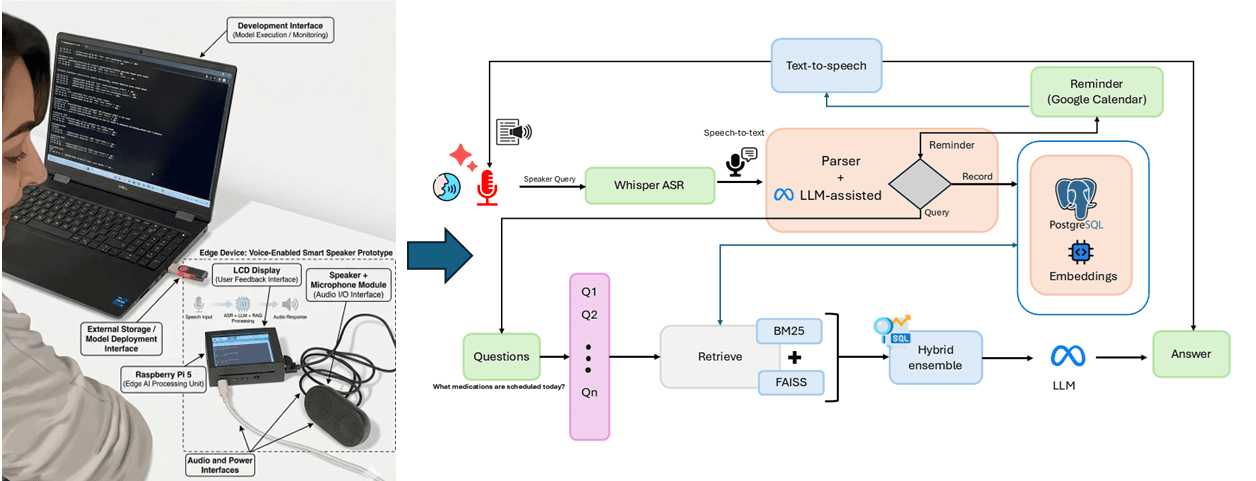
A research team has published a comprehensive safety evaluation of a multi-agent, voice-enabled smart speaker system designed for residential care homes. The system, detailed in a new arXiv preprint, combines OpenAI's Whisper speech recognition with multiple retrieval-augmented generation (RAG) approaches to help staff access resident records, set reminders, and schedule tasks through natural speech. In controlled testing and supervised trials, the best-performing configuration using GPT-5.2 achieved perfect resident identification but revealed persistent edge cases in converting informal spoken instructions into reliable calendar events.
This work arrives amid a surge of arXiv publications on RAG systems and their practical limitations, including a study published just yesterday evaluating RAG chunking strategies for enterprise documents. The care home application represents a particularly high-stakes domain where AI reliability directly impacts human safety.
What the Researchers Built: A Safety-First Voice Assistant Architecture
The system is architected as a pipeline with multiple failure points explicitly designed for graceful degradation. It begins with Whisper-based speech-to-text transcription, optimized for noisy care home environments and diverse accents. The transcribed text then passes through a multi-stage processing system:
Resident and Care Category Identification: Uses a combination of named entity recognition and database lookup to identify which resident is being discussed and classify the interaction into one of 11 care categories (medication, hygiene, meals, etc.).
Reminder Recognition and Extraction: Employs three different RAG approaches—hybrid, sparse, and dense retrieval—to extract structured reminder information from informal speech. The system was tested on 184 reminder-containing interactions out of 330 total transcripts.
Actionable Scheduling: Converts extracted reminders into calendar events via integration with care home management systems, with built-in uncertainty handling through confidence scoring and clarification prompts.
The safety framework incorporates human-in-the-loop oversight at critical junctures, particularly when confidence scores fall below predefined thresholds. The system is designed to defer or seek clarification rather than make incorrect assumptions—a crucial feature for medication scheduling or other time-sensitive care tasks.
Key Results: Near-Perfect Identification with Scheduling Gaps
The evaluation focused on three core metrics across 330 spoken interactions:

The 100% resident identification accuracy is particularly notable given the safety-critical nature of the application. However, the 84.65% end-to-end scheduling accuracy reveals the challenge of converting natural language like "remind me to check on Mrs. Johnson after lunch" into precise calendar entries with correct timing, duration, and recurrence patterns.
How It Works: RAG Configuration Comparisons
The researchers tested multiple RAG configurations to optimize different parts of the pipeline:

