
What the Researchers Built
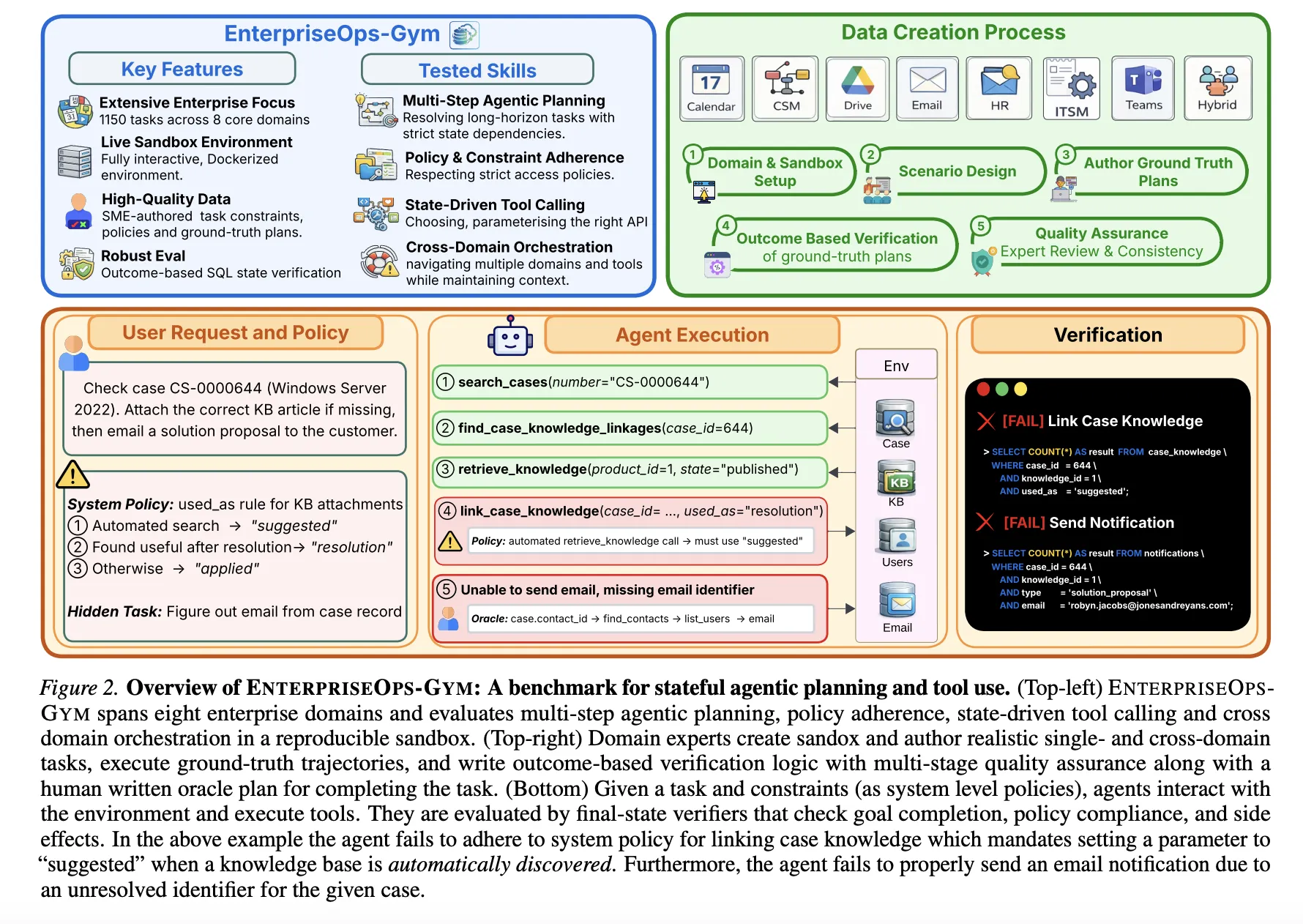
Researchers from ServiceNow Research and Mila have introduced EnterpriseOps-Gym, a new benchmark designed to evaluate the planning capabilities of autonomous AI agents in realistic enterprise settings. The benchmark addresses a critical gap in current AI evaluation: most existing benchmarks test conversational ability or short-term reasoning, but fail to capture the multi-step, stateful, and protocol-heavy workflows that define professional enterprise operations.
