Tavus announced on X that its AI avatars no longer require source video footage. The new capability allows creation from images or text descriptions, per @kimmonismus.
Key facts
- Tavus eliminates need for source video footage
- Avatars generated from images or text descriptions
- Announced via X post by @kimmonismus
- No technical paper or benchmarks disclosed
- Targets enterprise video production use cases
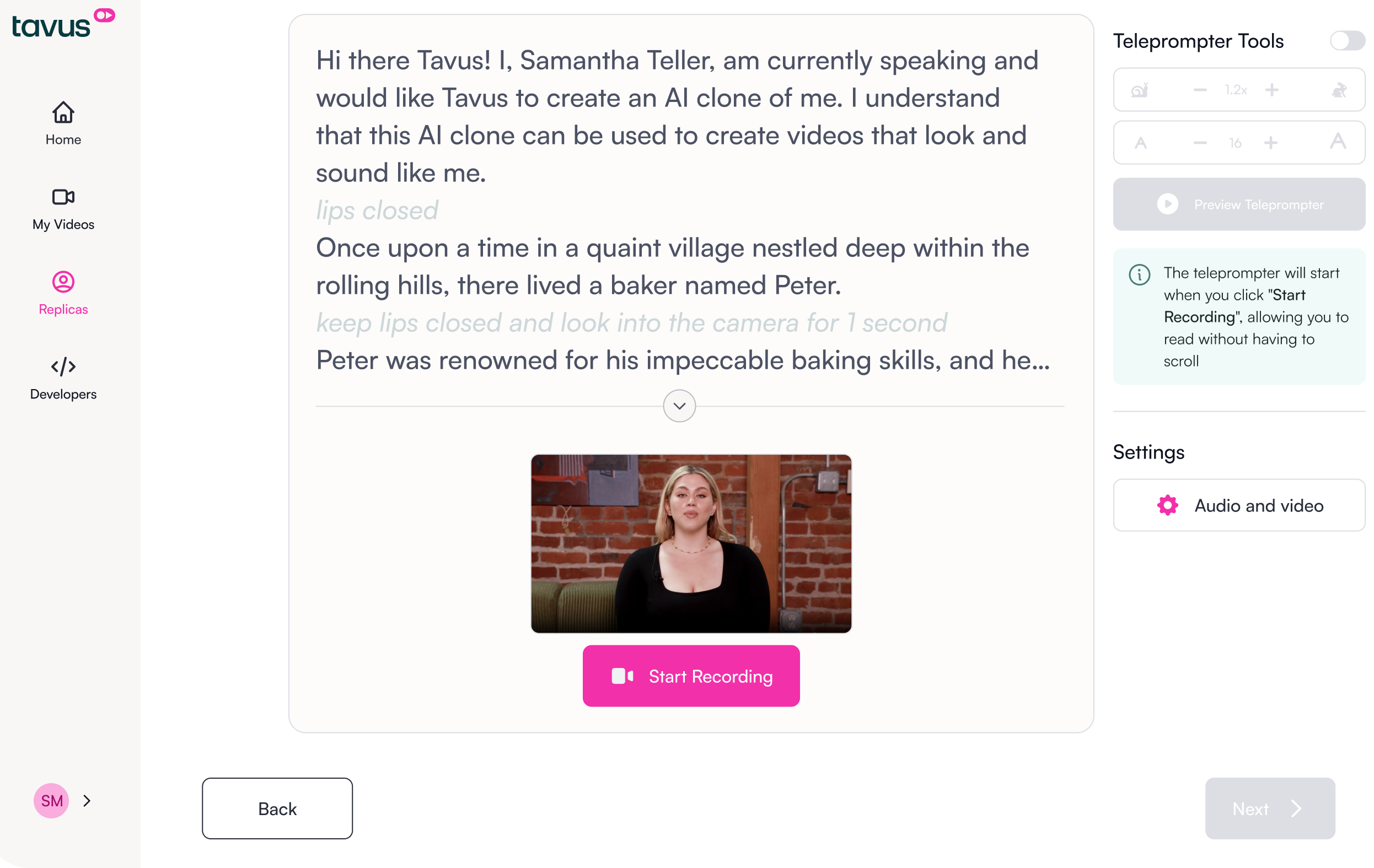
Tavus, a startup specializing in AI-generated human avatars for enterprise video, announced a significant product update: its platform can now generate convincing AI humans without any video footage of a real person. The announcement came via a post on X by @kimmonismus, with no blog post or technical paper yet released. [According to @kimmonismus] Until now, building a convincing AI human required video footage of a real person. Tavus just removed that constraint, enabling AI avatar generation without any source video.
The new capability allows users to create a convincing AI human from static images or even text descriptions. This shift removes the single biggest barrier to synthetic avatar deployment at scale: the need for a human actor to record a reference video. For enterprises, this means faster iteration, lower production costs, and the ability to generate avatars for historical figures or entirely fictional characters.
The Unique Take
Tavus's move signals a broader industry trend toward fully synthetic avatars, where the training data is entirely generated rather than captured. This approach, if it holds quality, could disrupt the current market dominated by companies like Synthesia and Hour One, which still rely on actor-recorded video for their base models. The key question is whether Tavus can maintain the same level of lip-sync accuracy and natural movement without real footage — a challenge that has historically required hours of high-quality video for training. [According to @kimmonismus] The company did not disclose the specific model architecture or training data used.
What This Means for the Market
For enterprise users, the ability to generate avatars from a single photo or a text prompt dramatically lowers the barrier to entry for personalized video content at scale. Use cases include sales outreach, internal training, and customer support — any scenario where a human face adds trust but where recording a real person is impractical. However, the lack of a technical paper or benchmark comparison leaves open questions about fidelity, especially for complex expressions or non-English languages.
Tavus's move comes as the AI avatar market sees increasing competition from both startups and larger platforms. The company has not disclosed pricing for the new feature or whether it is available in beta or general release. [According to @kimmonismus] The announcement was made on X, suggesting a rapid product update rather than a major launch event.
Key Takeaways
- Tavus announced AI avatars no longer need source video, enabling generation from images or text.
- The shift lowers barriers for enterprise video production.
What to watch
Watch for Tavus to release a technical blog post or white paper detailing the model architecture and training data. Also monitor benchmark comparisons against Synthesia and Hour One for lip-sync accuracy and natural movement — the key quality metrics for enterprise adoption.