- Hybrid RAG: Combined sparse (keyword-based) and dense (semantic) retrieval methods, providing the best balance for reminder extraction in noisy transcripts.
- Sparse Retrieval: Traditional keyword matching that performed well on specific medication names but struggled with paraphrased instructions.
- Dense Retrieval: Semantic search using embeddings that captured intent better but sometimes retrieved irrelevant context.
The GPT-5.2 model (not to be confused with the specialized GPT-5.3-Codex series for software development) served as the primary LLM for reasoning and structured output generation. The system maintained a local knowledge base of resident records, care protocols, and staff schedules that was updated in real-time during interactions.
Confidence scoring was implemented at multiple levels: transcription confidence from Whisper, retrieval confidence from RAG similarity scores, and generation confidence from the LLM's token probabilities. When any confidence score fell below threshold, the system would either defer to human staff or ask clarifying questions like "Did you mean 2 PM or after the afternoon medication round?"
Why It Matters: A Template for High-Stakes AI Evaluation
This research provides more than just performance numbers for a specific system—it offers a replicable safety-focused evaluation framework for voice AI in critical environments. The 15.35% gap in end-to-end scheduling accuracy represents real-world failure cases that could lead to missed care tasks if deployed without safeguards.

The work aligns with broader industry trends showing strong preference for RAG over fine-tuning in production systems, as noted in an enterprise trend report from March 24. However, it also highlights domain-specific challenges that generic RAG systems don't address: handling overlapping conversations, background noise from televisions or other residents, and the informal, fragmented speech common in busy care environments.
gentic.news Analysis
This study arrives during a particularly active period for RAG research on arXiv, with the technology appearing in 28 articles this week alone. The care home application represents a meaningful advance beyond the enterprise document retrieval focus that dominates current RAG literature. While most RAG research optimizes for information retrieval accuracy, this work prioritizes safety and reliability—metrics that matter profoundly when errors affect vulnerable populations.
The perfect resident identification using GPT-5.2 is impressive but should be interpreted cautiously. The 95% confidence interval (98.86-100%) and relatively small sample size (330 interactions) suggest that real-world deployment might reveal edge cases not captured in controlled testing. This aligns with a cautionary tale about RAG system failures at production scale that was shared by a developer just yesterday—even well-evaluated systems can encounter unexpected failure modes when deployed.
Interestingly, the researchers chose GPT-5.2 rather than the more recent GPT-5.3 series, possibly due to cost, latency requirements, or the fact that care home applications don't require the advanced code generation capabilities of models like GPT-5.3-Codex-Spark. This pragmatic model selection reflects a growing maturity in AI deployment: choosing the right tool for the job rather than automatically using the most powerful available model.
The scheduling accuracy gap (84.65%) highlights a fundamental challenge in human-AI interaction: converting informal human speech into precise computational actions. This isn't just a speech recognition or RAG problem—it's a human-computer interaction challenge that may require different architectural approaches. The researchers' solution of confidence-based deferral to humans is sensible but may create its own workflow disruptions in time-pressured care environments.
Frequently Asked Questions
How does this care home smart speaker handle privacy and data security?
The paper mentions that the system maintains a local knowledge base of resident records and processes data on-premises where possible. Resident identification uses anonymized identifiers in the evaluation, and the architecture includes access controls to ensure staff only access records for residents under their care. However, the preprint doesn't provide detailed security protocols, which would be essential for real-world deployment given healthcare privacy regulations.
Could this system work in other healthcare settings like hospitals or home care?
The architecture is generalizable, but the evaluation specifically focused on residential care home environments with their particular noise profiles, accent diversity, and interaction patterns. Hospital settings might have more urgent, terse communication and different background noises (medical equipment alarms). Home care would involve different acoustic environments and potentially less formal resident records. The safety framework, however, provides a template that could be adapted to these settings with appropriate retraining and testing.
How does the performance compare to commercial voice assistants like Alexa or Siri in care settings?
The research doesn't provide direct comparisons, but commercial voice assistants aren't designed for care home specificity: they lack integration with resident records, don't understand care-specific terminology, and aren't evaluated against safety-critical metrics. The 100% resident identification and 89.09% reminder recognition likely far exceed what generic assistants would achieve in this domain, though at the cost of being a specialized rather than general-purpose system.
What are the main barriers to real-world deployment of such systems?
Beyond the technical accuracy gaps identified, deployment barriers include: regulatory approval for medical-adjacent devices, staff training requirements, integration with existing care home management software, ongoing maintenance costs, and liability considerations for AI errors. The human-in-the-loop safeguards, while necessary for safety, also mean the system doesn't fully reduce administrative workload—it redistributes it differently.






