Anthropic has released Claude Opus 4.7, a significant iteration of its flagship model that delivers targeted improvements for enterprise and developer use cases. Available immediately across the API, AWS Bedrock, Google Vertex AI, and Microsoft Foundry at the same pricing as Opus 4.6 ($5/$25 per million tokens), the update focuses on three core areas: agentic coding reliability, high-resolution vision for computer-use agents, and performance on economically valuable knowledge work.
Key Takeaways
- Anthropic launched Claude Opus 4.7 today with 3x higher vision resolution (3.75MP), self-verifying coding outputs, and stricter instruction following.
- The update targets enterprise agentic workflows and knowledge work benchmarks.
What's New: Features Targeting Production Workflows

The release introduces several new capabilities and refinements designed for real-world deployment.
Enhanced Vision for Computer-Use Agents:
Claude Opus 4.7 now accepts images with a long edge of up to 2,576 pixels (~3.75 megapixels), a more than 3x increase over any prior Claude model. This resolution bump is specifically highlighted as "the real unlock" for agents that need to parse dense screenshots, user interfaces, and extract information from complex diagrams—a critical capability for automation and RPA-style workflows.
Self-Verifying Coding & Agentic Reliability:
The model shows its "biggest gains on the hardest, long-horizon software engineering tasks." Early testers report being able to hand off work that previously required close supervision, as Opus 4.7 now verifies its own outputs before reporting back. This represents a shift toward more autonomous and reliable coding agents.
Stricter Instruction Following:
A notable change is in instruction interpretation. Anthropic states Opus 4.7 now "interprets instructions literally" and explicitly warns that "prompts tuned for 4.6 may break or produce unexpected output." This suggests a move away from the model making assumptions or "helpful" corrections, requiring existing implementations to be re-tuned for deterministic behavior.
New Control Features:
xhighEffort Level: A new reasoning effort level betweenhighandmaxprovides finer control over the trade-off between output quality and latency. Claude Code's default is nowxhighfor all plans./ultrareviewin Claude Code: A dedicated review session that flags bugs and design issues. Pro and Max users get three free uses.- Auto Mode for Claude Code Max: Extended to Max users, allowing Claude to decide on tool use autonomously, reducing workflow interruption.
- Task Budgets (Public Beta): New API feature for managing computational costs.
Technical Details & Caveats
New Tokenizer: A significant under-the-hood change is a new tokenizer. The same input text now maps to 1.0 to 1.35x more tokens depending on content type, which could impact effective pricing and context window usage for some applications.
Performance & Cost: At higher effort levels, especially in multi-turn agentic conversations, "Opus 4.7 thinks more," leading to increased output tokens. Users should monitor usage patterns.
Safety & Capability Positioning:
The safety profile is described as "roughly similar to 4.6," with improvements in honesty and prompt injection resistance, but a modest weakening in "over-detailed harm-reduction advice for controlled substances." Anthropic is clear that Opus 4.7 is "still less capable than Claude Mythos Preview," which remains on limited release. Opus 4.7 serves as a testbed for the cybersecurity safeguards needed before a broader Mythos rollout.
Benchmark Leadership:
