Key Takeaways
- The source is a technical article outlining how to construct a full fraud detection pipeline within the Snowflake Data Cloud.
- It leverages Snowflake's native tools—Snowflake ML, the Model Registry, and ML Observability—alongside XGBoost to go from raw transaction data to a production-scoring system with monitoring.
What Happened
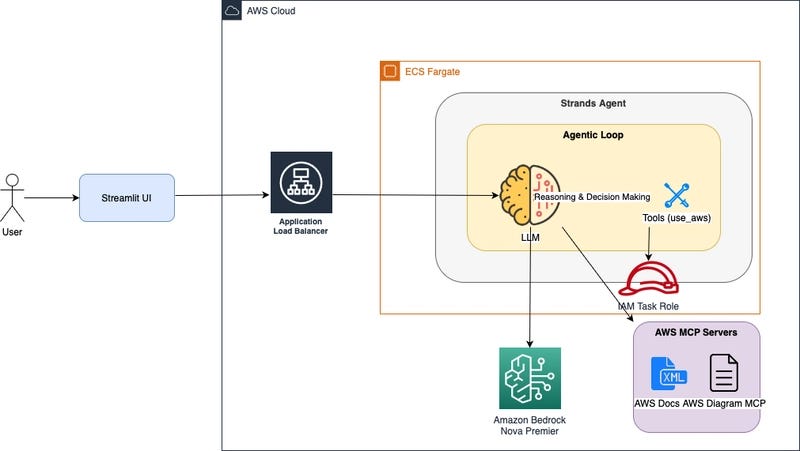
The source material is a technical guide published on Medium, detailing a step-by-step methodology for constructing a production-grade fraud detection system entirely within the Snowflake Data Cloud. The article's premise is to demonstrate how modern data platforms can consolidate the entire ML lifecycle—data engineering, feature engineering, model training, registry, deployment, and observability—into a single, governed environment. The specific tools highlighted are Snowflake ML (for in-database model training), the Snowflake Model Registry (for versioning and deployment), and integrated ML Observability features for monitoring model performance and data drift in production. The model of choice for this use case is XGBoost, a powerful and widely-used gradient boosting framework.
Technical Details
The guide implicitly walks through a canonical ML pipeline architecture, adapted for Snowflake's ecosystem:
- Data & Feature Engineering: All raw transaction data resides in Snowflake. Feature creation, including potentially sensitive aggregations and historical lookbacks, is performed using SQL or Snowpark (Snowflake's DataFrame API for Python, Scala, and Java), ensuring features are computed and stored within the platform's security and governance perimeter.
- Model Training with Snowflake ML: Instead of extracting data to an external system, the XGBoost model is trained directly on the data in Snowflake using the
snowflake.mlmodeling API. This eliminates data movement, maintains governance, and can leverage Snowflake's compute resources. - Model Registry & Deployment: The trained model is logged to the Snowflake Model Registry. This provides version control, lineage tracking, and a central catalog of approved models. Deployment for batch or real-time inference is managed through the registry, often by creating a user-defined function (UDF) that wraps the model for SQL-based scoring.
- ML Observability: Once deployed, the pipeline integrates with Snowflake's observability tools to monitor prediction logs, track key performance metrics (like accuracy or precision/recall for fraud), and detect drift in the input data or model predictions. This closed-loop monitoring is critical for maintaining a reliable production system.
The end result is a "pipeline" that is less a collection of disparate services and more a unified workflow defined and executed within a single platform.
Retail & Luxury Implications
While the article uses a generic fraud detection example, the architectural pattern it demonstrates has direct and powerful applications for luxury retail and fashion.
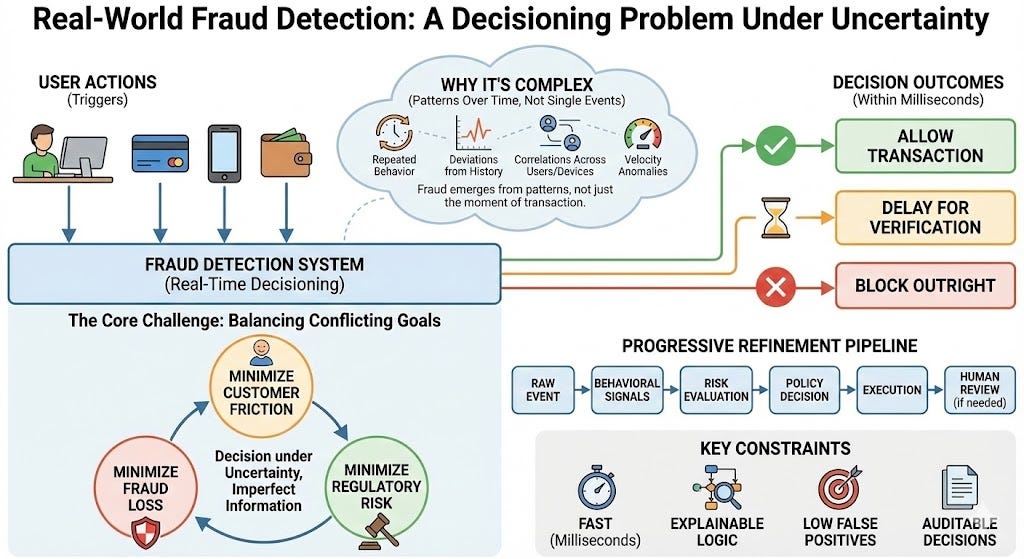
1. Payment & Transaction Fraud: This is the most direct application. High-value transactions in luxury e-commerce and brick-and-mortar (via integrated POS systems) are prime targets for fraud. A pipeline built as described can continuously score transactions in real-time, flagging suspicious purchases for review before fulfillment, thereby reducing chargebacks and protecting revenue.
2. Loyalty Program & Promotion Abuse: Fraud detection models can identify patterns of abuse in customer loyalty programs, such as the creation of fake accounts to harvest welcome bonuses or the systematic exploitation of promotional codes. Implementing this within the same data cloud that houses customer transaction histories allows for highly nuanced feature engineering.
3. Return Fraud and Wardrobing: A sophisticated application involves analyzing return patterns to identify "wardrobing" (purchasing for a single event with intent to return) or organized return fraud rings. By building features around customer return history, product categories, and time-to-return, models can identify high-risk returns for additional inspection.
4. Operational Benefits: The core value proposition for a luxury brand is the consolidation of a high-stakes ML use case within their existing Snowflake data estate. It simplifies governance (data never leaves the platform), accelerates development by reducing the need to integrate multiple point solutions, and leverages existing investments in data engineering and security. For technical leaders, it represents a pragmatic path to operationalizing AI that aligns with data platform strategy.