
Evaluating the outputs of large language models (LLMs) is a critical but expensive bottleneck. The prevailing method, "LLM-as-a-Judge," uses a powerful model like GPT-4 to assess the quality of another model's responses, incurring significant computational and API costs. New research introduces "BERT-as-a-Judge," a method that uses a fine-tuned BERT model to perform the same evaluation task, matching the performance of its heavyweight counterparts at a fraction of the cost.
Key Takeaways
- Researchers propose 'BERT-as-a-Judge,' a lightweight evaluation method that matches the performance of costly LLM-as-a-Judge setups.
- This could drastically reduce the cost of automated LLM evaluation pipelines.
What Happened
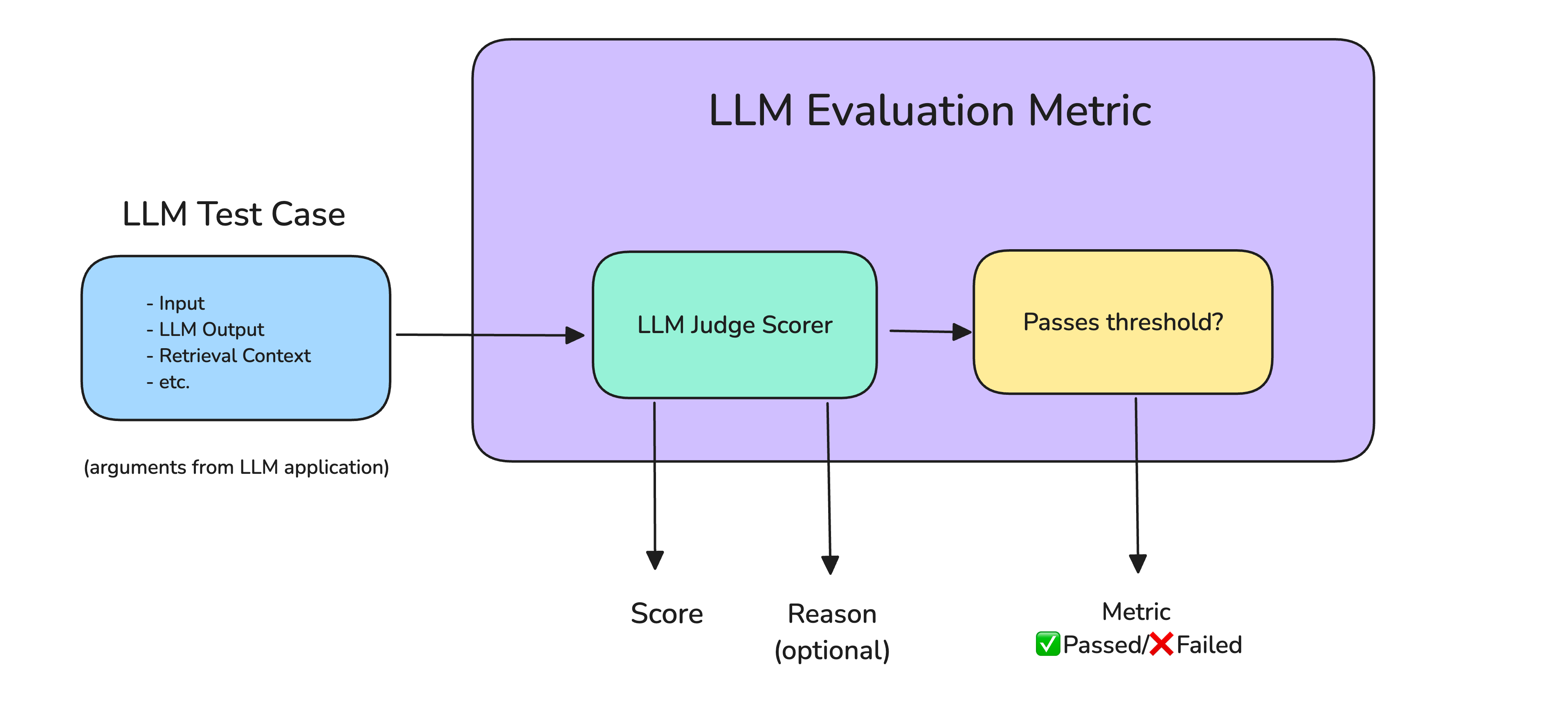
The core finding, shared via the @HuggingPapers account, is that a relatively small, fine-tuned BERT model can be used as an evaluator for LLM outputs. This approach is presented as a robust alternative to rigid lexical matching (like ROUGE or BLEU scores) and a cost-effective substitute for the computationally intensive LLM-as-a-Judge paradigm. The linked paper demonstrates that this method achieves performance parity with LLM judges while being vastly more efficient.
