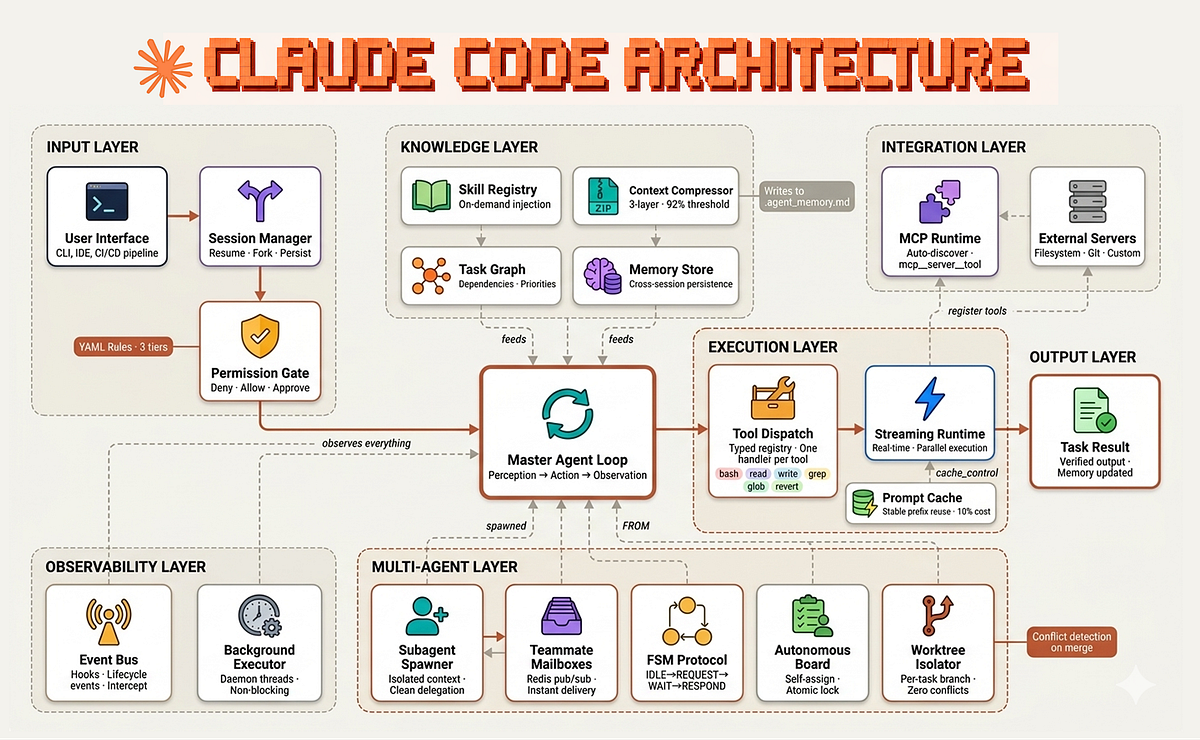
Canadian AI company Cohere has released Transcribe, a new open-source automatic speech recognition (ASR) model. The 2-billion parameter model claims the top spot on the Hugging Face Open ASR Leaderboard with an average word error rate (WER) of 5.42%, outperforming established competitors including OpenAI's Whisper Large v3, ElevenLabs Scribe v2, and Alibaba's Qwen3-ASR-1.7B. According to Cohere, Transcribe also delivers the best throughput among similarly sized models.
The model is available for download under the permissive Apache 2.0 license on Hugging Face and can be accessed via Cohere's API and the Model Vault platform. Cohere plans to integrate Transcribe into its AI agent platform, North, in the future.
What's New: A Performance-First Open-Source ASR Model
Transcribe is positioned as a high-performance, production-ready ASR model. Its primary claim is a combination of state-of-the-art accuracy and superior inference speed. The reported 5.42% average WER is a composite score across its supported languages. The model supports 14 languages: English, German, French, Japanese, Spanish, Italian, Portuguese, Dutch, Polish, Turkish, Russian, Arabic, Hindi, and Chinese.
Beyond raw accuracy, Cohere emphasizes throughput—the number of audio samples processed per second—as a key differentiator. In a benchmark plot provided by Cohere (models plotted with WER on the x-axis and throughput on the y-axis), Transcribe occupies the desirable upper-left quadrant, indicating low error and high speed.
Technical Details: Architecture, Licensing, and Access
- Model Size: 2 billion parameters.
