As large language model (LLM)-based agentic systems rapidly proliferate across industries—from automated customer service to complex research assistance—a critical question has emerged: how do we properly evaluate these sophisticated systems? According to a new research paper published on arXiv, titled "MASEval: Extending Multi-Agent Evaluation from Models to Systems," the AI community has been measuring the wrong things.
The Evaluation Gap in Multi-Agent AI
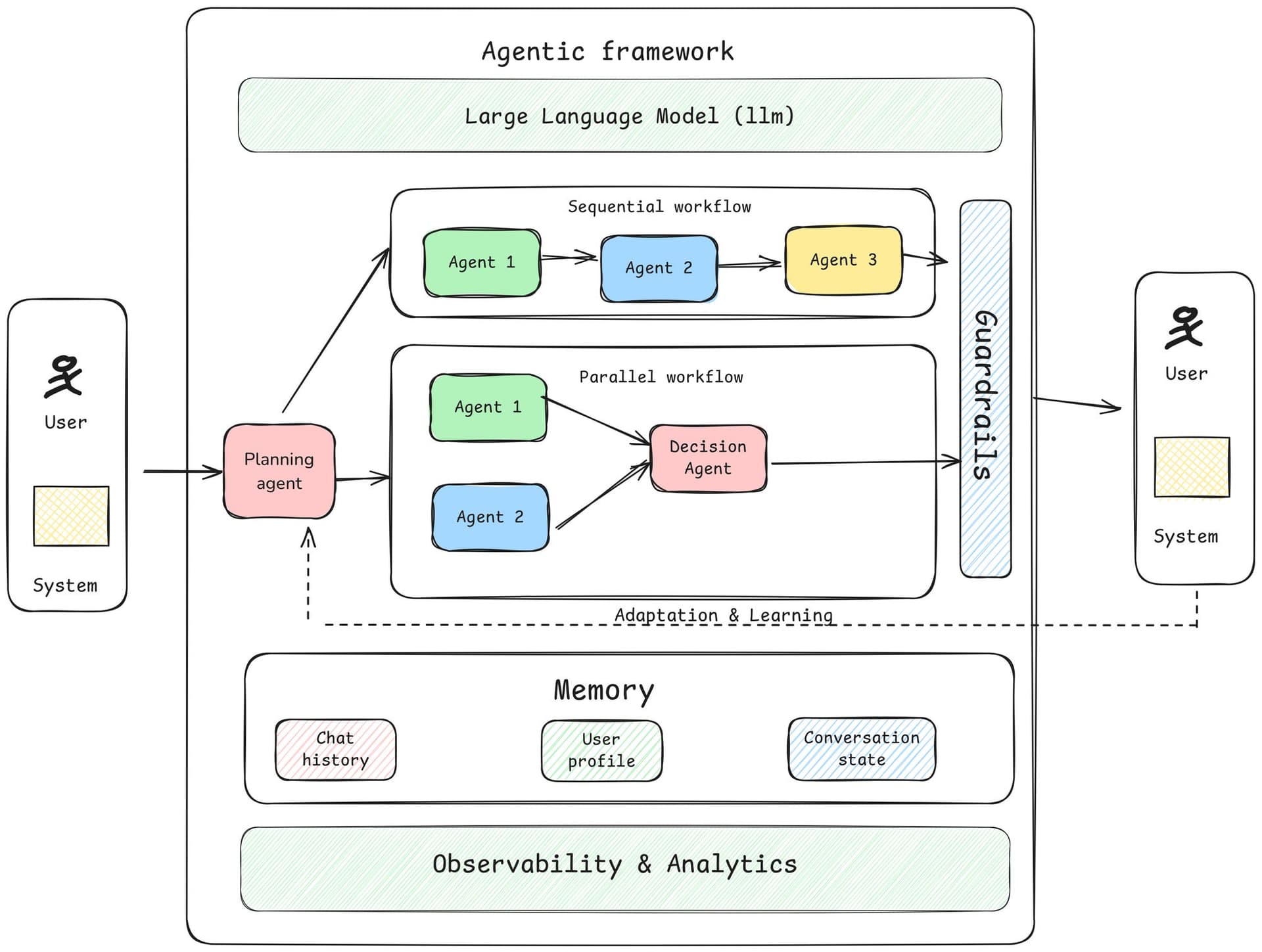
Traditionally, AI benchmarks have been model-centric. They test the raw capabilities of language models like GPT-4, Claude, or Llama by presenting them with standardized tasks while keeping the surrounding system architecture fixed. This approach, while useful for comparing foundational models, fails to capture the reality of how these models are actually deployed.
