ByteDance has introduced OmniShow, a new AI research framework designed as an "all-in-one" system for generating videos of human-object interactions. The core innovation is its ability to harmonize and jointly condition video synthesis on four distinct input modalities: text descriptions, reference images, audio clips, and human pose data. This unified approach aims to move beyond models specialized for a single type of conditioning, offering a more flexible tool for content creation.
Key Takeaways
- ByteDance introduced OmniShow, a unified multimodal framework for video generation that accepts text, reference images, audio, and pose inputs simultaneously.
- It claims state-of-the-art performance across diverse conditioning settings.
What the Framework Does

OmniShow is specifically architected for Human-Object Interaction (HOI) Video Generation. This task involves creating realistic, short video clips depicting a person interacting with an object (e.g., "a person pouring wine from a bottle," "someone playing a guitar"). The challenge is maintaining temporal coherence, physical plausibility, and fidelity to the often complex and multi-faceted user intent.
Traditionally, video generation models are built and optimized for one or two conditioning signals—like text-to-video or image-to-video. OmniShow proposes a single model that can accept any combination of its four supported inputs:
- Text: Natural language descriptions of the action and scene.
- Reference Image(s): One or more images to define appearance, style, or specific objects/people.
- Audio: A sound clip (e.g., guitar strumming, pouring sound) to synchronize with the visual action.
- Pose: Skeletal keypoint sequences to precisely control human motion.
The framework's stated goal is to achieve "state-of-the-art performance across diverse conditioning settings," implying it can match or exceed the output quality of models that are experts in just one modality.
Technical Implications & The Unified Approach
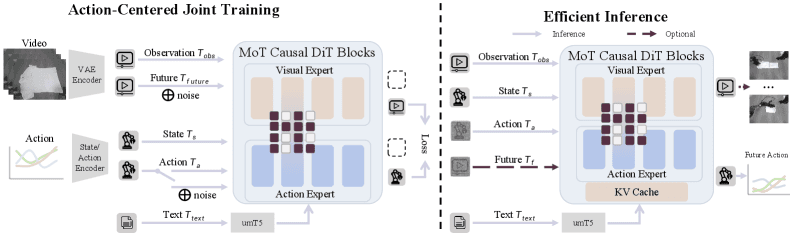
Building a model that effectively fuses such heterogeneous signals is a significant technical hurdle. Text is discrete and semantic, images are spatial, audio is a 1D temporal signal, and pose is a structured 2D temporal sequence. OmniShow's architecture likely involves separate encoders for each modality, projecting all inputs into a shared latent space that a diffusion-based or transformer-based video decoder can use for generation.
The "unified" claim is its main selling point. For practitioners, this could simplify pipelines. Instead of chaining together a pose generator, an audio-syncer, and a video renderer, one model could theoretically handle it all, potentially improving coherence and reducing error propagation. The research focus on HOI suggests the model incorporates strong priors about human physics and object affordances.
Market & Competitive Context
ByteDance's release of OmniShow places it directly in the rapidly advancing field of conditional video generation, competing with work from OpenAI (Sora), Google (Veo, Lumiere), Meta, and startups like Runway and Pika Labs. While Sora and Veo have showcased impressive breadth, OmniShow's explicit, fine-grained control over four modalities—especially the inclusion of audio and pose—targets a specific, professional use case: generating precise, actionable video clips for content, prototyping, or simulation.
This move aligns with ByteDance's broader investment in generative AI for its social and entertainment platforms (TikTok, Douyin). High-quality, controllable video generation tools could power next-generation content creation features for its massive creator ecosystem.
Limitations & Open Questions

The announcement, via a social media post from a research aggregator, is light on technical details. Critical information is missing:
- Architecture & Training Data: The model size, base architecture (e.g., Diffusion Transformer), and the scale/composition of the training dataset are not specified.
- Benchmarks: Claims of "state-of-the-art performance" are not yet backed by published quantitative results on standard benchmarks (e.g., UCF-101, Kinetics, or a dedicated HOI dataset). The metrics used (FVD, IS, user preference) and comparisons to models like Stable Video Diffusion, ModelScope, or Show-1 are absent.
- Resolution & Length: The output video resolution, frame rate, and maximum generation length are unknown.
- Access: There is no indication of whether the model weights, code, or a demo will be publicly released or if it remains an internal research project.
Until a full research paper is published, OmniShow should be viewed as an interesting and ambitious technical direction from a major AI lab, rather than a verified new state-of-the-art.
gentic.news Analysis
OmniShow represents a clear trend in generative AI research: the shift from unimodal to natively multimodal foundation models. This follows the trajectory set by large language models (LLMs) that incorporated vision (GPT-4V, Gemini) and audio (Voice Engine). ByteDance is applying this unified philosophy to the video generation domain, which is inherently multimodal.
Technically, the most significant challenge OmniShow must address is modality alignment. It's not enough to simply encode four inputs; the model must learn deep correlations—for instance, that a specific pose sequence aligns with a particular audio waveform and a text description. This requires massive, meticulously curated multi-modal video datasets, an area where ByteDance's access to TikTok's video corpus could be a formidable advantage, similar to how Google leverages YouTube for video model training.
In the competitive landscape, this is a strategic move. While OpenAI's Sora focuses on breathtaking fidelity and narrative length, and Runway on artist-friendly tools, ByteDance is targeting precision control for specific actions. This is highly valuable for practical applications in e-commerce (showing product use), education (demonstrating procedures), and social media content (creating templated, synchronized clips). If the technical claims hold, OmniShow could become the go-to model for tasks requiring synchronized audio-visual-pose output, a niche not yet dominated by the current frontrunners.
Frequently Asked Questions
What is OmniShow by ByteDance?
OmniShow is a unified AI framework for generating videos of human-object interactions. It can create videos conditioned on a combination of four inputs: text prompts, reference images, audio clips, and human pose sequences, all within a single model.
How does OmniShow compare to OpenAI's Sora?
While both are video generation models, they emphasize different capabilities. Sora is known for generating highly realistic and imaginative minute-long videos from text prompts alone. OmniShow, based on current information, appears focused on shorter human-object interaction clips with much finer-grained, multi-modal control (audio, pose), potentially offering more precision for specific tasks rather than broad narrative generation.
Is OmniShow available to use publicly?
As of now, OmniShow has only been announced via a research summary. ByteDance has not released the model weights, source code, or a public API. Its current status is that of a research project, and availability will depend on whether ByteDance decides to open-source it or integrate it into its commercial products.
What are the main technical challenges of a model like OmniShow?
The primary challenges are modality alignment (ensuring the generated video correctly corresponds to all input signals simultaneously) and maintaining spatiotemporal coherence. The model must learn consistent mappings between text semantics, visual appearance from images, temporal rhythms from audio, and kinematic structures from pose data, all while producing physically plausible video frames.