
A new research paper accepted at EACL 2026 delivers a dual critique of the membership inference attack (MIA) landscape, revealing that many popular benchmarks are fundamentally broken while also challenging the theoretical explanations for why some detection methods work. The work, shared in advance on LessWrong, introduces FiMMIA (Fidelity-based Multimodal Membership Inference Attack) and provides open-source tools, but its most significant contribution may be its methodological critique.
Key Takeaways
- A paper accepted at EACL 2026 shows membership inference attack (MIA) benchmarks suffer from data leakage, allowing model-free classifiers to achieve up to 99.9% AUC.
- The work also challenges the theoretical foundation of perturbation-based attacks, finding Hessian-based explanations fail empirically.
The Core Problem: Benchmarks That Leak
Membership inference attacks aim to determine whether a specific data sample was part of a model's training set. They're crucial for detecting dataset contamination—when evaluation data accidentally appears in training data, artificially inflating performance metrics—and for privacy auditing. However, their validity rests on a critical assumption: that the "member" (training) and "non-member" (test) samples are drawn from the same underlying distribution (i.i.d. assumption).
The researchers built a simple, model-free baseline classifier that uses only dataset features (like image spectral features or text word frequencies) to predict membership. This classifier has zero access to the target model or its outputs. If a benchmark is properly constructed, this baseline should perform at chance level (~50% AUC).
The results were damning. On several established MIA benchmarks, the model-free baseline achieved near-perfect separation:
WikiMIA 83.9% 99.0% Bag-of-words WikiMIA-24 99.8% 99.9% Bag-of-words VL-MIA-Flickr-2k (Multimodal) Not specified ~98.6% Image featuresWhat this means: The training and test splits in these benchmarks are statistically distinct. A detector can achieve high scores simply by learning the distributional differences between the splits (e.g., "if it's a satellite photo, it's from the training set; if it's a cat photo, it's from the test set"), not by detecting genuine model memorization. The researchers argue that any MIA approach must outperform this trivial baseline to claim it's detecting memorization rather than dataset artifacts.
Introducing FiMMIA: A New Multimodal Attack
Alongside the critique, the team presents FiMMIA, an extension of perturbation-based MIA to multimodal domains (e.g., vision-language models). The method works by:
- Generating semantic "neighbors": For a given sample (like an image-text pair), it creates perturbed versions using augmentations. The paper notes that more "adversarial" augmentations (e.g., inverting image colors—a rare training-time augmentation) yield stronger membership signals.
- Computing fidelity metrics: It calculates the differences in loss and embedding space between the original sample and its neighbors.
- Training a neural detector: A small classifier is trained on these fidelity metrics to predict membership.
The pipeline is modular and open-sourced on GitHub, with pre-trained detectors available on Hugging Face.
Challenging Established Theory: The "Hessian Fallacy"
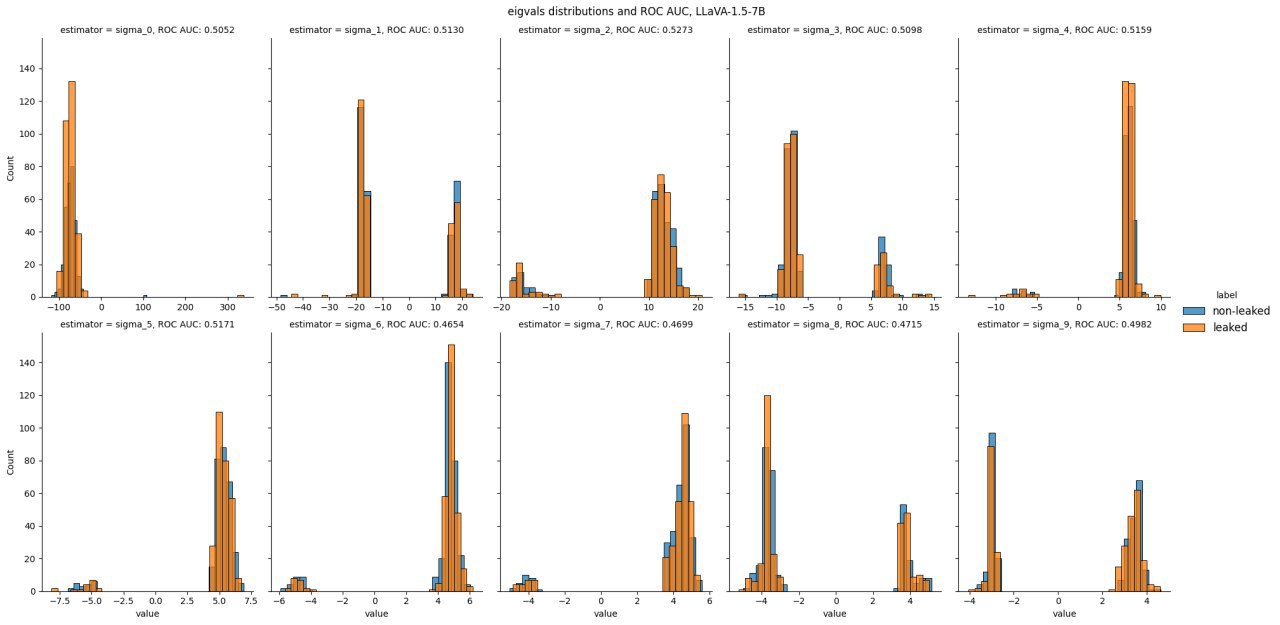
The most theoretically provocative finding challenges the explanation for why perturbation-based attacks (like Detect-GPT or Min-K%++) work. A influential line of reasoning suggests these methods succeed because they approximate the trace of the input-space Hessian (second derivative) of the loss. The theory posits that training samples reside in "sharper minima" (with larger Hessian traces) than non-member samples.