"The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks," the researchers note, listing popular tools including smolagents, LangGraph, AutoGen, CAMEL, and LlamaIndex. Yet existing benchmarks "fix the agentic setup and do not compare other system components."
This creates a significant blind spot. In practice, implementation decisions—what the researchers call "system components"—substantially impact performance. These include:
- Topology: How agents are connected and communicate
- Orchestration logic: The rules governing agent interactions and task delegation
- Error handling: How systems recover from failures or unexpected outputs
- Memory management: How context is maintained across interactions
Introducing MASEval: A System-Level Evaluation Framework
MASEval addresses this gap with a framework-agnostic library that treats the entire multi-agent system as the unit of analysis. Unlike traditional benchmarks that test models in isolation, MASEval evaluates complete implementations, allowing for apples-to-apples comparisons across different architectural choices.
The system is available under the MIT license on GitHub, making it accessible to both researchers and practitioners. Its design allows users to swap components systematically while measuring the impact on overall system performance.
Surprising Findings: Framework Choice Matters as Much as Model Choice
Through what the researchers describe as "a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks," they arrived at a striking conclusion: framework choice matters as much as model choice for overall system performance.
This finding challenges conventional wisdom in AI development, where teams often prioritize selecting the "best" language model while treating implementation details as secondary concerns. The research suggests that an optimal model paired with a suboptimal framework can underperform a moderate model with a well-designed system architecture.
Implications for AI Development and Deployment
The implications of this research extend across the AI ecosystem:
For Researchers
MASEval "opens new avenues for principled system design" by providing tools to explore all components of agentic systems systematically. This could accelerate innovation in multi-agent architectures, moving beyond incremental model improvements to holistic system optimization.
For Practitioners
Developers and organizations can use MASEval to "identify the best implementation for their use case" through empirical testing rather than guesswork. This is particularly valuable as companies face increasing pressure to deploy reliable, efficient AI systems in production environments.
For the Broader AI Landscape
This research arrives at a pivotal moment in AI development. Recent analysis (March 11, 2026) shows that compute scarcity makes AI expensive, forcing prioritization of high-value tasks over widespread automation. Understanding which system architectures deliver the best performance per computational dollar becomes increasingly critical.
Similarly, workplace research (March 9, 2026) reveals that AI creates a workplace divide, boosting experienced workers' productivity while potentially blocking hiring of young talent. More efficient agent systems could help bridge this gap by making powerful AI tools more accessible across experience levels.
The Future of AI Evaluation
MASEval represents a paradigm shift in how we think about AI capabilities. Rather than viewing performance as primarily determined by model parameters and training data, it acknowledges that implementation matters—sometimes as much as the underlying technology.
This aligns with broader trends in AI research emerging from arXiv publications, including work on verifiable reasoning frameworks for LLM-based recommendation systems (March 10, 2026) and advances in multi-modal encoders for image-based shape retrieval (March 10, 2026). Together, these developments point toward more sophisticated, holistic approaches to AI system design and evaluation.
As agentic systems become increasingly complex—handling everything from scientific research to creative collaboration—tools like MASEval will be essential for ensuring these systems are not just powerful in theory but effective in practice. The era of evaluating AI models in isolation may be coming to an end, replaced by a more nuanced understanding of complete intelligent systems.
Source: "MASEval: Extending Multi-Agent Evaluation from Models to Systems" (arXiv:2603.08835v1, March 9, 2026)