- License: Apache 2.0 (open-source, commercially usable).
- Access Points:
- Hugging Face Hub: For direct download and local deployment.
- Cohere API: For managed, scalable inference.
- Model Vault: Cohere's platform for discovering and deploying open models.
- Supported Languages: 14 (see list above).
Cohere has not released detailed architecture papers or training dataset specifics with this initial announcement. The focus is on the reproducible benchmark results and immediate availability.
How It Compares: A New Leader on the Open ASR Board
The Hugging Face Open ASR Leaderboard provides a standardized comparison for speech recognition models. Transcribe's claimed 5.42% WER places it ahead of several notable models:
Cohere Transcribe (2B) Cohere 5.42% avg WER (Leaderboard #1), best-in-class throughput Whisper Large v3 OpenAI General-purpose, robust across accents and noise Qwen3-ASR-1.7B Alibaba Cloud Open-weight, part of the Qwen LLM family ElevenLabs Scribe v2 ElevenLabs Focus on high-fidelity transcription for creative/professional useThis represents a significant challenge to OpenAI's Whisper, which has been the de facto standard for open-source capable ASR since its release. The benchmark suggests Transcribe may offer a tangible accuracy and speed improvement for many use cases.
What to Watch: Integration and Real-World Performance
The announcement is light on training methodology and ablation studies. Practitioners will need to validate the benchmark claims across their own domain-specific audio (e.g., calls with heavy accents, technical jargon, or poor recording quality).
The planned integration into Cohere's North agent platform is a strategic move. It points to a future where high-quality, low-latency speech recognition is a native component of AI agents, enabling more natural voice interfaces. This follows a broader industry trend of bundling core AI competencies—like vision, speech, and reasoning—into cohesive platforms, as seen with recent OpenAI and Anthropic model releases.
gentic.news Analysis
Cohere's release of Transcribe is a direct shot across the bow of OpenAI's Whisper ecosystem. OpenAI has been referenced in 297 prior gentic.news articles and is a dominant force in foundational AI models. While OpenAI's recent strategic shifts, as we covered on March 26, have involved winding down experimental projects like Sora, core capabilities like multimodal understanding remain central. Transcribe challenging Whisper's supremacy in ASR is a clear example of the competitive pressure in the infrastructure layer of AI, even as OpenAI focuses on higher-level agentic workflows, like its recently upgraded Codex targeting developer automation.
The choice to release Transcribe as Apache 2.0 is significant. It leverages the distribution power of Hugging Face (mentioned in 19 prior articles) to build developer mindshare and adoption, a classic playbook for challenging an incumbent. This open-source approach contrasts with the increasingly product-integrated strategy of major players. It also provides a compelling alternative to other open-weight models like Alibaba's Qwen family (mentioned in 9 articles), which includes its own ASR variant.
For developers, the key question is whether Transcribe's benchmark lead translates to robust real-world performance. If it does, it could rapidly become the preferred option for building voice-enabled applications, especially those requiring low latency. This release also enriches the toolset available for Retrieval-Augmented Generation (RAG) pipelines (a technology mentioned in 68 articles). Accurate speech-to-text is the critical first step for building RAG systems over audio and video content, an area of intense development.
Frequently Asked Questions
What is Cohere Transcribe?
Cohere Transcribe is a 2-billion parameter open-source automatic speech recognition (ASR) model. It converts spoken audio into text and claims to achieve a state-of-the-art average word error rate of 5.42% across 14 languages, currently topping the Hugging Face Open ASR Leaderboard.
How does Cohere Transcribe compare to OpenAI's Whisper?
According to Cohere's benchmark data, Transcribe outperforms OpenAI's Whisper Large v3 on the Hugging Face Open ASR Leaderboard, achieving a lower average Word Error Rate (5.42%). Cohere also claims Transcribe offers better inference throughput (speed) than similarly sized models, positioning it as both more accurate and faster for many tasks.
Is Cohere Transcribe free to use commercially?
Yes. Cohere Transcribe is released under the Apache 2.0 license, which is a permissive open-source license. This allows for free commercial use, modification, and distribution of the model, subject to the license terms.
What languages does Cohere Transcribe support?
The model supports 14 languages: English, German, French, Japanese, Spanish, Italian, Portuguese, Dutch, Polish, Turkish, Russian, Arabic, Hindi, and Chinese. Its performance is benchmarked across this multilingual set.