The researchers tested this empirically using Hutchinson's estimator and found it fails. Their analysis shows:
- The input-space Hessian for training samples is not positive-semi-definite, contradicting the assumption that they correspond to modes of the probability distribution.
- Hessian trace estimates yield chance-level detection performance.
- The eigenvalues of the Hessian for members versus non-members don't exhibit consistent sign patterns, making the "local basin" theoretical viewpoint questionable.
The paper concludes that the success of perturbation-based attacks likely stems from their semantic nature—probing how the model responds to meaningful variations—rather than from geometric properties of the loss landscape.
Implications for Evaluation and Safety
The broken benchmarks have direct consequences for AI safety and evaluation. If we cannot reliably detect dataset contamination, we cannot trust published capability estimates. This uncertainty creates room for phenomena like "sandbagging," where a model recognizes evaluation data as out-of-distribution and intentionally underperforms, masking its true capabilities.
The researchers advocate for a new standard: any MIA result must be compared against a strong, model-free baseline. They also highlight the need for properly constructed, leakage-free multimodal MIA benchmarks, which currently don't exist.
gentic.news Analysis
This research taps into a growing and critical trend in ML: the scrutiny of evaluation methodologies. As covered in our analysis of "The Reversal Curse" and benchmark contamination in LLMs, the field is undergoing a necessary correction, moving from a focus on leaderboard scores to robust, generalizable evaluation. The finding that simple baselines can exploit dataset flaws echoes issues seen in other domains, such as early adversarial example research where simple attacks were overlooked.
The challenge to Hessian-based theory is particularly significant. It targets work from influential groups (including those behind Detect-GPT) and suggests the community may have accepted an elegant mathematical narrative without sufficient empirical validation. This aligns with a broader push for more empirical, less theoretically speculative work in understanding neural network behavior, a trend evident in the rise of mechanistic interpretability research.
For practitioners, the immediate takeaway is to treat published MIA results with extreme skepticism unless they explicitly control for distributional shift. The provided FiMMIA code offers a more rigorous starting point for multimodal privacy auditing. The deeper lesson is that as AI systems become more central to safety-critical assessments, the infrastructure for evaluating those evaluations must be built with equal rigor.
Frequently Asked Questions
What is a membership inference attack (MIA)?
A membership inference attack is a method to determine whether a specific data sample was part of the training dataset used to create a machine learning model. It's used for privacy auditing (to see if a model has memorized sensitive data) and for detecting benchmark contamination, where test data accidentally leaks into the training set.
Why are the broken benchmarks a big problem?
If MIA benchmarks have fundamental data leaks, then high scores reported by new attack methods might not indicate they are better at detecting memorization. Instead, they might just be better at learning the accidental differences between the training and test splits of that specific, flawed benchmark. This invalidates comparisons and progress in the field.
What is the "Hessian fallacy" mentioned in the research?
The "Hessian fallacy" refers to the claim that certain perturbation-based MIAs work because they measure the trace of the Hessian matrix (related to the curvature of the loss function), with the idea that training points sit in "sharper" minima. This paper's empirical tests show this explanation fails—the Hessian traces don't correlate with membership, and the underlying mathematical assumptions don't hold.
How can I use the FiMMIA tool for my own models?
The researchers have open-sourced their complete pipeline on GitHub (ai-forever/data_leakage_detect). The toolkit is designed to be modular, allowing you to plug in your own multimodal model, generate semantic perturbations, extract fidelity metrics (loss/embedding differences), and train a detector to perform membership inference.







