
April 2026 — If you've ever spent hours building context with an AI assistant only to lose it all when starting a new chat, you've experienced what Andrej Karpathy calls "AI amnesia." In early April 2026, the former OpenAI co-founder and Tesla Autopilot architect published a simple two-page GitHub document outlining a solution that has since sparked dozens of implementations and over 5,000 stars. The framework, called LLM-Wiki, proposes a fundamental shift from retrieval-based systems to compilation-based knowledge bases.
Key Takeaways
- Andrej Karpathy published a two-page framework called LLM-Wiki that transforms how AI systems handle accumulated knowledge.
- Instead of retrieving from raw documents each time, the AI compiles sources into its own structured wiki that persists across sessions.
The Core Problem: AI as Tourist vs. Librarian

Current AI knowledge systems—including tools like NotebookLM and standard RAG (Retrieval-Augmented Generation) implementations—treat documents as external resources to be queried. Each interaction requires the AI to "read" relevant documents from scratch, answer the question, then forget everything. The AI remains a perpetual tourist in your knowledge library, never becoming the librarian.
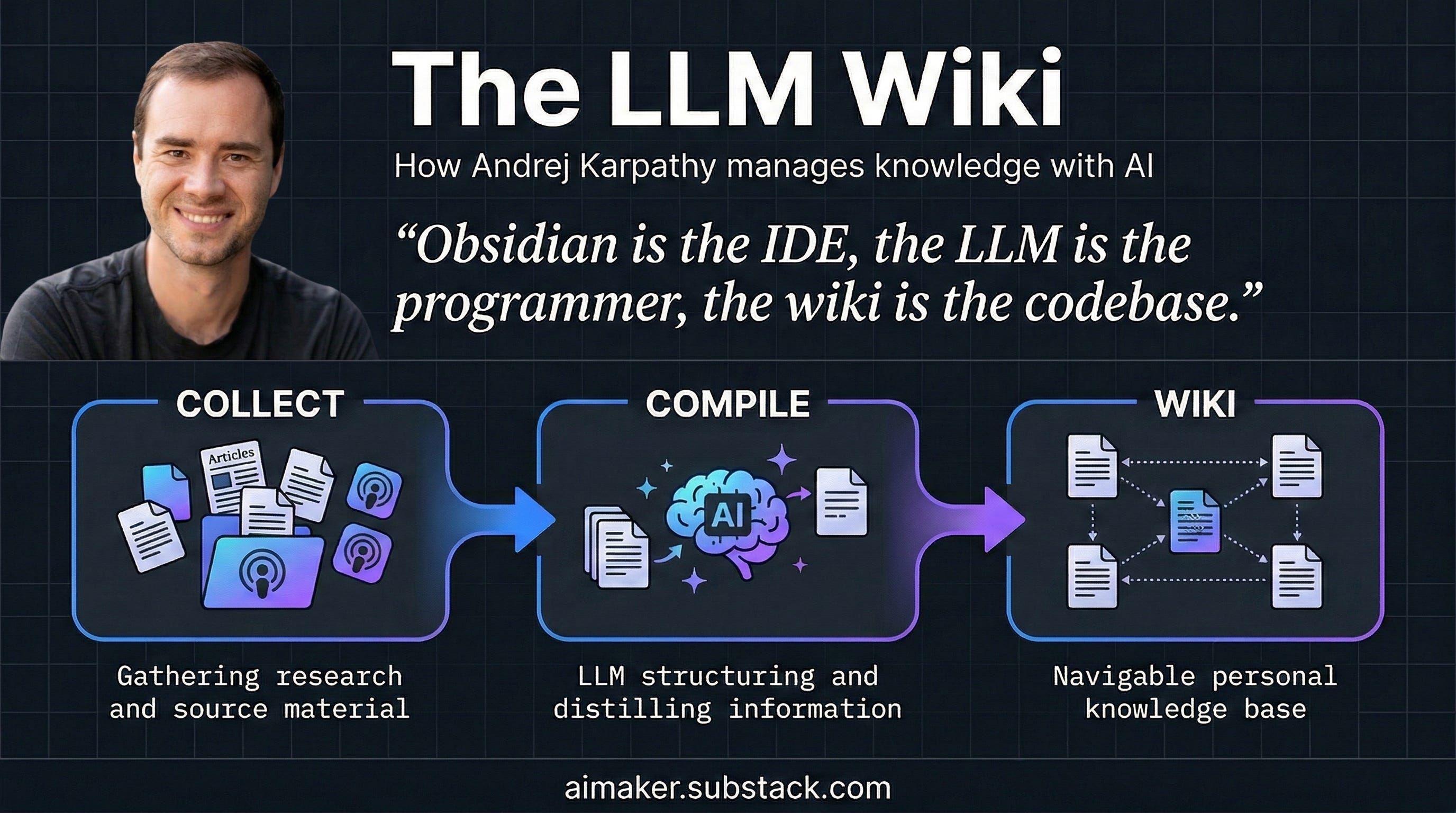
Karpathy's LLM-Wiki flips this model. Instead of retrieving from raw documents on every query, the AI studies documents and builds its own organized notes—a living wiki of markdown files that grows richer with each new addition. The key analogy: this is the difference between a compiler and an interpreter.
"When a programmer writes code, they do not run the source files directly every time," Karpathy explains in his GitHub gist. "They compile the source into an optimized artifact once, and then run the artifact. The compilation is expensive, but it pays for itself across every subsequent use."
How LLM-Wiki Works: The Three Components
The system consists of three straightforward components:
1. Raw Sources
Your original materials—research papers, articles, transcripts, notes—stored in a folder as the source of truth. These are never modified by the AI.
