Blind-edit rates in Claude Code climbed from 6.2% to 33.7% after Anthropic changed a default. A five-server cold-start routine cuts that to near zero, per a dev.to guide drawing on Anthropic issue #42796.
Key facts
- Blind-edit rates hit 33.7% after Anthropic changed a default.
- Five MCP servers run before any code is written.
- Context7 is one of the most-used MCP servers in 2026.
- Hooks guarantee execution regardless of model behavior.
- Memory persists decisions with confidence scores across sessions.
Claude Code went from research preview to a meaningful share of all public GitHub commits, per Anthropic's own data. Most of those commits shipped to production. A meaningful share rolled back soon after. The interesting question is not how the model writes the code. It is what happens in the early window before it starts. That window is where good Claude Code sessions and bad ones diverge.
The Cold-Start Problem
A fresh Claude Code session has no idea what you decided earlier, what the codebase looks like, what the current state of any library you depend on actually is, or what mistakes you already made and ruled out. Without help, it rebuilds your reasoning from scratch every time. Usually wrong.
Three failure modes show up almost immediately. The model invents class names that sound plausible but do not exist in the project. It cites API methods from versions of an SDK that got renamed two releases ago. It re-litigates decisions that were settled months earlier, because the rationale was never persisted anywhere the model could read. Each of these is fixable, but not by prompting harder. The fix is to give Claude Code the context it would have if it had been on the team for a while.
The Five-Step Stack
The routine runs at the start of every session, before any code is written. Five steps, in order.

1. Load Memory. The first call is to a memory MCP server that carries context across sessions. Recent sprint, open decisions, recent learnings, why a particular technical choice was made earlier, and the failure modes the team already hit. Memory is what turns a session from a cold start into a warm one.
2. Index the Codebase as a Graph. The second call is to a codebase memory server like codebase-memory-mcp, which indexes a repository into a queryable knowledge graph quickly, supports a wide range of languages, and answers structural questions with very low latency and a small fraction of the token cost compared to grep-and-read cycles [per the maintainer's benchmarks].
3. Search the Present, Not the Training Set. The third call is to a web search MCP server such as Tavily, Brave Search, or Anthropic web search. Training data ages, sometimes badly. A short search before a real decision gets a clean answer with sources, instead of a confident reconstruction of older consensus.
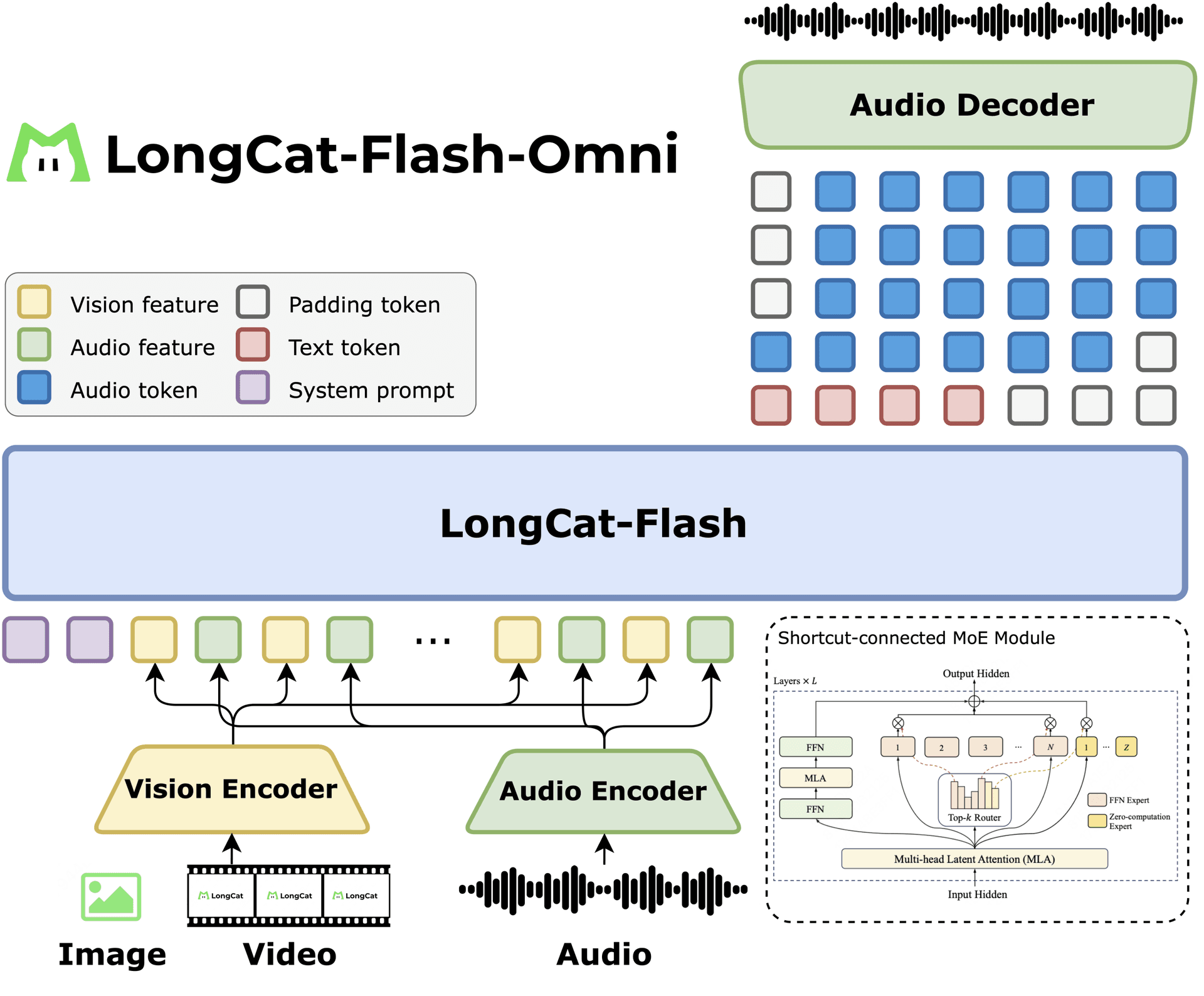
