A new research paper introduces Brittlebench, a theoretical framework and evaluation pipeline designed to quantify the brittleness of large language models—their sensitivity to semantics-preserving variations in prompts. The work, published on arXiv, argues that current static benchmarks overestimate real-world performance by failing to account for the noise and variability in human-generated queries.
What the Researchers Built
The core contribution is a framework that disentangles two sources of variance in LLM evaluations: data-induced difficulty (the inherent challenge of a task) and prompt-related variability (how a model's performance fluctuates based on how a question is phrased, even when the meaning is unchanged). The researchers define this sensitivity as brittleness.
To measure it, they built the Brittlebench pipeline. It applies controlled, semantics-preserving perturbations to established benchmark datasets. These perturbations mimic real-world imperfections like:
- Minor typos or grammatical errors
- Alternative phrasings of the same question
- Changes in punctuation or formatting
- Synonym substitution
The pipeline then measures the variance in model performance across these perturbed versions of the same underlying task.
Key Results
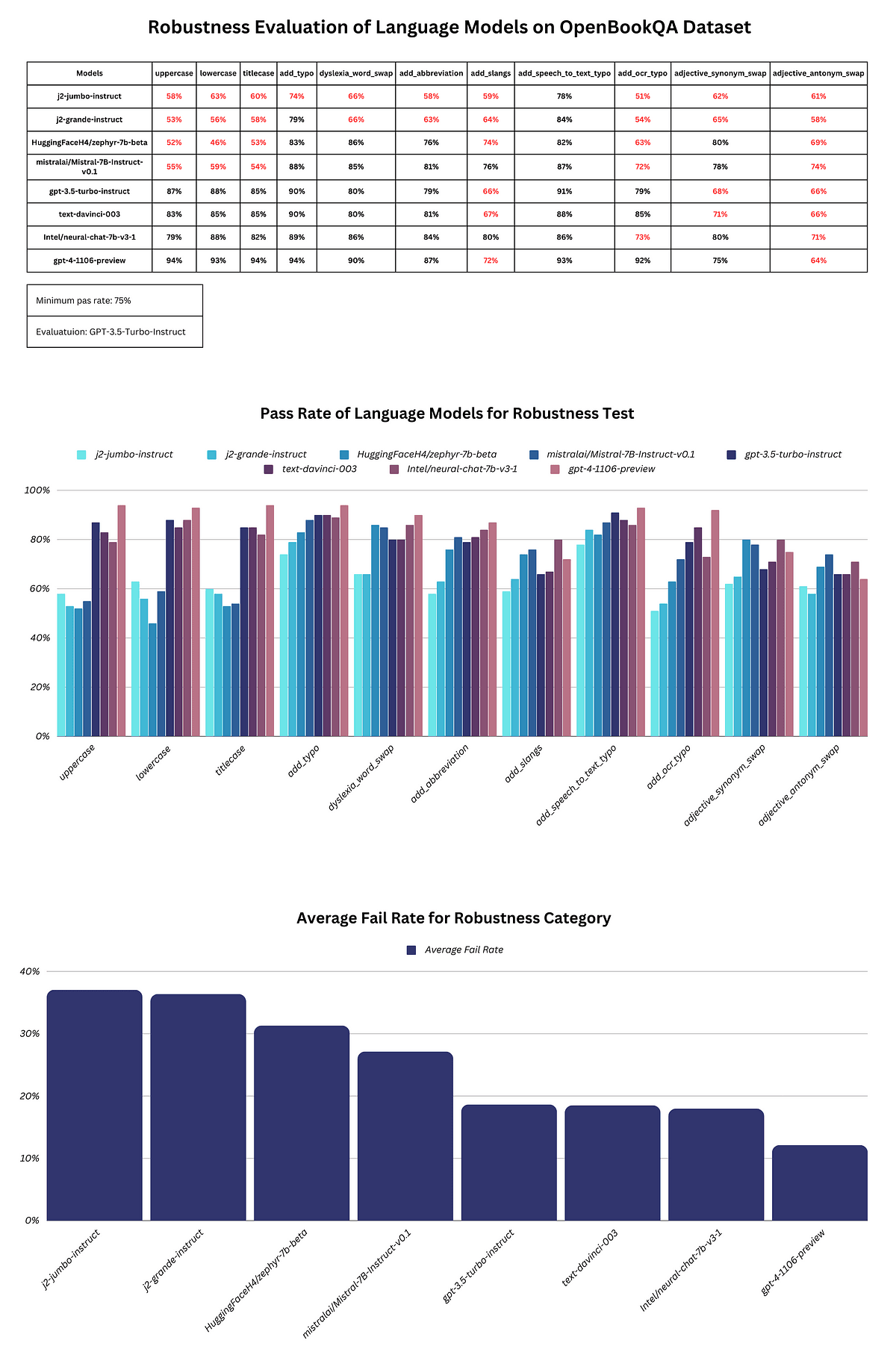
The researchers applied Brittlebench to evaluate both state-of-the-art open-weight and commercial frontier models. The results reveal significant brittleness across the board.

The 12% degradation is not uniform; some models and tasks are far more sensitive than others. The finding that over half of performance variance can be attributed to prompt phrasing—not task difficulty—challenges the stability of current leaderboards.
How It Works
The Brittlebench methodology involves several steps:

- Benchmark Selection: The pipeline starts with established benchmarks (e.g., MMLU, HellaSwag, GSM8K).
- Perturbation Generation: For each prompt in the benchmark, the system generates multiple variants that preserve semantic meaning. This is done through a rule-based and model-assisted approach to ensure the core query is unchanged.
- Model Evaluation: Multiple LLMs are evaluated on both the original and perturbed versions of the benchmark.
- Variance Decomposition: Using their theoretical framework, the researchers decompose the total variance in scores into components attributable to (a) the model, (b) the task/data point, and (c) the prompt variant. The portion attributed to the prompt variant is the quantified brittleness.
This approach moves beyond single-score benchmarking to produce a robustness profile for each model.
Why It Matters
Brittlebench provides a necessary corrective to the current evaluation paradigm. Static benchmarks, while useful for controlled comparisons, create a false sense of stability. A model that scores 85% on a clean MMLU test might see its effective performance drop into the 70s when faced with the messy, varied inputs of real-world deployment.

The finding that model rankings flip in 63% of cases with minor perturbations is particularly consequential for both academic research and commercial model selection. It suggests that declaring a "winner" based on a narrow set of clean prompts is statistically fragile.
For practitioners, this work underscores the importance of stress-testing models with varied prompts before deployment. For researchers, it provides a formal framework and tool (Brittlebench) to measure and report robustness alongside accuracy, pushing the field toward models that are not just capable, but also reliable.