How It Works
The intuition is straightforward: instead of using a multi-trillion parameter LLM to judge every response, train a smaller, specialized model to perform the same discriminative task. BERT-as-a-Judge is built by fine-tuning a BERT-base or BERT-large model on a dataset of (question, answer, judgment) pairs. These judgments are typically generated by a strong LLM judge like GPT-4, creating a form of knowledge distillation.
Once trained, the BERT model takes a question and a candidate answer as input and outputs a classification (e.g., "good," "bad," or a score). The architecture leverages BERT's bidirectional understanding to assess the relevance, correctness, and helpfulness of the answer in the context of the question. This process is orders of magnitude cheaper than calling a massive LLM API for every single evaluation.
Key Results & Implications
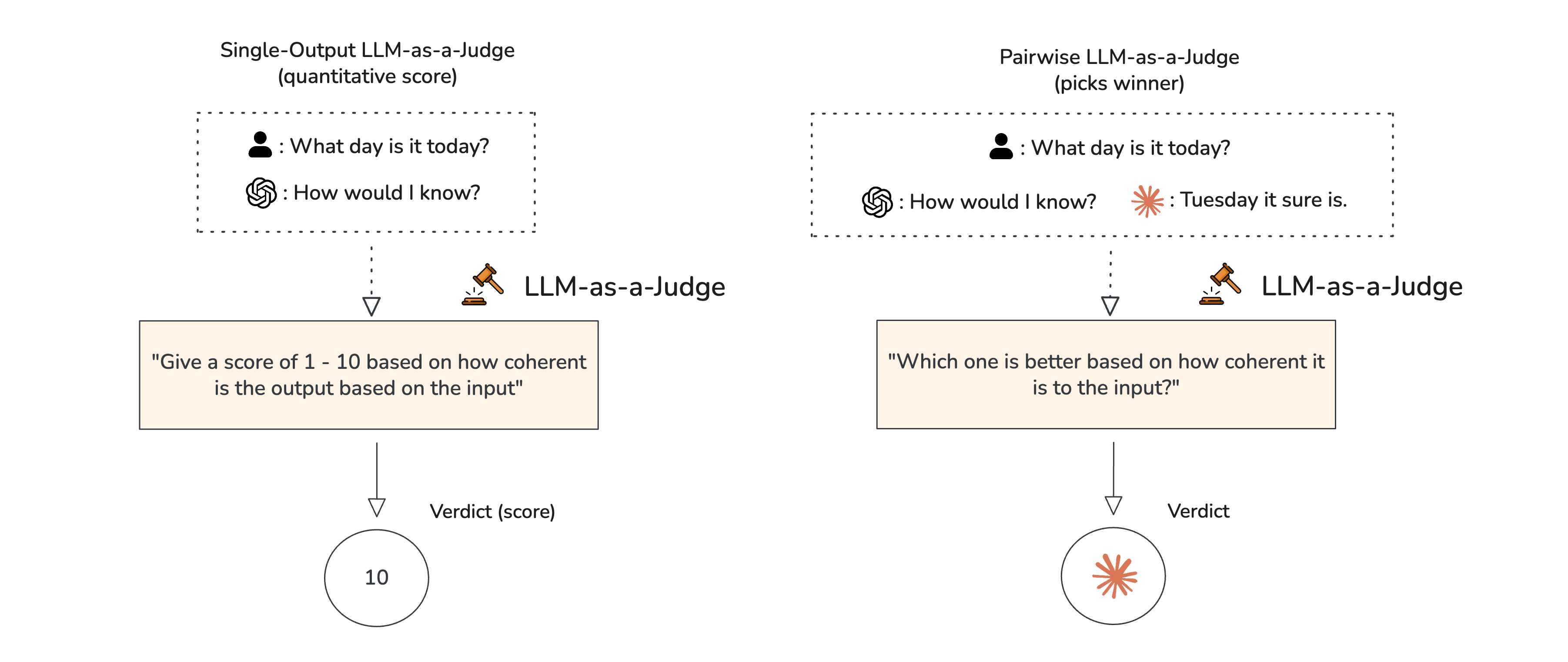
The primary result claimed is performance matching that of LLM-as-a-Judge. While the tweet does not provide specific benchmark numbers, the implication is clear: for many evaluation tasks, the expensive reasoning capacity of a frontier LLM is not necessary. A well-trained, smaller model can approximate the judgment function with high fidelity.
