On April 14, Anthropic officially deprecated Claude Opus 4 and Claude Sonnet 4. Both models retire on June 15, 2026. After that date, every API request using claude-opus-4-20250514 or claude-sonnet-4-20250514 returns an error—no fallback, no grace period.
If you have production systems running on either model, you have exactly 60 days to migrate. Here's what changes, what breaks, and how to handle the transition without downtime.
Key Takeaways
- Anthropic is retiring Opus 4 and Sonnet 4 on June 15, 2026.
- Migrate to 4.6 models now to gain 1M context and higher output limits, but update your code for adaptive thinking and output_config changes.
What You Gain by Migrating to 4.6
The replacements are claude-opus-4-6 and claude-sonnet-4-6, released in February 2026. These aren't minor updates—they're substantially better for production work:
1M Context Window at Standard Pricing: Opus 4 and Sonnet 4 required a beta header and long-context pricing for 1M tokens. The 4.6 versions include it at standard pricing with no beta header. Requests over 200K tokens just work.
Higher Output Limits: Opus 4.6 supports 128K max output tokens (up from 32K). Sonnet 4.6 supports 64K. For code generation and structured data extraction, this is a 4x improvement on Opus and 2x on Sonnet.
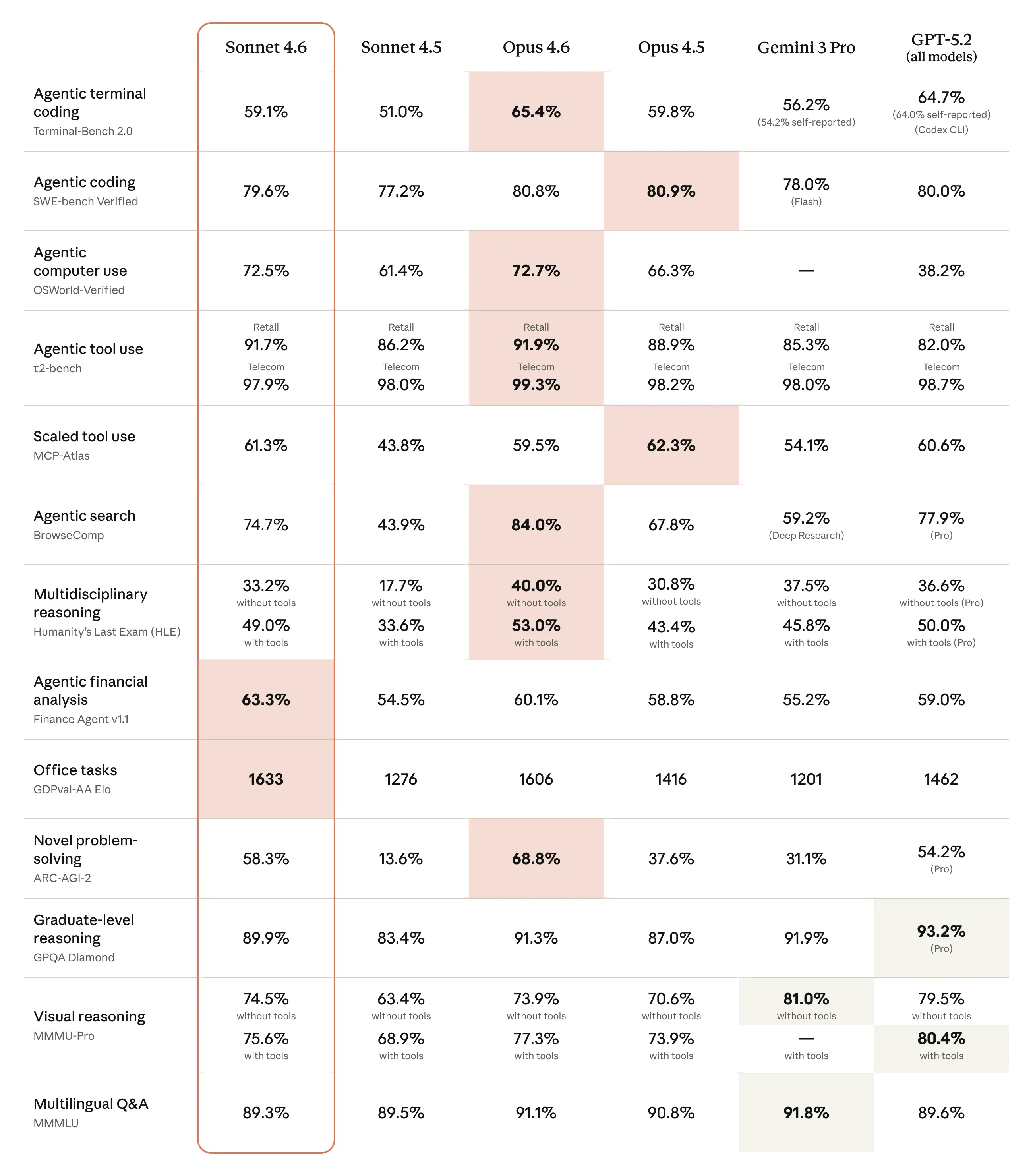
Better Coding Performance: Sonnet 4.6 scores 79.6% on SWE-bench Verified. Opus 4.6 scores 80.8%. For most coding tasks, the gap between the two is negligible.
