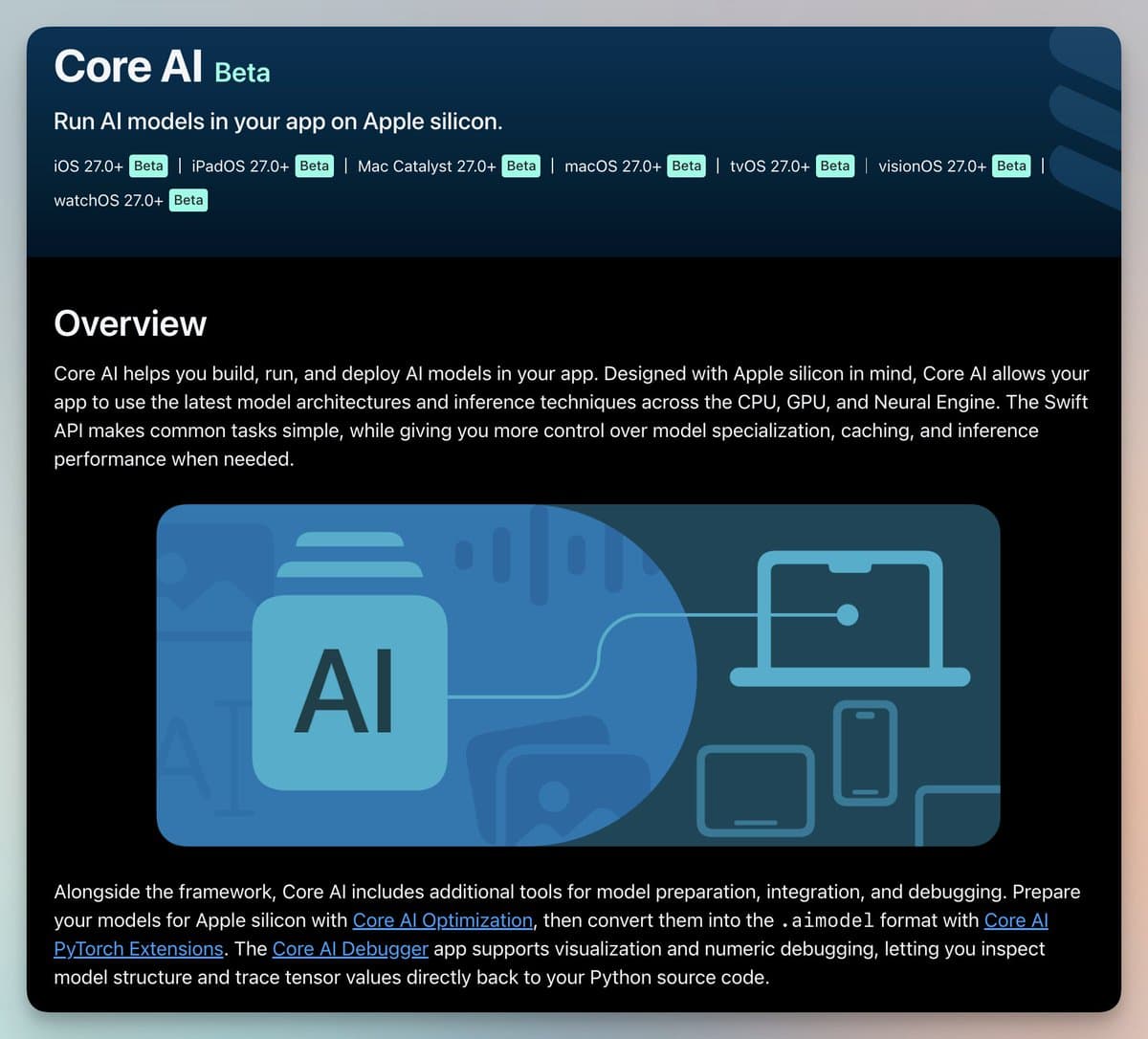
Apple launched Core AI, a framework that runs models entirely on Apple silicon. Inference happens on the user's device with zero server calls and zero token bills.
Key facts
- Core AI runs models on Apple silicon with zero server calls.
- Supports Qwen, Mistral, and SAM3 natively.
- Includes a memory-safe Swift API for near-instant load.
- Optimizer shrinks models layer by layer with minimal accuracy loss.
- macOS debugger profiles performance and traces Python code.
Apple launched Core AI, a framework that runs models entirely on Apple silicon. Inference happens on the user's device with zero server calls and zero token bills. According to @akshay_pachaar, the framework supports Qwen, Mistral, and SAM3 running natively across iPhone, iPad, Mac, and Vision Pro.
What Core AI includes
The framework provides a memory-safe Swift API that compiles models ahead of time for near-instant load. Pulling in a model takes a few lines of code, as shown in the source: let segmenter = try await ImageSegmenter(resourcesAt: sam3ModelURL). Beyond the runtime, Core AI ships curated open models packaged for Swift, PyTorch extensions to convert custom models, and an optimizer that shrinks models layer by layer with minimal accuracy loss. A macOS debugger profiles performance and traces behavior back to original Python code, while Xcode tools validate models before shipping.
Why this matters
For any team wanting real on-device AI without a cloud bill attached to every user, this is the answer. Apple's move sidesteps the recurring inference costs that plague cloud-dependent services, making it attractive for privacy-sensitive applications and offline use cases. The framework's ability to run models like Qwen and Mistral natively on Apple hardware positions it against Google's ML Kit and Meta's on-device efforts, but with tighter hardware-software integration.
What's missing
The source does not disclose specifics on model performance benchmarks, supported model sizes, or availability dates beyond the initial announcement. Apple has not confirmed whether Core AI will be open-sourced or remain proprietary. The curated model repo link was provided but without details on license terms or update cadence.
Key Takeaways
- Apple launched Core AI for on-device model inference on Apple silicon.
- Zero server calls, supports Qwen, Mistral, SAM3 across devices.
What to watch

Watch for Apple's developer documentation release and benchmark comparisons against Google ML Kit and Meta's on-device frameworks. The first third-party apps using Core AI in production will signal adoption velocity, with a likely WWDC 2026 session detailing performance metrics.
[Updated 10 Jun via nvidia_blog]
NVIDIA's confidential computing GPUs are now powering server-side inference for Apple's Private Cloud Compute (PCC), expanding beyond Apple's own data centers to Google Cloud, according to NVIDIA's blog. This marks a shift from the purely on-device Core AI framework, as Apple Foundation Models will also run on NVIDIA hardware for confidential cloud inference, leveraging custom models built with Google.