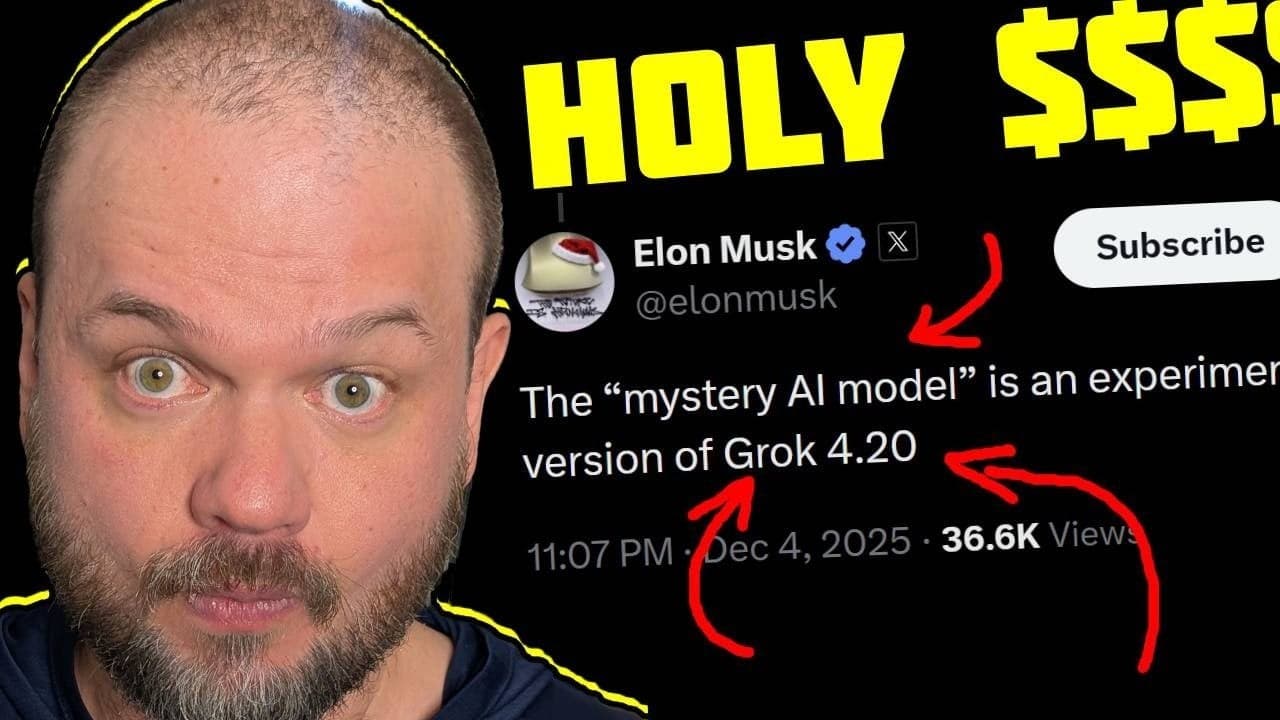
A new, unverified claim from a user on X suggests xAI's development pipeline is moving at a breakneck pace. According to the post, the current iteration, referred to as "Grok 4.20," is built on approximately 0.5 trillion parameters. More notably, the claim states that a new 1 trillion parameter model could be ready in 2-3 weeks, with a 1.5 trillion parameter version following in 4-5 weeks.
What Happened
The source is a single, brief social media post from user @kimmonismus. It provides no technical details, benchmarks, or official confirmation from xAI. The post makes two core claims:
- The existence of a model called "Grok 4.20" with roughly 500 billion parameters.
- An aggressive timeline for releasing significantly larger models: a 1T model in "about 2-3 weeks" and a 1.5T model in "4 to 5 weeks."
The post concludes with, "Competition is heating up - again," framing this as a move in the ongoing large language model scaling race.