2. The Wiki
The AI's notebook: a collection of structured text files (one per concept, entity, or key topic) that the AI writes and maintains as it processes sources. Karpathy's own research wiki contains roughly 100 articles and 400,000 words—equivalent to five novels—all authored by the AI while he did the reading.
3. The Schema
An instruction manual telling the AI exactly how the notebook is organized, what to do with new sources, how to flag contradictions, and how to answer questions. This transforms a generic chatbot into a disciplined researcher following consistent methodology.
The Three-Verb Workflow
Once established, interaction reduces to three actions:
Ingest: Add a new document. The AI reads it, writes a summary, and updates every relevant wiki page (typically 10-15 pages per article). New information ripples through the existing knowledge structure.
Query: Ask a question. The AI consults its own notes rather than raw documents. Crucially, good answers are saved back into the wiki as new pages, ensuring questions make the system smarter.
Lint: Periodically audit the wiki. The AI checks for contradictions, outdated claims, missing concept pages, and suggests research gaps.
Current Implementations and Limitations
Within two weeks of publication, developers had created implementations for:
- Research synthesis: Building literature reviews across months of paper reading
- Code knowledge bases: Converting AI coding session transcripts into persistent architecture notes and decision logs
- Team wikis: Processing Slack threads, meeting notes, and customer call transcripts into shared, AI-maintained knowledge bases
- Personal tracking: Health data, journal entries, and self-improvement reading organized into structured personal wikis
Karpathy acknowledges current limitations:
- Works best at personal scale (10 to a few hundred documents)
- Quality depends entirely on the LLM's accuracy during ingestion
- Less suited for rapidly changing information like news or stock prices
- Requires periodic human review to catch propagated errors
Technical Implementation Patterns
Early implementations follow similar architectural patterns:
# Simplified workflow example
wiki = LLMWiki(schema="research_schema.md")
wiki.ingest("paper.pdf") # AI reads, summarizes, updates relevant pages
answer = wiki.query("How does this relate to previous work on X?")
wiki.add_page("comparison_X_Y.md", answer) # Save answer back to wiki
wiki.lint() # Run consistency checks
The system typically uses:
- Embedding-based retrieval within the wiki for relevant context
- Structured prompting guided by the schema document
- Version control (Git) to track wiki evolution
- Cost optimization by compiling once, querying many times
gentic.news Analysis
Karpathy's LLM-Wiki concept arrives at a critical inflection point in AI assistant evolution. For years, the field has focused on improving retrieval (better embeddings, chunking strategies, reranking) while accepting the fundamental limitation of session-based amnesia. This framework represents a paradigm shift toward persistent, evolving knowledge structures—what some researchers call "exo-memory" for AI systems.
This development aligns with several trends we've tracked: the rise of AI agents that need persistent memory (covered in our February 2026 analysis of Google's SIMA), increasing focus on long-context window optimization, and growing frustration with the limitations of chat-based interfaces for serious research work. Karpathy's approach is particularly notable because it's framework-agnostic—it's a pattern rather than a product, making it immediately accessible to developers working with any capable LLM.
The rapid community adoption (5,000+ GitHub stars in two weeks) suggests this addresses a genuine pain point that existing commercial solutions have overlooked. While companies like Anthropic have improved Claude's context window to 200K tokens and OpenAI has experimented with persistent memory features, these remain within the session-based paradigm. LLM-Wiki proposes something more radical: AI systems that accumulate knowledge structurally over time, much like human experts do.
Looking forward, the most interesting developments will likely come from hybrid approaches that combine LLM-Wiki's compilation philosophy with traditional RAG's scalability. We expect to see implementations that automatically segment knowledge bases by domain, use hierarchical schemas for different abstraction levels, and incorporate confidence scoring to flag uncertain inferences. The framework's simplicity is its greatest strength—it provides a clear mental model that developers can adapt rather than a rigid architecture they must adopt wholesale.
Frequently Asked Questions
How is LLM-Wiki different from traditional RAG?
Traditional RAG retrieves relevant chunks from raw documents on every query, treating the AI as a reader who must re-learn material each time. LLM-Wiki compiles documents into an AI-authored knowledge base once, then queries that compiled representation. The AI becomes the author and maintainer of the knowledge structure rather than just a reader.
What LLMs work best with this framework?
The framework is model-agnostic, but implementations typically use capable reasoning models like GPT-4, Claude 3.5 Sonnet, or open-source alternatives like DeepSeek-R1. The quality of the generated wiki depends directly on the LLM's ability to synthesize information accurately and maintain consistency across multiple documents.
How does this handle conflicting information from different sources?
The schema includes instructions for how to flag contradictions—typically by creating special "contradiction" pages or adding conflicting viewpoints to concept pages with clear attribution. The periodic "lint" operation specifically looks for inconsistencies, and the system maintains links back to original sources for verification.
Can multiple people collaborate on the same LLM-Wiki?
Yes, though early implementations focus on personal use. Collaborative versions typically use Git for version control, with the AI handling merge conflicts by synthesizing contributions. Some teams are experimenting with shared schemas where different members contribute different types of documents (research, customer feedback, technical specs) to a unified knowledge base.
What's the computational cost compared to standard RAG?
The initial compilation (ingestion) is more expensive than single-document RAG, as the AI must read each document thoroughly and update multiple related wiki pages. However, subsequent queries are significantly cheaper since they work from the already-compiled wiki. For knowledge bases that are queried frequently, the total cost is lower over time.