4. Load Context7 for Library Docs. The fourth call is to Context7, which fetches current documentation for whatever library is about to be touched. The training cutoff is the single largest source of plausible-looking-but-broken code that Claude Code generates. Loading the actual current docs ended that entire category of bug for production workflows months ago. Context7 is consistently cited as one of the most-used MCP servers in development setups in 2026.
5. Write Code. By the time the model starts writing, it has memory, codebase structure, current ecosystem context, and accurate library docs. The output reads differently: less "let me try this and see if it compiles," more "based on the call graph and the v5 docs, the change goes here."
The Hooks Layer
MCP servers feed the model context. Hooks enforce behavior. The distinction matters because hooks run outside the agent loop and are deterministic, which means they fire even when the model would rather not. Blake Crosley's complete CLI guide puts it cleanly: "Hooks guarantee execution of shell commands regardless of model behavior. Unlike CLAUDE.md instructions which are advisory, hooks are deterministic and guarantee the action."
Three hooks earn their place. The first is a read-before-edit guard. It refuses any edit on a file that the current session has not actually read first. This hook came out of the adaptive-thinking regression documented in Anthropic/claude-code issue #42796, where blind-edit rates climbed from 6.2% to 33.7% after Anthropic changed a default. The fix at the user level was a deterministic gate. The second is a safety guard for destructive commands like rm -rf, git push --force, or prisma db push --force-reset. The third is a re-index hook that fires after edits, refreshing the codebase knowledge graph so the next query reflects what is actually in the repo.
Closing the Loop
Whatever works in a session goes back into memory. Decisions get persisted as decisions. Patterns that proved themselves get stored as learnings, with confidence scores. Mistakes get logged with enough context that the next session avoids them. The next session starts with all of that already loaded. This is the part that compounds. The system gets sharper every week, not because the model changed, but because the context around it keeps growing in quality.
What to watch
Watch for Anthropic's next Claude Code release: if the default that caused the blind-edit regression (issue #42796) gets reverted or mitigated at the model level, the need for user-side deterministic gates may shrink. Also monitor MCP server ecosystem growth — Context7's usage share as a proxy for how many teams have internalized the cold-start problem.
[Updated 13 May via hn_claude_code]
A new open-source tool called Graphmind, built by former CTO Alex Aouicher, claims to reduce token consumption by up to 5,700× on large codebases by combining AST-based structural graphs with semantic embeddings and persistent memory [per GitHub]. In a test on a 31k-symbol repo, a search for 'payment processing' returned 257 tokens via Graphmind versus 1.4 million tokens via grep — saving roughly 10 million tokens over a typical session. The tool runs fully locally and integrates as an MCP server for Claude Code.