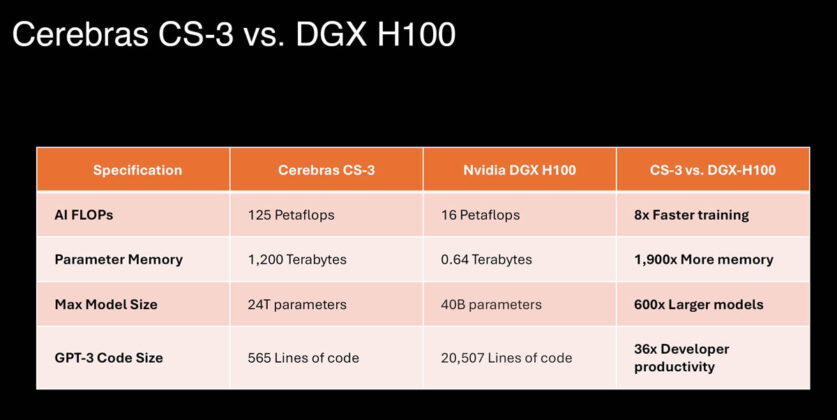
A stark cost analysis is circulating among AI engineers and founders, challenging the default assumption that cloud GPUs are the most economical path for running sustained AI workloads. The core argument is simple: at current cloud pricing, the cost of renting high-end AI accelerators can quickly surpass the outright purchase price of the hardware, making ownership via colocation a financially rational choice for many businesses.
Key Takeaways
- A technical founder highlights the stark economics: renting one H100 on Google Cloud costs ~$8,000/month, while the retail hardware is ~$30,000.
- At that rate, 4 months of cloud rental equals the cost of outright ownership, making colocation at ~$1k/month a compelling alternative for sustained AI workloads.
The Core Numbers: $8,000/Month vs. $30,000 Once
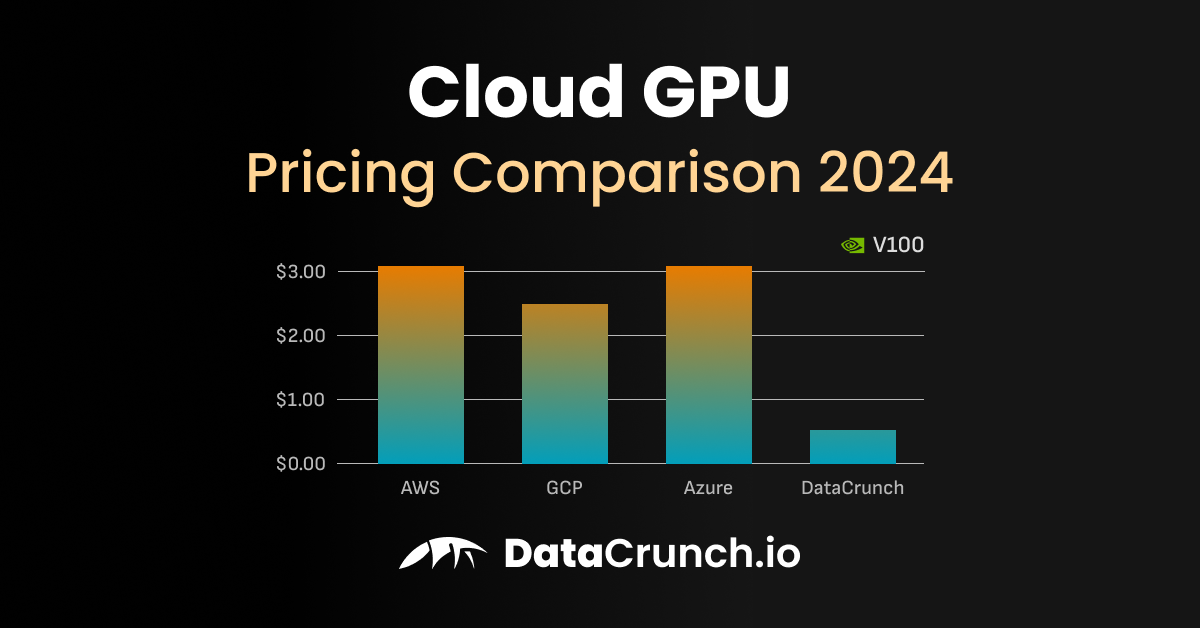
The comparison is drawn using NVIDIA's H100, a workhorse for training and inference of large models.
- Google Cloud H100 Rental: Approximately $8,000 per month.
