A groundbreaking analysis from the General-Purpose AI Policy Lab has mapped artificial intelligence capabilities directly to human expertise levels, revealing that current frontier AI models have already surpassed domain experts in technical and scientific benchmark tasks. The research, which extends the "Rosetta Stone for AI Benchmarks" framework developed by Epoch AI and Google DeepMind researchers, provides the first concrete human-anchored scale for interpreting AI capability scores.
The Rosetta Stone Framework: From Abstract Scores to Human Benchmarks
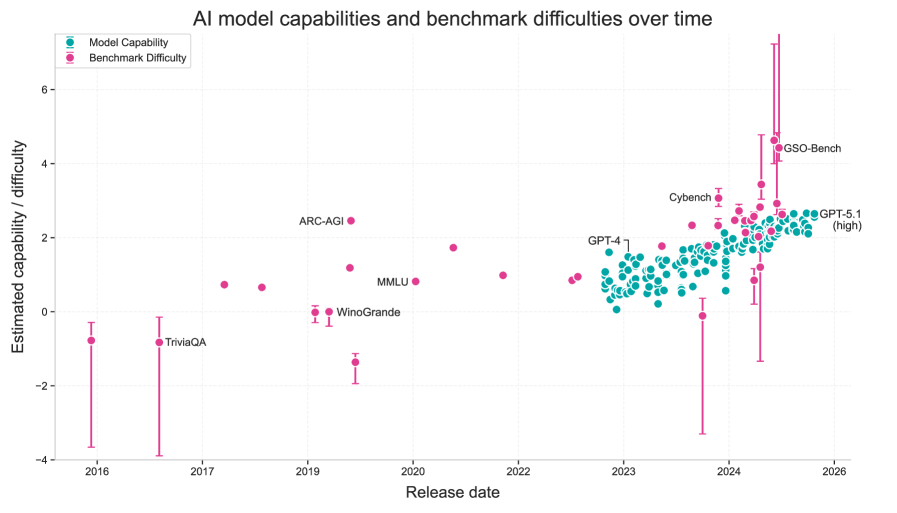
The original "Rosetta Stone" paper, published on arXiv, created a unified difficulty scale that allows different AI benchmarks and models to be compared directly. This framework underpins the Epoch Capability Index (ECI), which has become a valuable tool for tracking AI progress. However, as the researchers note, the resulting capability scores remained abstract—what does a score of 2.54 actually mean in practical terms?
To address this interpretability gap, the research team integrated human performance baselines directly into the Rosetta framework. They collected data on human performance across multiple expertise levels, ranging from crowd workers to PhD-level domain experts and top performers in their fields. This integration transforms abstract capability scores into meaningful comparisons with human abilities.
Methodology: Navigating Benchmark Biases
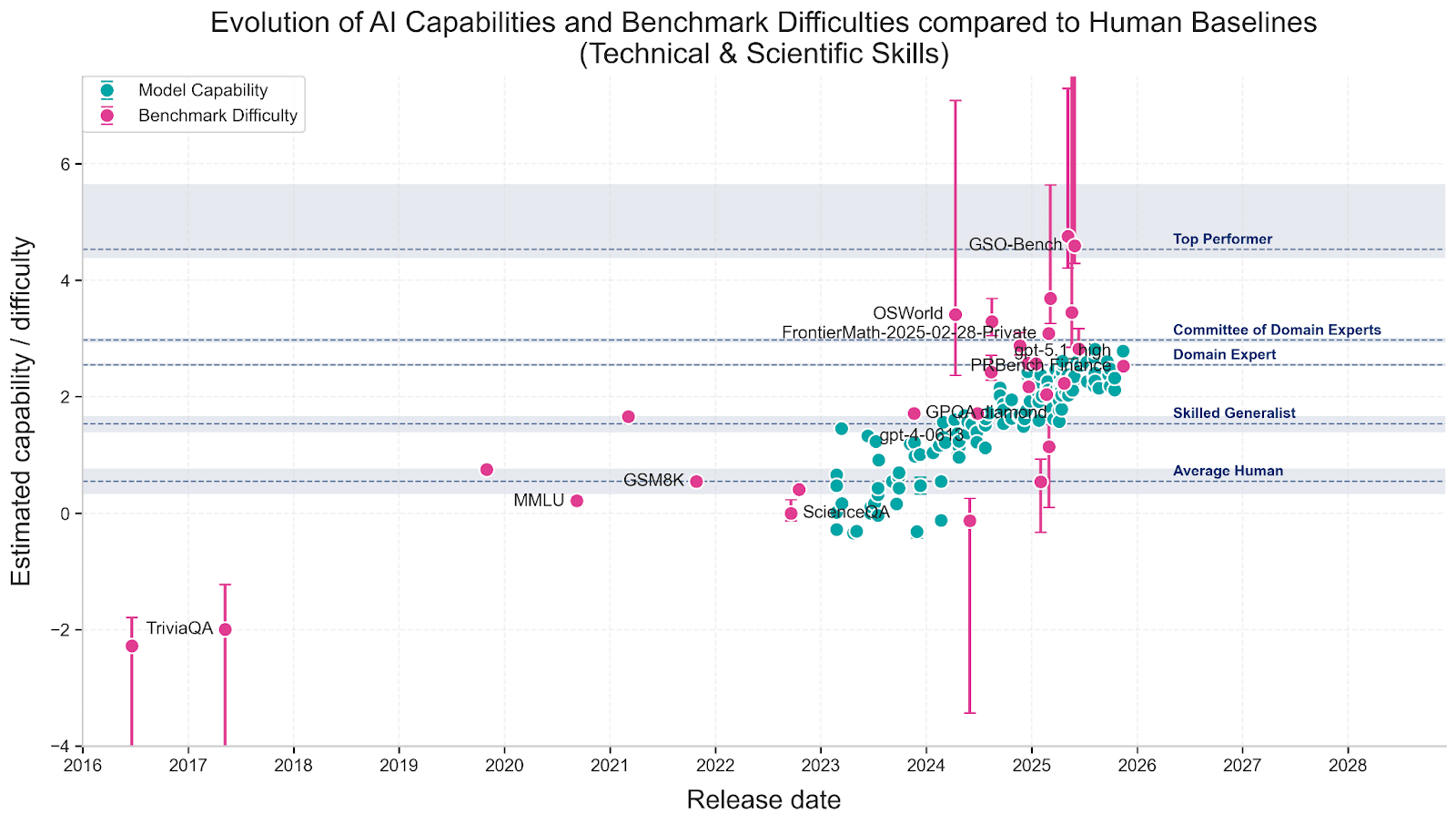
