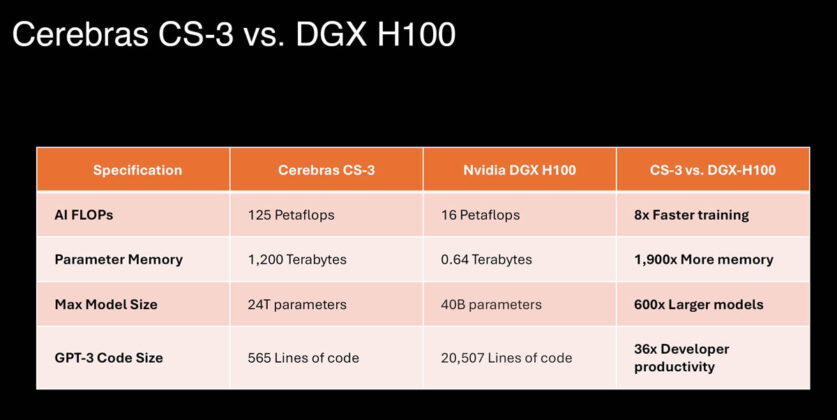
Cerebras Systems claims its Wafer Scale Engine 3 trains GPT-3-scale models 10x faster than Nvidia's H100 GPU cluster. The company cited a benchmark using a 175B-parameter model but did not disclose the exact training time or power consumption.
Key facts
- WSE-3 packs 4 trillion transistors on a single wafer
- H100 has 80 billion transistors per chip
- 10x speed claim targets 175B-parameter GPT-3 class models
- Nvidia shipped over 1 million H100s in 2025
- Cerebras did not disclose training time or power cost
Cerebras Systems published a benchmark [According to Cerebras vs Nvidia] asserting its Wafer Scale Engine 3 (WSE-3) delivers a 10x training speed advantage over Nvidia's H100 for models at the GPT-3 scale. The claim targets the 175B-parameter class, a size that requires thousands of GPUs interconnected via NVLink or InfiniBand. Cerebras did not release the exact training duration, power draw, or cost per training run — omissions that make independent verification difficult.
Key Takeaways
- Cerebras claims 10x training speed over Nvidia H100 for GPT-3-scale models using WSE-3.
- Benchmark lacks power and cost data, limiting independent verification.
The Wafer-Scale Bet

The WSE-3 packs 4 trillion transistors on a single 12-inch wafer, compared to Nvidia's H100 with 80 billion transistors per chip. By integrating compute and memory on one die, Cerebras eliminates the inter-chip communication overhead that plagues multi-GPU clusters. The company argues this reduces synchronization bottlenecks and enables near-linear scaling for large models. However, the WSE-3's single-wafer design limits its total memory bandwidth and forces customers to adopt specialized software stacks.
Nvidia's H100 remains the dominant training accelerator, with over 1 million units shipped in 2025 per market analysts. The H100's advantage lies in its mature ecosystem (CUDA, TensorRT, NCCL) and broad adoption by cloud providers like Google Cloud, AWS, and Azure. Cerebras has secured a smaller footprint, primarily in research labs and government contracts, including a partnership with the U.S. Department of Energy.
Unique Take: The Benchmark Gap
.webp)
The 10x claim, if validated, would upend the economics of large-scale training. A typical GPT-3 training run on 1,024 H100s costs roughly $4.6 million in compute time (based on public cloud pricing at $2.50 per GPU-hour). A 10x reduction would bring that to $460,000 — but only if Cerebras matches H100 power efficiency. The company's silence on power metrics is telling: wafer-scale chips run hot, and cooling costs could erode the speed advantage.
Cerebras' strategy mirrors its earlier WSE-2 claims, which independent benchmarks by MLCommons showed competitive but not category-dominating results. The WSE-3's real test will come when third parties reproduce the training run and publish power-to-performance ratios.
What to watch
Watch for third-party benchmarks from MLCommons or a published training run with full power and cost disclosure. If Cerebras ships to a major cloud provider (e.g., Google Cloud or AWS) and demonstrates sub-$500k training for a 175B model, the narrative shifts.