The model achieves state-of-the-art results on the Finance Agent evaluation and GDPval-AA, a third-party benchmark measuring economically valuable knowledge work across finance, legal, and other professional domains.
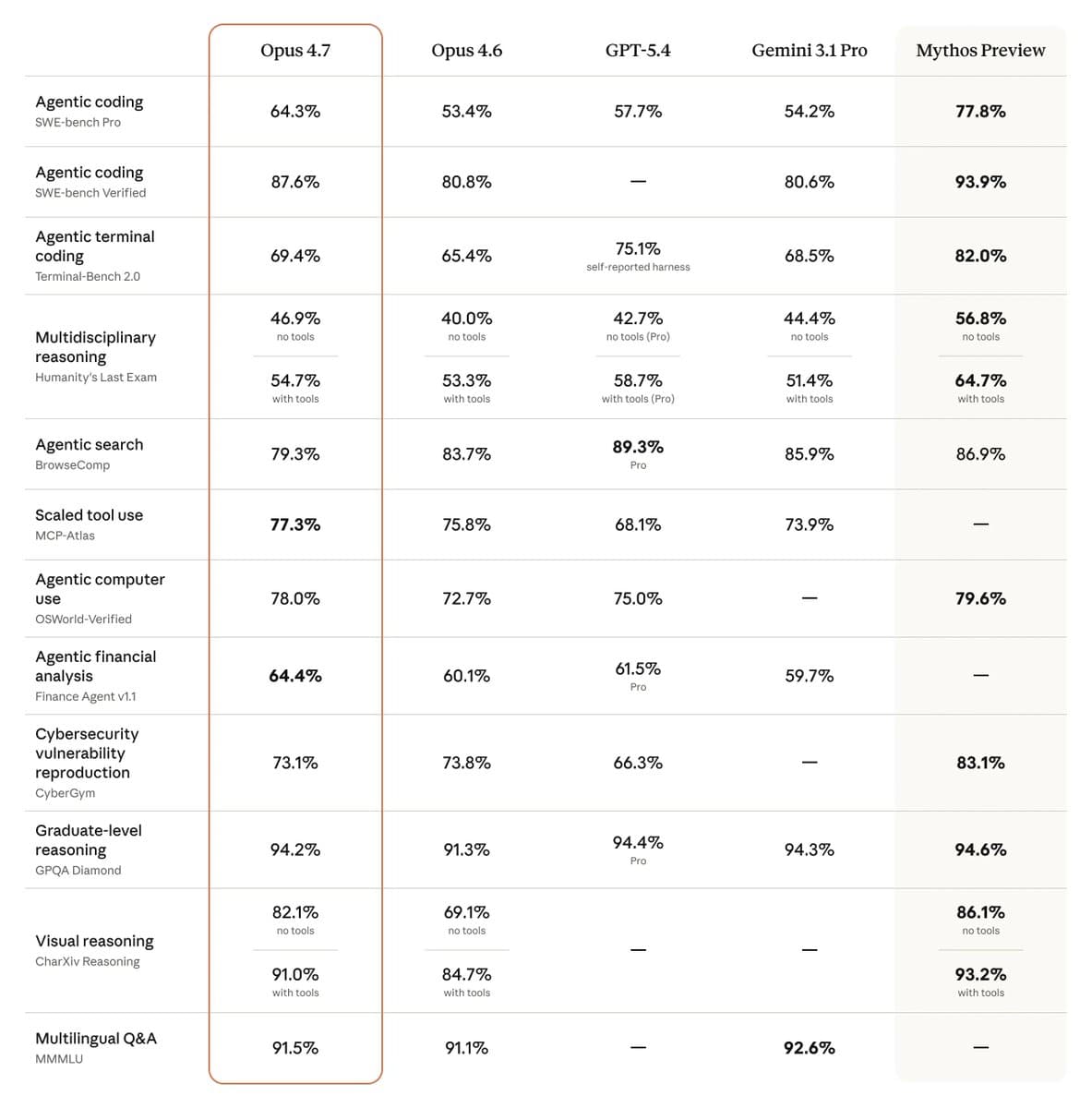
How It Compares: Opus 4.7 vs. The Field

gentic.news Analysis
This release is a classic Anthropic move: a substantial, engineering-focused iteration that directly addresses the friction points of its core enterprise and developer user base. The tripling of vision resolution isn't a flashy multimodal feature for consumers; it's a pragmatic unlock for agents that need to "see" and interact with software UIs—a growing segment in enterprise automation. The self-verifying coding output is perhaps the most significant shift, moving from a model that generates code to one that engineers code with a built-in quality check. This directly reduces the human-in-the-loop burden, which is the primary cost in agentic workflows.
The stricter instruction following and new tokenizer, however, are double-edged swords. The former will force a recalibration of carefully tuned production pipelines, causing short-term pain for long-term predictability—a trade-off enterprises often accept. The new tokenizer, increasing token counts by up to 35%, effectively introduces a silent price hike for certain content. This follows a pattern we've noted in our coverage of model evolutions, where architectural improvements for performance (like better non-English language handling) can negatively impact token efficiency. It's a reminder that total cost of inference is a multi-variable equation beyond just price-per-million-tokens.
Strategically, positioning Opus 4.7 as the testbed for Mythos's cybersecurity safeguards is telling. It confirms our analysis from Anthropic's previous Mythos Preview announcement that the company is taking a deliberately cautious, staged rollout for its most powerful models, prioritizing safety and deployment infrastructure over raw speed-to-market. This release solidifies Opus as the workhorse for today's practical AI applications, while Mythos remains the frontier model for tomorrow's possibilities.
Frequently Asked Questions
What is the main reason to upgrade from Claude Opus 4.6 to 4.7?
The primary reasons are if your application relies heavily on computer vision for parsing screenshots/diagrams (3x resolution boost) or requires more reliable, autonomous coding agents (self-verifying outputs). For general chat or creative writing, the benefits may be less pronounced, and the need to re-tune prompts for stricter instruction following should be factored in.
How does the new tokenizer affect my API costs?
Your cost per million tokens remains the same, but because the same input text may be tokenized into 1.0 to 1.35 times more tokens, your effective cost per word or character could increase by up to 35%, depending on your content type. You should monitor your token usage after switching to assess the impact on your specific use case.
Is Claude Opus 4.7 now better than Claude Mythos?
No. Anthropic explicitly states Opus 4.7 is "still less capable than Claude Mythos Preview." Mythos remains a separate, more powerful model on limited release. Opus 4.7 is incorporating some of the safety and infrastructure learnings that will eventually enable a wider Mythos rollout.
Do I need to change my prompts for Claude Opus 4.7?
Yes, likely. Anthropic warns that Opus 4.7 interprets instructions more literally, so prompts engineered or tuned for the behavior of Opus 4.6 "may break or produce unexpected output." Existing production harnesses and agent frameworks will need testing and potentially significant re-tuning to work as expected with the new model.