One significant challenge the researchers faced was that some benchmarks have been specifically designed to be "AI-hard"—tasks that are easy for humans but difficult for AI systems. This design choice contradicts the Rosetta framework's assumption of a single axis of capability and difficulty. To account for this potential bias, the team performed their analysis both with and without these specially designed benchmarks, ensuring their conclusions weren't skewed by benchmark design choices.
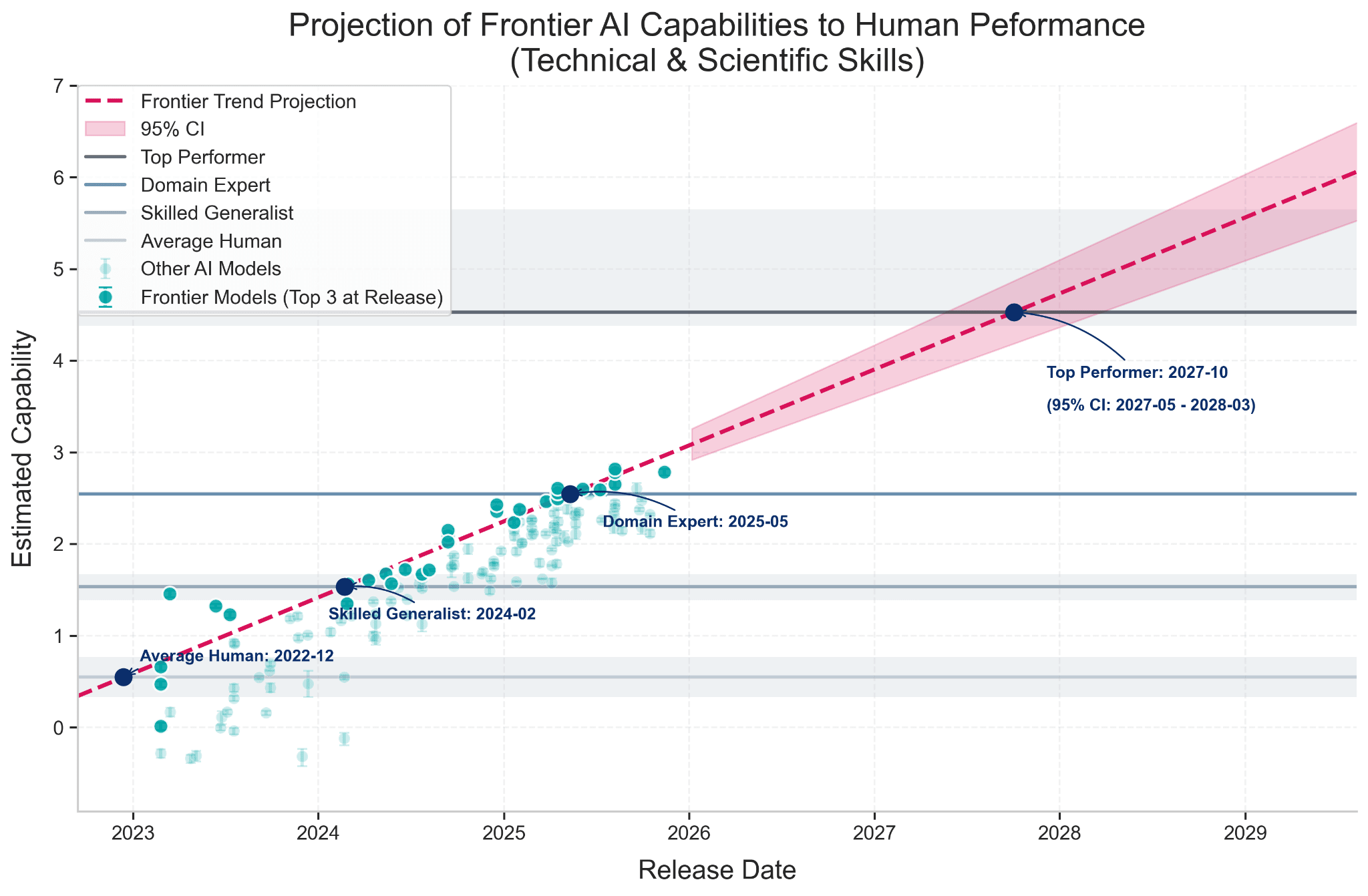
The analysis focused primarily on technical and scientific benchmark skills, where human performance data was most reliable and comparable. This restriction is important—the findings don't necessarily apply to creative, social, or physical tasks where AI capabilities differ significantly.
Key Findings: AI's Rapid Ascent Through Human Expertise Levels
The results reveal a startling pace of AI advancement relative to human expertise:
- Average Human Level: Frontier AI models crossed this threshold in late 2022
- Skilled Generalist Level: AI surpassed this level in early 2024
- Domain Expert Level: Current frontier models have now exceeded this level (as of 2025)
Perhaps most strikingly, the research forecasts that AI will reach Top-Performer human levels by October 2027, with a 95% confidence interval ranging from May 2027 to March 2028. This projection suggests we're just a few years away from AI systems that can outperform the best humans in technical benchmark tasks.
Limitations and Caveats
The researchers emphasize several important limitations to their analysis. First, benchmarks remain imperfect proxies for real-world capabilities—excelling at benchmark tasks doesn't necessarily translate to practical expertise in complex, real-world scenarios. Second, human performance data is inconsistently collected and sparse for many domains, making precise comparisons challenging.
Additionally, the forecasted timeline should be "interpreted with a grain of salt," as the researchers note. AI progress isn't guaranteed to follow historical trends, and unexpected bottlenecks or breakthroughs could accelerate or delay these projections.
Implications for AI Policy and Development
This research has significant implications for AI policy and safety. By providing concrete human reference points for AI capabilities, policymakers and researchers can better assess when AI systems might reach concerning capability thresholds. The finding that AI has already surpassed domain experts in technical benchmarks suggests we may need to rethink traditional assumptions about human expertise maintaining an advantage in specialized domains.
The integration of human baselines into capability assessment frameworks represents an important step toward more interpretable AI evaluation. As AI systems become more capable, understanding how they compare to human abilities becomes increasingly crucial for responsible development and deployment.
Source: General-Purpose AI Policy Lab research blog, extending the "Rosetta Stone for AI Benchmarks" framework developed by Epoch AI and Google DeepMind researchers.