300K Batch Output: The Message Batches API now supports up to 300K output tokens for both 4.6 models with the output-300k-2026-03-24 beta header.
What Breaks When You Switch
Not everything is drop-in replacement. Three changes require code modifications.
1. Adaptive Thinking Replaces budget_tokens
If you use extended thinking with Opus 4 and set budget_tokens manually, that parameter is deprecated on Opus 4.6. The recommended approach is:
# Old (Opus 4)
response = client.messages.create(
model="claude-opus-4-20250514",
thinking={"type": "enabled", "budget_tokens": 8192},
max_tokens=4096,
messages=[{"role": "user", "content": "Analyze this code."}]
)
# New (Opus 4.6)
response = client.messages.create(
model="claude-opus-4-6",
thinking={"type": "adaptive"},
max_tokens=4096,
messages=[{"role": "user", "content": "Analyze this code."}]
)
Adaptive thinking means Claude decides whether to think and how much. For most workloads, this produces better results with fewer wasted tokens. If you need control, use the effort parameter ("low" | "medium" | "high") instead of raw token budgets.
2. No Assistant Message Prefilling (Opus Only)
Opus 4.6 does not support prefilling assistant messages. If your application starts Claude's response with specific text to guide output format, this won't work with Opus 4.6. Move that guidance into the system prompt or user message instead.
Sonnet 4.6 still supports prefilling, so this only affects Opus migrations.
3. output_format Moved to output_config.format
If you use structured outputs, the parameter location changed:
# Old
response = client.messages.create(
output_format={"type": "json", "schema": my_schema},
...
)
# New
response = client.messages.create(
output_config={"format": {"type": "json", "schema": my_schema}},
...
)
The old location still works during transition, but updating now prevents issues later.
Migration Checklist for Claude Code Users

Week 1: Audit
Find every place your codebase references the old model IDs. Check environment variables, configuration files, CI/CD pipelines, and hardcoded strings. Use the Console Usage page's Export button to see usage broken down by model.
Week 2: Test in Staging
Create a parallel test environment using the 4.6 models. Update your API calls with the breaking changes above. Pay special attention to:
- Any
budget_tokensparameters → change tothinking: {"type": "adaptive"} - Assistant message prefilling → move to system prompts
output_formatreferences → update tooutput_config.format
Week 3: Monitor and Optimize
With adaptive thinking, you might see different token usage patterns. Monitor your costs and adjust max_tokens if needed. Test the higher output limits—you can now generate much larger code blocks in single requests.
Week 4: Deploy
Roll out changes to production with proper monitoring. Have a rollback plan ready for the first 24 hours.
Immediate Action Items
- Update your Claude Code CLI config: If you have scripts using the old models, update them now.
- Check your CLAUDE.md files: If you specify model versions in prompts or system instructions, update them.
- Test long-context workflows: The 1M context at standard pricing means you can now upload entire codebases without special headers.
- Consider Sonnet for coding: With 79.6% SWE-bench score, Sonnet 4.6 might be cost-effective for many coding tasks where you previously used Opus.
gentic.news Analysis
This model retirement follows Anthropic's established pattern of deprecating older model versions with 60-day notice periods, similar to their previous Claude 3.5 Sonnet deprecation in late 2025. The move to adaptive thinking represents a significant shift in how developers interact with Claude's reasoning capabilities—moving from manual token budgeting to trust-based optimization.
The timing aligns with increased competition in the coding assistant space, where both OpenAI's o1 models and Google's Gemini 2.0 Flash have been pushing boundaries on coding benchmarks. Anthropic's decision to make 1M context standard pricing on both Opus and Sonnet directly responds to competitive pressure from models like GPT-4o's 128K context at lower price points.
For Claude Code users, this migration isn't just about avoiding errors—it's an opportunity to leverage substantially improved capabilities. The near-parity between Sonnet 4.6 and Opus 4.6 on coding tasks (79.6% vs 80.8% SWE-bench) suggests many developers could switch to Sonnet for routine coding work while maintaining quality, similar to the cost optimization strategies we discussed in "How to Cut Claude API Costs 40% Without Sacrificing Quality."
The breaking API changes, particularly around thinking parameters, reflect Anthropic's confidence in their models' ability to self-regulate reasoning depth—a trend we're seeing across the industry as models become more sophisticated. Developers who adapt quickly will benefit from both performance improvements and potentially lower costs through more efficient token usage.