- Retail H100 Purchase Price: Approximately $30,000 (market prices have fluctuated but this serves as a baseline).
The math is inescapable: $8,000/month * 3.75 months = $30,000. In under four months of continuous cloud rental, a company spends the equivalent of buying the GPU outright. After that point, every additional month of cloud usage is pure incremental cost, whereas owned hardware continues to operate with only minimal ongoing expenses.
The Ownership Alternative: Colocation ("Colo")
The primary barrier to ownership is not capital but infrastructure: housing, power, cooling, and networking for server-grade hardware. The proposed solution is colocation.
Colocation facilities rent physical rack space, power, cooling, and internet bandwidth. Customers install their own servers. For a single GPU server, colo costs can start around $1,000 per month, a fraction of the cloud rental fee for the same compute. This transforms the economic equation for any workload expected to run for more than a few months.
A Proposed Hardware Strategy for AI Workloads
The analysis extends beyond a single cost comparison to a proposed tiered strategy for deploying AI compute:
- Personal Use: Local, lower-power devices like Apple Mac Minis or Mac Studios running smaller, quantized models.
- Business - Initial Scale: Stacking Apple Silicon Mac Studios for a balance of performance and ease of management.
- Business - Sustained Scale: Owning dedicated GPU servers (e.g., with H100s or newer accelerators) housed in a colocation facility for maximum performance and long-term cost control.
The underlying thesis is a shift in focus: while the industry debates model architectures, a parallel critical decision is who owns the physical compute substrate. For businesses with predictable, persistent AI inference or training needs, the cloud's operational expense (OpEx) model may be significantly more expensive than the capital expense (CapEx) model of ownership.
gentic.news Analysis
This cost analysis isn't merely anecdotal; it reflects a growing undercurrent in the AI infrastructure space. For years, the cloud's elasticity and zero-maintenance appeal justified its premium. However, as AI workloads transition from experimental to production-critical and sustained, the total cost of ownership (TCO) calculus changes dramatically. This aligns with trends we've noted, such as the rise of specialized cloud alternatives like CoreWeave and Lambda Labs, which often offer more competitive pricing than hyperscalers for GPU instances, and the continued investment in on-premise AI clusters by large enterprises.
The argument also intersects with the evolving hardware landscape. The analysis mentions Apple Silicon, which has become a formidable platform for local inference thanks to its unified memory architecture. This creates a viable on-ramp: companies can prototype and run moderate-scale workloads on owned Mac hardware, then graduate to owned data-center GPUs in a colo only when necessary, avoiding cloud lock-in for their core IP.
If this economic logic gains traction, it could pressure hyperscalers to re-evaluate GPU instance pricing for long-term commitments. More importantly, it empowers startups and scale-ups to treat AI compute as a strategic asset rather than a pure utility, potentially altering the competitive dynamics where deep-pocketed players have dominated via cloud spending.
Frequently Asked Questions
How accurate is the $8,000/month figure for an H100 on Google Cloud?
The figure is a realistic estimate for a committed-use, high-availability H100 instance. Actual on-demand list prices can be higher, and discounts are available for long-term commitments (Committed Use Discounts, CUDs). However, even with significant CUDs, the monthly cost often remains high enough that the break-even point for ownership versus a 1-3 year commitment is measured in months, not years.
What are the hidden costs of owning GPUs in a colocation facility?
Beyond the colo monthly fee ($1k+), owners must account for the upfront server hardware cost (~$30k+ for an H100 system), setup/installation fees, remote hands services (if you need the colo staff to physically interact with your server), and potentially higher bandwidth costs. There's also the burden of system administration, maintenance, and the risk of hardware depreciation or failure. However, for a sustained workload, these costs are often dwarfed by the long-term savings versus cloud rental.
Is this strategy only for inference, or does it work for training too?
It applies powerfully to both, but the case is strongest for inference. Training jobs can be bursty and benefit from the cloud's elasticity to spin up hundreds of GPUs for a short time. However, for ongoing fine-tuning, continual learning, or companies that are constantly training models, the colocation model becomes increasingly compelling. The break-even timeline is simply a function of how many GPU-months you consume.
Doesn't this lock me into older hardware? What about upgrading?
This is a key consideration. Cloud providers continuously refresh their hardware. Owning hardware means you bear the cost and hassle of upgrades. The counter-argument is that for many production inference workloads, performance needs are stable. You can run a model efficiently on an H100 for years. When an upgrade is justified, you can sell the depreciated hardware and reinvest, often with a better overall TCO than years of cloud rental at the technological frontier's premium price.