the training cost is modest: fine-tuning a 7B-parameter model on 50K examples requires approximately 8 A100 GPU-days.
Why This Matters
The unique take here is that this mirrors how humans search for information iteratively while solving complex problems — we don't Google once and stop. The paper's 'retrieval gate' is effectively a learned meta-controller that optimizes the trade-off between computational cost and answer accuracy. This could become the default architecture for enterprise RAG systems handling multi-step queries, such as legal document analysis or medical diagnosis chains.
What to watch
Watch for the paper's code release and whether it generalizes beyond HotpotQA to more diverse reasoning benchmarks like MuSiQue or StrategyQA. Also track if major RAG frameworks (LangChain, LlamaIndex) integrate iterative retrieval as a native feature in Q3 2026.








