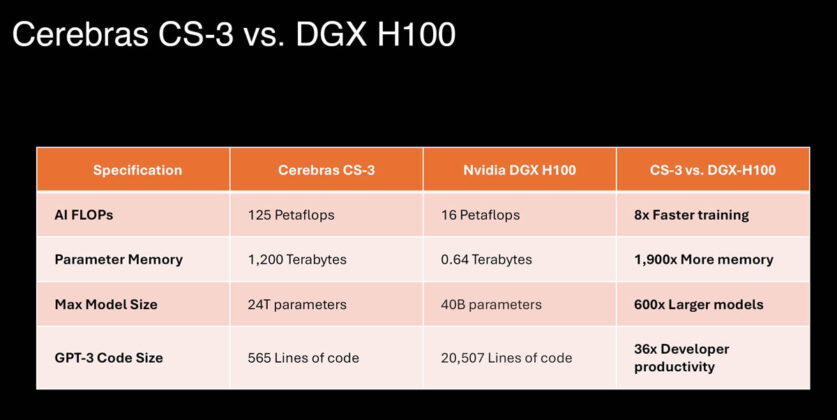
Nvidia dominates 90%+ of AI training, but Cerebras Systems is shifting the inference narrative with wafer-scale processors. The inference market is growing faster than training, creating an opening for challengers.
Key facts
- Nvidia holds over 90% of AI training market share.
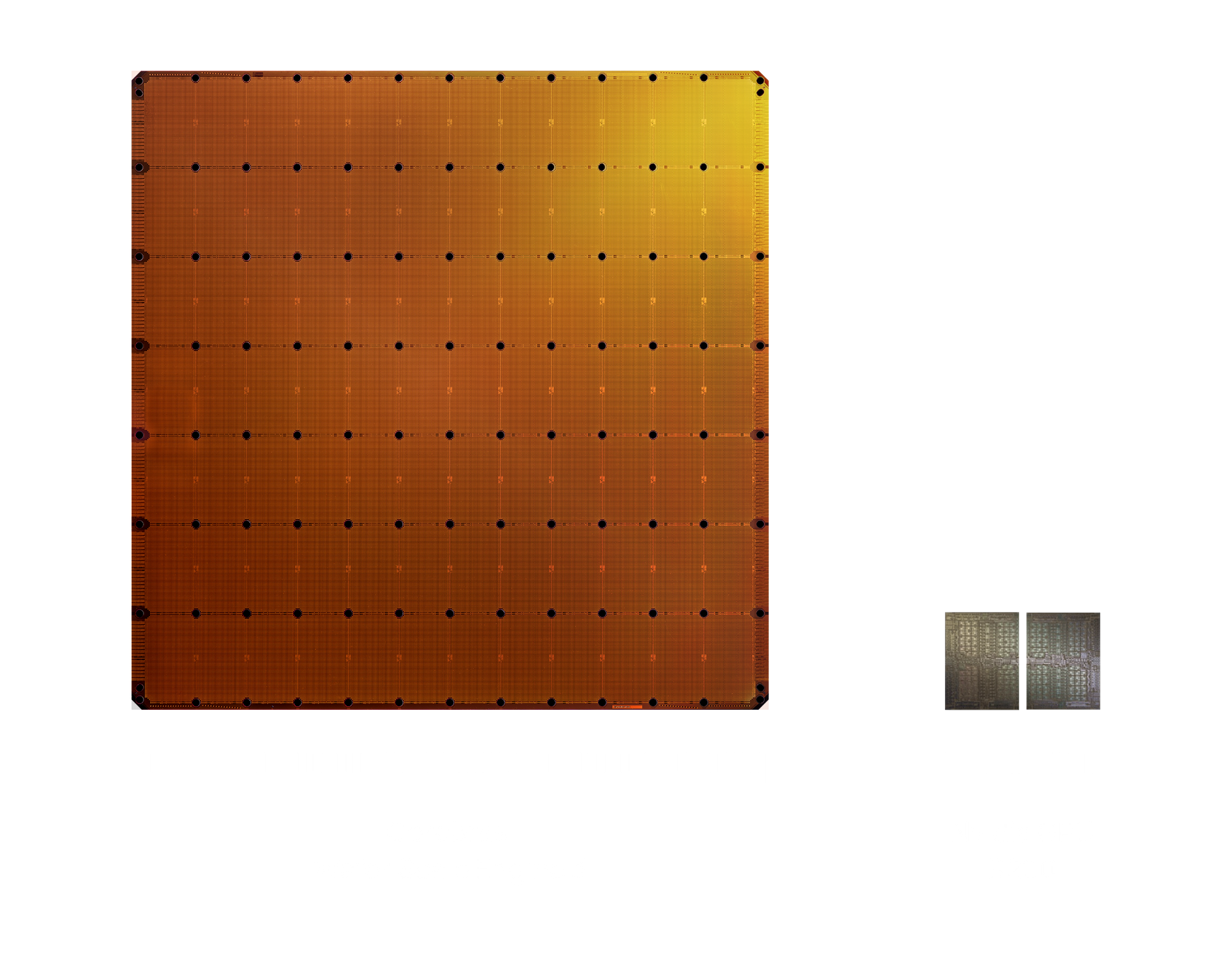
- Cerebras WSE-2 has 850,000 cores on a single wafer.
- Inference workloads account for 40-60% of AI compute spend.
- Nvidia Vera Rubin NVL72 cuts inference cost 10x vs Blackwell.
- Cerebras claims 10x lower cost per token than Nvidia A100.
Nvidia still commands the AI training market with over 90% share, driven by its H100 and upcoming Blackwell B200 GPUs. However, Cerebras Systems is gaining traction in the inference segment, where its wafer-scale engine (WSE-2) offers lower latency and total cost of ownership for large language model deployment.