Context: The Parameter Scaling Race
Parameter count, while a crude metric, has been a primary axis of competition among frontier AI labs. OpenAI's GPT-4 is widely estimated to be a mixture-of-experts model with over 1 trillion parameters. Anthropic's Claude 3 Opus and Google's Gemini Ultra are also in the same competitive tier. xAI's first major model, Grok-1, was a 314 billion parameter dense transformer released in late 2023. A jump to 0.5T, and then to 1.5T, would represent a massive scaling effort in a short timeframe.
If accurate, this timeline suggests xAI is either sitting on completed, larger models and is staggering release, or has achieved a highly efficient and rapid training pipeline. The latter would be a significant technical achievement in itself.
What This Means in Practice
For developers and researchers, a 1.5 trillion parameter model from xAI would immediately become one of the largest publicly known language models. The practical implications depend entirely on its architecture (e.g., dense vs. mixture-of-experts), training data, and resulting capabilities. A model of that scale, if well-trained, could potentially challenge the current top-tier models on complex reasoning and coding benchmarks. However, without official details or benchmarks, its performance remains speculative.
The claimed timeline also pressures competitors. A public roadmap suggesting a new top-tier model every month would force other labs to accelerate their own release cycles or communication strategies.
gentic.news Analysis
This rumor, while unconfirmed, fits a clear pattern in xAI's strategy of rapid, public iteration and aggressive positioning. Following the release of Grok-1.5 Vision in April 2024, which added multimodal capabilities, the focus appears to have shifted back to raw scale and core language performance. The jump from 314B (Grok-1) to a purported 500B (Grok 4.20) and then to 1.5T in a matter of weeks is astronomically fast by historical standards. For context, the development cycle from GPT-3 (175B) to GPT-4 (est. >1T) spanned nearly three years.
This acceleration suggests two non-mutually exclusive possibilities. First, xAI may be leveraging vastly improved training infrastructure and stability, potentially building on lessons from its close association with X (formerly Twitter) for data and Tesla for compute infrastructure. Second, it may indicate a strategic shift to a mixture-of-experts (MoE) architecture, where the "parameter count" includes many dormant experts, making training and inference more efficient than an equivalently sized dense model. Meta's Llama 3 405B model successfully uses an MoE architecture, and it's a proven path to scaling parameter counts without a linear increase in compute cost per token.
If xAI delivers a 1.5T model by mid-2026 that is competitive with GPT-4.5/5 or Claude 3.5 Sonnet, it would fundamentally alter the market perception of the company from an ambitious newcomer to a sustained frontier contender. However, the key test will be benchmark performance, not just parameter size. The AI community will be watching for results on MMLU, GPQA, MATH, and coding benchmarks like SWE-Bench to see if this scaling translates to measurable gains.
Frequently Asked Questions
Is Grok 4.20 officially released?
No. As of now, "Grok 4.20" is only mentioned in an unverified social media post. There has been no official announcement, technical paper, or release from xAI regarding this specific model version or its parameter count.
What is the difference between 0.5T and 1.5T parameters?
A 0.5 trillion (500 billion) parameter model is already extremely large, comparable to early estimates for Google's PaLM. A 1.5 trillion parameter model would be among the largest known language models, similar in scale to estimates for OpenAI's GPT-4. In theory, more parameters can increase a model's capacity to learn and store information, but performance depends critically on the quality of training data, architecture, and alignment techniques.
Why would xAI release models so quickly?
Rapid iteration serves multiple purposes: it attracts developer and user attention, pressures competitors, generates public feedback for improvement, and demonstrates technical prowess in model training and infrastructure. It is a hallmark of a "move fast" culture often seen in startups competing against established giants.
How can a model be trained in just a few weeks?
Training a frontier model from scratch in weeks is highly unlikely. The timeline in the rumor suggests these models may already be largely trained and are in final stages of evaluation, fine-tuning, or safety testing. Alternatively, it could imply the use of progressive training or efficient architectures like Mixture of Experts (MoE) that allow for faster training cycles compared to dense transformers of equivalent size.