The practical impact is on cost and scalability. If an LLM-as-a-Judge call costs ~$0.01-$0.10 per evaluation, running millions of evaluations during model development or A/B testing becomes prohibitively expensive. A BERT-based judge, running on commodity hardware, could reduce this cost by 100x or more, removing a major barrier to iterative experimentation and robust evaluation.
gentic.news Analysis
This development is a direct response to a clear pain point in the LLM development lifecycle, which we highlighted in our December 2025 analysis, The Hidden Tax of LLM Evaluation. As models proliferate, the community has been grappling with the unsustainable economics of using GPT-4 as a universal benchmark. BERT-as-a-Judge represents a pragmatic shift towards specialized evaluation models, a trend gaining momentum alongside tools like MT-Bench and AlpacaEval.
The choice of BERT is strategically interesting. While newer, more powerful small models exist (like recent compact transformers from Google or Meta), BERT's architecture is deeply understood, widely deployed, and has a massive existing ecosystem for efficient inference. This work essentially repurposes a previous-generation SOTA model into a critical infrastructure component for the current generation, a clever piece of technical arbitrage.
However, a key question remains about the ceiling of this approach. The BERT judge's knowledge is distilled from the LLM judge, so it may inherit and even amplify its biases or blind spots. It is likely best suited for well-defined, domain-specific evaluation tasks rather than open-ended, creative generation assessment. This aligns with the broader industry trend we're tracking: the move from monolithic evaluation to a portfolio of targeted, cost-optimized metrics. For most practical development workflows, a suite of specialized judges—like BERT for factual consistency, a smaller seq2seq model for fluency, and a rule-based checker for safety—will likely replace the single, expensive LLM judge.
Frequently Asked Questions
What is LLM-as-a-Judge?
LLM-as-a-Judge is a common evaluation paradigm where a powerful, off-the-shelf large language model (like GPT-4 or Claude) is prompted to assess the quality of another model's output. It's used for tasks like judging dialogue helpfulness, code correctness, or summarization quality, but it is computationally expensive due to the size of the judge model.
How much cheaper is BERT-as-a-Judge?
While exact figures depend on deployment, a BERT-base model has about 110 million parameters versus a GPT-4-class model with over a trillion. In practice, this translates to inference that is potentially 100 to 1000 times cheaper, moving evaluation cost from a significant line item to nearly negligible for many research and development teams.
Can BERT-as-a-Judge evaluate any type of LLM output?
Not necessarily. Its effectiveness is tied to the quality and scope of its training data. It will perform best on evaluation tasks similar to what it was trained on (e.g., judging single-turn Q&A). For highly complex, multi-faceted, or novel tasks outside its training distribution, a more capable LLM judge may still be required.
Where can I find the code for BERT-as-a-Judge?
The model and methodology are likely detailed in the accompanying research paper linked from the tweet. Given the source is @HuggingPapers, the implementation is almost certainly intended for release on the Hugging Face Hub, allowing practitioners to fine-tune and deploy their own BERT judges easily.







