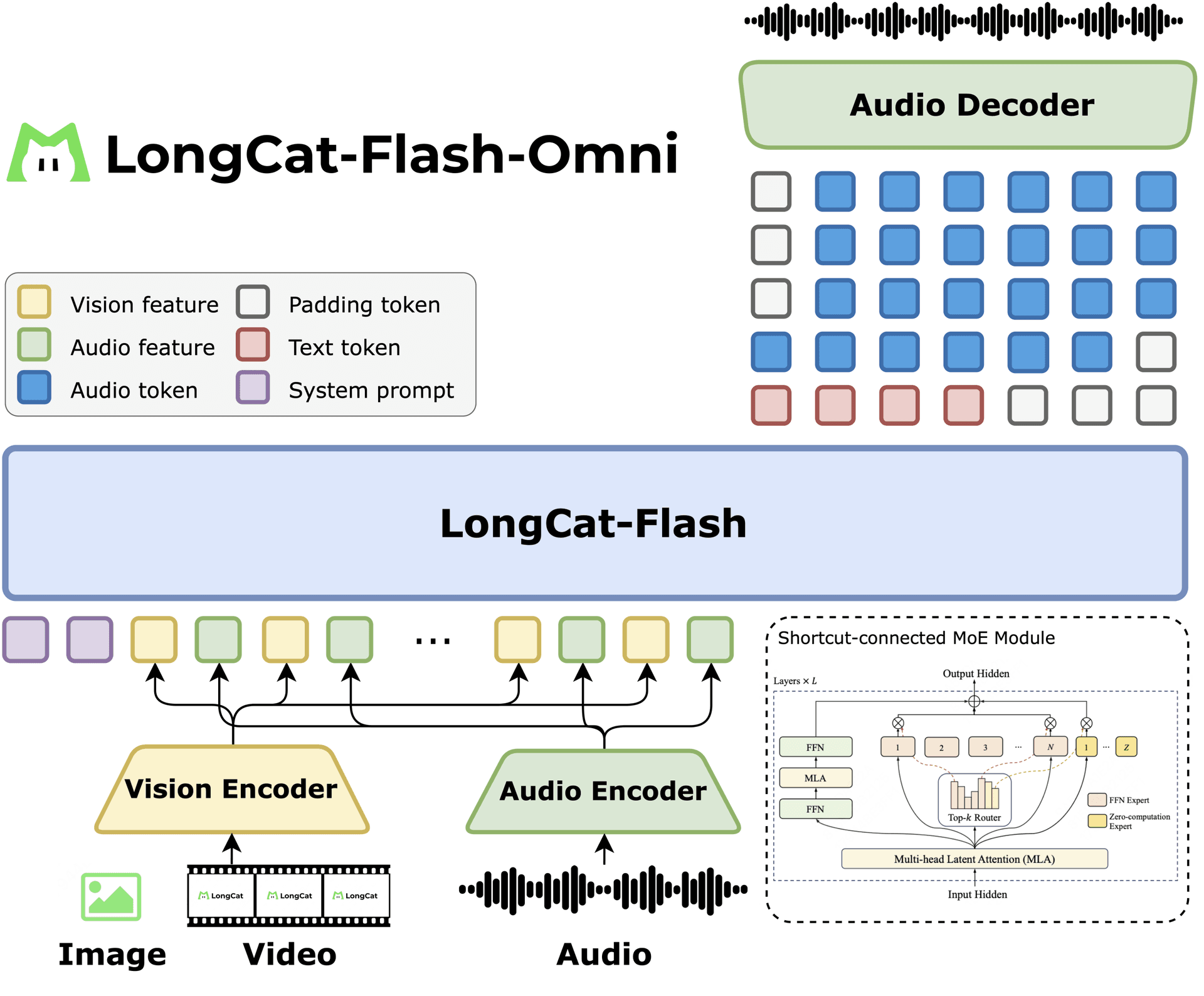
SenseTime open-sourced what it claims is the first AI model that reasons jointly in pixel and word space. The architecture eliminates the traditional visual encoder (e.g., CLIP, SigLIP) and the VAE decoder.
Key facts
- No visual encoder (CLIP, SigLIP) used.
- No VAE decoder for image generation.
- First omni-modal model reasoning in pixel-word space.
- Open-source release includes weights and code.
- No benchmark numbers disclosed yet.
SenseTime open-sourced what it claims is the first AI model that reasons jointly in pixel and word space. The architecture eliminates the traditional visual encoder (e.g., CLIP, SigLIP) and the VAE decoder, instead performing reasoning directly in a unified representation that spans both modalities.
The model processes and generates both modalities within a single unified representation, rather than converting images to latent codes or tokens before language reasoning. This omni-modal approach contrasts with prior work like GPT-4V, Gemini, or LLaVA, which use a vision encoder (CLIP, SigLIP, etc.) to project images into language-model token space, then decode through a VAE for image generation. SenseTime's model keeps pixel-level fidelity throughout the reasoning chain, potentially enabling finer-grained visual understanding and generation.
[According to @hasantoxr] The open-source release includes model weights, inference code, and a technical report. No benchmark numbers were disclosed in the initial announcement. The repository appears to target researchers working on multimodal reasoning, visual generation, and unified architectures.
The key question is whether this unified representation scales to GPT-4V-level performance. Prior attempts at joint pixel-word models (e.g., CM3leon by Meta, 2023) showed promise but lagged behind separate-encoder pipelines on standard benchmarks like VQAv2 or MS-COCO captioning. SenseTime's model may trade off modularity for representational coherence, but the lack of published metrics makes comparison impossible.
Unique Take
This release challenges the dominant multimodal paradigm of 'encode-then-concatenate' (vision encoder + LLM). If the model performs competitively, it would validate that omni-modal reasoning can match modular pipelines while enabling new capabilities like pixel-level editing without separate decoders. The open-source availability accelerates experimentation but also invites scrutiny: without benchmark numbers, the claim remains unverified.
What to watch

Watch for the release of benchmark results on standard multimodal tasks (VQAv2, MS-COCO captioning, MMLU) in the technical report. A comparison against GPT-4V or Gemini on visual reasoning tasks would validate the omni-modal approach.