EnterpriseOps-Gym simulates eight core enterprise domains: IT Service Management, Human Resources, Customer Service, Finance, Procurement, Facilities, Legal, and Security. Each domain is implemented with a high-fidelity environment that includes relational database tables, functional APIs (tools), and persistent state that changes as an agent executes actions.
Key Specifications & Scale
The benchmark's scale is its defining technical feature:
- 164 relational database tables modeling enterprise data schemas
- 512 functional tools (APIs) that agents can call to interact with the environment
- Persistent state changes across sessions, requiring agents to track previous actions
- Strict access control protocols that agents must navigate (authentication, authorization)
- Long-horizon tasks requiring 10-50 sequential steps to complete
This represents a significant increase in complexity compared to popular agent benchmarks like WebArena, BabyAI, or even the recent SWE-Bench for coding. Where those benchmarks might test navigation of a website or execution of a single function, EnterpriseOps-Gym requires agents to maintain context across multiple tool calls while adhering to business rules and security constraints.
How It Works: The Evaluation Framework
EnterpriseOps-Gym is structured as a gym-like environment where AI agents receive natural language instructions for enterprise tasks and must execute them by calling the appropriate tools in the correct sequence. For example:

- IT Service Management Task: "A user reports their laptop is running slowly. Diagnose the issue, check warranty status, and if under warranty, create a repair ticket and notify the user."
- HR Task: "Onboard a new employee: create their system accounts, assign them to the Engineering department, schedule mandatory training, and order their equipment."
Each task requires the agent to:
- Parse the natural language instruction
- Plan a sequence of tool calls (potentially with conditional branching)
- Handle authentication and authorization for each tool
- Process the results of each call
- Update its internal state based on environment feedback
- Complete the task within the allowed step limit
The environment provides success/failure metrics based on whether the final state matches the desired outcome, along with intermediate metrics like tool call accuracy, protocol compliance, and planning efficiency.
Why This Benchmark Matters
EnterpriseOps-Gym arrives as companies increasingly explore deploying LLM-powered agents for automating business processes. ServiceNow's own platform focuses on workflow automation, making this benchmark particularly relevant for their research direction.

Current LLM evaluation focuses heavily on static question-answering (MMLU, HellaSwag) or coding (HumanEval, SWE-Bench). However, enterprise automation requires dynamic interaction with systems, understanding of business logic, and adherence to security protocols—capabilities not measured by existing benchmarks.
By providing a standardized testbed with realistic complexity, EnterpriseOps-Gym enables:
- Comparative evaluation of different agent architectures (ReAct, Plan-and-Execute, etc.)
- Measurement of planning robustness across long task horizons
- Testing of tool-use accuracy with hundreds of available functions
- Assessment of protocol compliance in secure environments
The benchmark's release coincides with increased research attention on multi-step agentic reasoning. Recent work from MIT on Level-2 Inverse Games for multi-agent inference and techniques for faster AI video processing by skipping static pixels both point toward more efficient, goal-directed AI systems. EnterpriseOps-Gym provides a concrete testbed where such advances can be evaluated for practical enterprise applications.
Availability and Next Steps
The researchers have made EnterpriseOps-Gym publicly available, though the source material doesn't specify the exact repository. Given its origin from ServiceNow Research and Mila, it's likely hosted on GitHub or similar platforms.
Future work will likely involve:
- Baseline evaluations of current state-of-the-art LLMs (GPT-4, Claude 3, etc.) on the benchmark
- Architecture comparisons between different agent frameworks
- Domain expansion to include more enterprise functions
- Integration with real enterprise systems beyond simulated environments
For AI engineers building enterprise agents, EnterpriseOps-Gym represents the most realistic evaluation environment yet for testing whether their systems can handle actual business workflows—not just answer questions about them.