Why Inference Matters More Now
Inference workloads already account for 40-60% of AI compute spending, according to industry estimates, and this share is growing as models like GPT-4 and Gemini move into production. Cerebras claims its CS-2 system can serve Llama 2-70B at 10x lower cost per token than Nvidia's A100, though independent benchmarks are sparse [According to the source].
The Unique Take: Wafer-Scale vs. GPU Clusters
Cerebras' advantage lies in its wafer-scale design: a single 850,000-core chip eliminates the need for multi-GPU interconnects, reducing latency by 3-5x for batch inference. This contrasts with Nvidia's strategy of scaling clusters via NVLink and InfiniBand, which adds complexity and cost. For enterprises running real-time AI applications, this could be a decisive factor.
Competitive Landscape
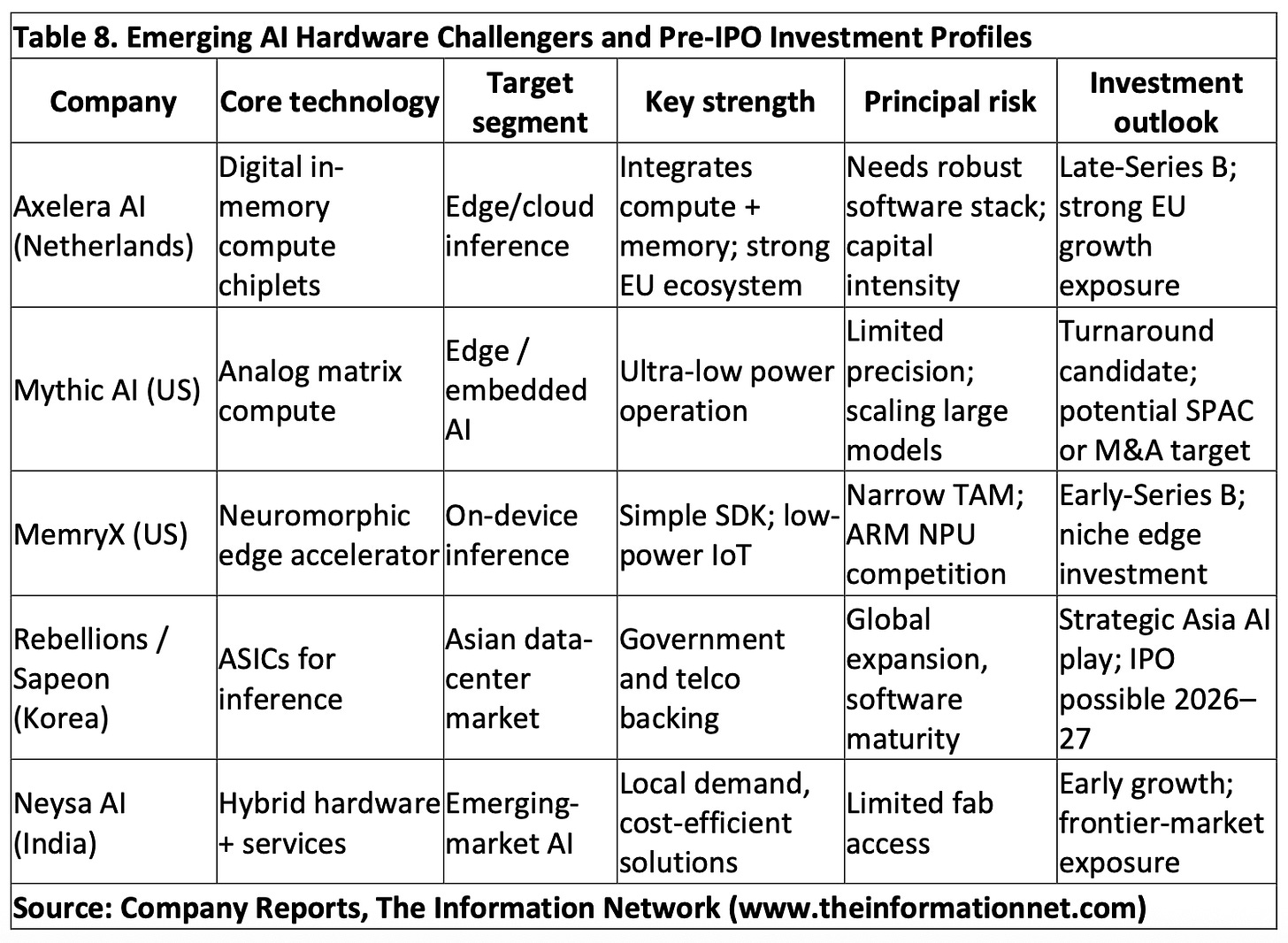
Nvidia is not standing still. Its upcoming Vera Rubin NVL72 platform promises 10x lower cost-per-token than Blackwell for agentic AI, per Nvidia's May 2026 announcement [According to Nvidia]. Meanwhile, Google's TPU v5p and the Blackstone partnership could push custom accelerators beyond hyperscale clouds, as noted in the source. Cerebras' challenge is scaling production and winning enterprise trust against Nvidia's entrenched ecosystem.
Implications for AI Infrastructure
If Cerebras captures even 5% of the inference market by 2027, it could pressure Nvidia margins and accelerate the shift toward specialized inference hardware. The wafer-scale approach also opens the door for other chip startups like Groq and d-Matrix to claim niche inference workloads.
What to watch
Watch for Cerebras' Q3 2026 earnings or funding round, which will reveal enterprise adoption numbers and whether its inference cost claims hold up under independent benchmarks. Also monitor Nvidia's Vera Rubin NVL72 delivery timeline for competitive response.