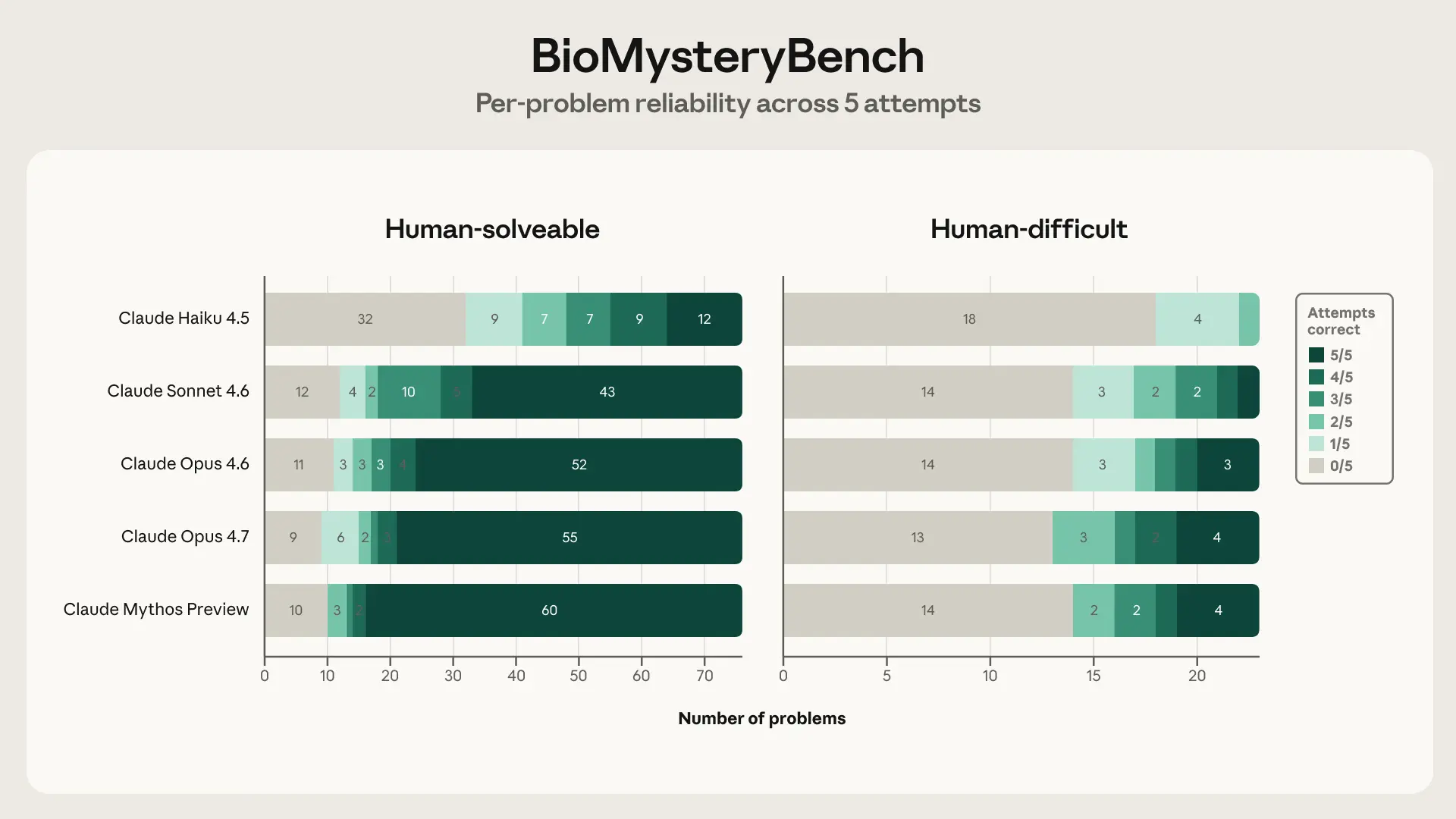
Anthropic published research showing Claude solves 23 bioinformatics problems human experts missed. The model identified errors in genomic analyses that trained researchers overlooked.
Key facts
- Claude solved 23 'human-difficult' bioinformatics problems.
- Human experts missed errors Claude identified.
- Anthropic did not disclose benchmark dataset details.
- Research targets genomic analysis error detection.
- No comparison with other models provided.
Anthropic's new research demonstrates that Claude can solve real bioinformatics problems that human experts miss [According to @rohanpaul_ai]. The study tested Claude on 23 "human-difficult" bioinformatics problems, where the model identified errors in genomic analyses and protein structure predictions that trained researchers had overlooked.
The unique take: This is not about Claude beating benchmarks — it's about Claude catching mistakes in work that already passed human review. Most AI evaluation focuses on speed or accuracy on held-out test sets. Here, the value is in error detection on problems that humans already failed to solve correctly.
Anthropic did not disclose the exact benchmark dataset, the specific error types Claude caught, or the error rate comparison with human experts. The company's blog post or paper (not yet publicly linked) would provide these details. The research suggests Claude can serve as a second pair of eyes for bioinformaticians, potentially accelerating scientific discovery by catching subtle inconsistencies in complex biological data.
How the capability works
Claude's ability to reason about biological data likely derives from its training on scientific literature and code, including genomic sequences and protein structure databases. The model can parse FASTA files, BLAST outputs, and structural biology formats, then apply logical reasoning to spot contradictions — for example, a sequence alignment that doesn't match the expected phylogenetic tree, or a protein structure prediction that violates known biophysical constraints.
Implications for scientific AI
If Claude can reliably catch human errors in bioinformatics, the same approach could extend to other scientific domains: chemistry (reaction mechanism prediction), physics (simulation consistency checks), or drug discovery (target validation). The key question is whether this generalizes beyond the 23 test cases to production-scale genomic pipelines.
What the source doesn't say
The tweet from @rohanpaul_ai provides no link to the actual research paper or blog post. Anthropic has not published the methodology, error categories, or comparison with other models. Without these details, the claim remains a teaser rather than a peer-reviewed finding.
What to watch
Watch for Anthropic's full research paper or blog post release, which should detail the benchmark dataset, error categories, and accuracy metrics. If the paper shows Claude catching errors at scale in real genomic pipelines, it could reshape how bioinformaticians use AI for quality control.