A new cross-sectional analysis of health AI benchmarks, published on arXiv, reveals a significant disconnect between the queries used to evaluate large language models (LLMs) and the actual needs of clinical practice. The study, which analyzed 18,707 consumer health queries across six public benchmarks, identifies what the authors term a "validity gap"—a structural misalignment that could lead to inflated perceptions of model readiness for real-world medical use.
What the Researchers Analyzed
The research team applied a standardized 16-field taxonomy to profile the context, topic, and intent of queries within six public benchmarks used to validate health-related LLMs. Using LLMs themselves as automated coding instruments, they systematically categorized each query across dimensions including:
- Data Type Referenced: Objective data (e.g., lab values, wearable signals) vs. subjective description.
- Clinical Topic: Wellness, acute diagnosis, chronic disease management, mental health, etc.
- Patient Population: Age groups (pediatric, adult, older adult), implied demographics.
- Query Intent: Information retrieval, diagnostic assistance, care planning.
The core methodology treats benchmark composition analysis with the same rigor as clinical trial reporting, where transparent inclusion and exclusion criteria are mandatory for assessing generalizability.
Key Results: The Composition Breakdown
The analysis yields concrete, concerning statistics about what current benchmarks actually contain.

The study notes that while benchmarks have technically evolved from static QA to interactive dialogue, their clinical composition has not kept pace. The "validity gap" is structural: the tests being used are not testing for the right things.
How the Analysis Was Conducted
The researchers employed a two-stage LLM-based coding process. First, they used a high-performing general-purpose LLM (the paper does not specify which) to generate initial annotations for each query against their 16-field taxonomy. Second, a separate adjudication step, involving both automated consistency checks and manual sampling, was used to validate the coding reliability.

The six benchmarks analyzed were not named individually in the abstract, but are described as "public benchmarks" commonly cited in health AI literature. The 18,707 queries represent a significant sample of the current evaluation landscape.
The taxonomy itself is key. It moves beyond simple medical subject headings and attempts to capture the pragmatic context of a health query: Why is this question being asked? What data is available? Who is it for? This allows the gap between benchmark queries and real-world clinical encounters to be quantified.
Why It Matters: Beyond Aggregate Accuracy
The primary conclusion is that aggregate performance metrics (e.g., "Model X achieves 85% accuracy on health benchmark Y") are potentially misleading. A model could excel on a benchmark over-indexed on wellness questions and wearable data but fail catastrophically when presented with a fragmented electronic health record or a nuanced query about managing stage 4 kidney disease.

This has direct implications for:
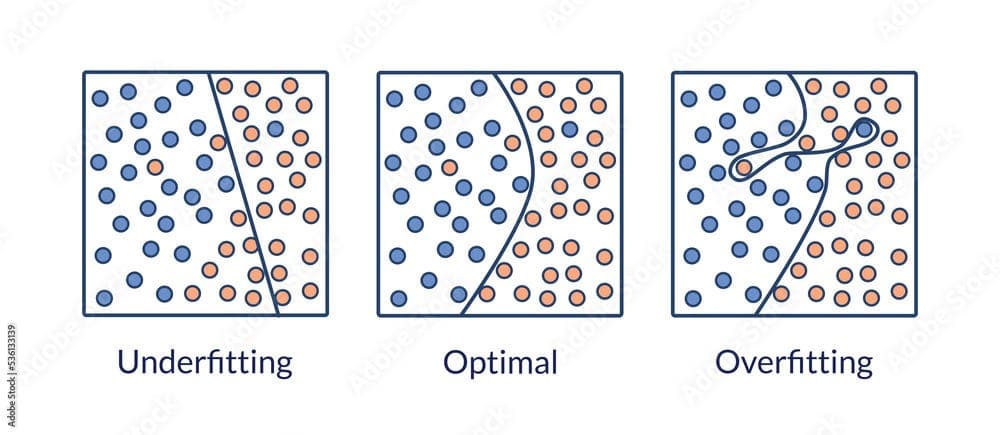
- Model Development: Teams optimizing for benchmark leaderboards may be overfitting to a non-representative distribution of tasks.
- Clinical Translation: Regulators, hospital systems, and practitioners relying on published benchmarks to gauge model readiness may have a false sense of security.
- Safety: The near-absence of high-stakes scenarios like suicide risk assessment means models have not been stress-tested in the areas where failure is most dangerous.
The authors advocate for a paradigm shift: standardized query profiling. Every health AI benchmark should be published with a "data sheet" or "composition report" akin to a clinical trial protocol, detailing the represented patient populations, data types, clinical scenarios, and intents. This would allow consumers of research to understand what a model's score actually means and what it leaves untested.
The Path Forward
The paper ends with a call to action. Closing the validity gap requires:
- New Benchmarks: Constructing evaluation suites that include rich, de-identified clinical artifacts (progress notes, lab reports, imaging summaries).
- Intentional Sampling: Oversampling underrepresented but critical areas like mental health crises, complex chronic care, and care for vulnerable populations.
- Reporting Standards: The community adopting minimum reporting standards for benchmark composition.
Without these steps, the field risks creating increasingly powerful AI that is validated against a reality that doesn't exist in any clinic or hospital.