What Happened: The Dawn of Autonomous MLOps
A new technical article on Medium’s Artificial Intelligence in Plain English platform details a significant engineering milestone: the creation of a self-healing MLOps platform. The author built a fraud detection system that operates with a high degree of autonomy. Its core functions include detecting model drift in real-time, scoring live financial transactions, and—most critically—investigating its own production failures. When an anomaly or failure is detected, the system doesn't just send an alert; it initiates a diagnostic workflow, attempts remediation, and only pages a human engineer if its automated recovery procedures are insufficient. The article promises a firsthand account of what transpired when this system activated its own incident response protocol.
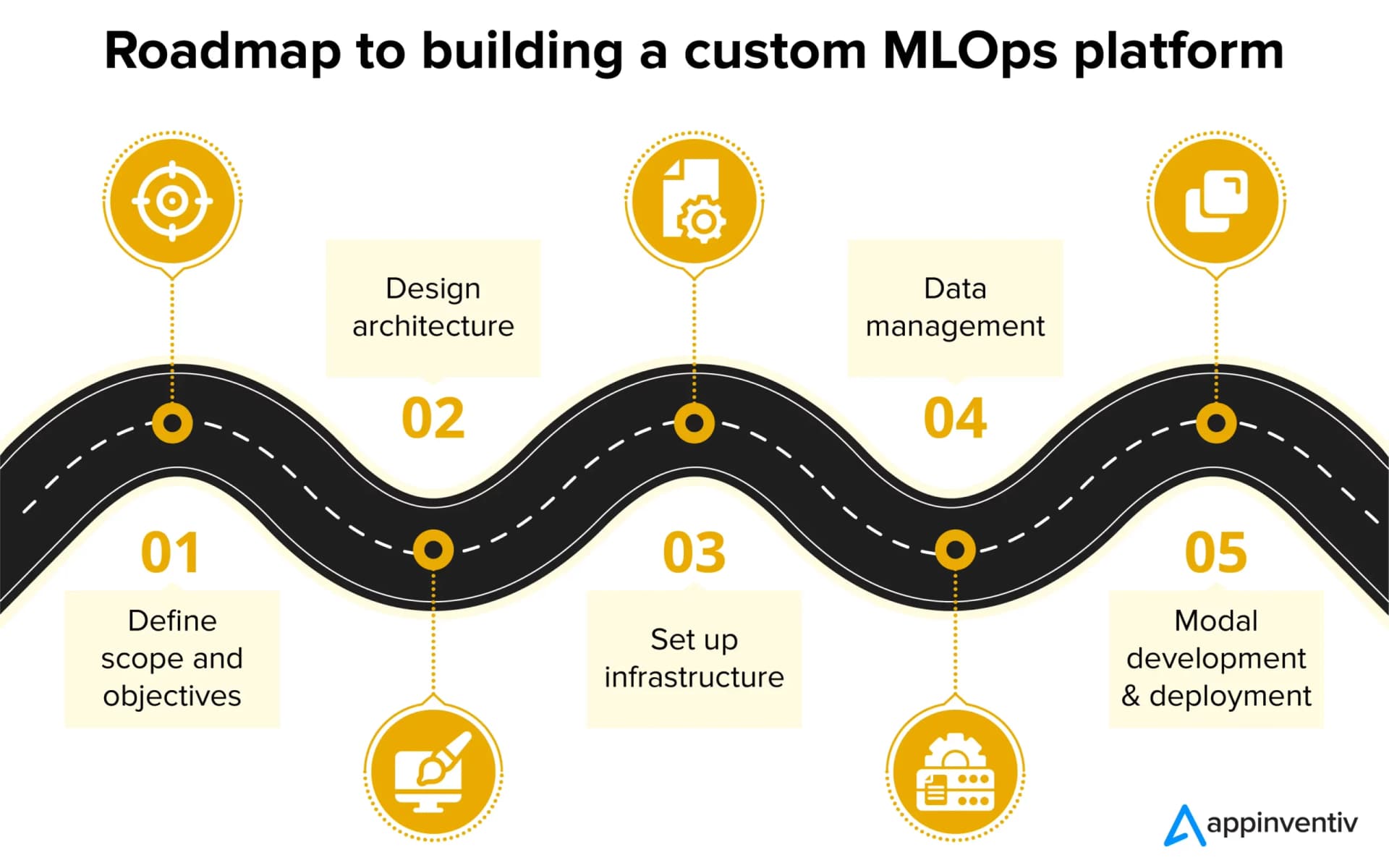
This is not a theoretical framework but a practical implementation, suggesting a move beyond traditional monitoring dashboards and manual rollbacks. The platform embodies the principle of "AI managing AI," where operational intelligence is baked directly into the deployment pipeline. For technical leaders, the key takeaways are the architectural patterns that enable this autonomy: likely involving robust CI/CD for models, comprehensive observability stacks, and automated decision trees for incident management.
Technical Details: The Pillars of Self-Healing AI
While the full article is behind Medium’s subscription paywall—a platform we've noted hosts a growing repository of expert implementation guides—the summary points to several critical technical components:
- Advanced Drift Detection: The system continuously compares live transaction data and model predictions against the training data distribution and expected performance baselines. This goes beyond simple accuracy metrics to potentially include data drift, concept drift, and anomaly detection in the feature space.
- Integrated Scoring & Monitoring: The inference engine for live fraud scoring is intrinsically linked to the health monitoring system. Performance metrics, latency, and prediction confidence are fed back in real-time to form a closed-loop assessment.
- Automated Incident Investigation & Remediation: This is the "self-healing" core. Upon detecting an issue (e.g., drift beyond a threshold, spike in false positives), the system likely triggers a series of automated actions. These could include: rolling back to a previous model version, switching to a fallback heuristic, retraining on fresh data, or conducting a root-cause analysis by querying logs and feature stores.
- Intelligent Alerting: The platform "pages itself" by initiating an incident ticket within a system like PagerDuty or Opsgenie. It would populate this ticket with initial diagnostic data. A human is paged only if the issue is classified as severe or if automated remediation fails after a defined sequence, moving from a "self-heal" to a "call for help" state.
Retail & Luxury Implications: From Fraud to Fashion
The described platform is built for fraud detection, but its architectural blueprint is directly transferable to high-stakes AI use cases in retail and luxury. The core value proposition—minimizing downtime, maintaining model performance, and reducing the operational burden on data science teams—is universal.
Concrete Applications:
- Dynamic Pricing Engines: A self-healing system could monitor a real-time pricing model for drift caused by sudden fashion trends, influencer impacts, or competitor actions. If it detects performance degradation, it could automatically revert to a conservative rule-based pricing strategy while retraining the model on the latest data, ensuring revenue is never left on the table due to a stale model.
- Personalized Recommendation Systems: Customer taste evolves. A self-monitoring recommendation platform could detect when user engagement metrics (click-through rate, add-to-cart) begin to drop. It could trigger an automated A/B test with a newly refreshed model or adjust the weighting of collaborative filtering versus session-based signals without manual intervention.
- Inventory Forecasting and Supply Chain AI: Anomalies in demand forecasting due to unforeseen events (a product going viral, a supply chain disruption) could be automatically detected. The system could page the supply chain team with a pre-populated analysis of the forecast error and potentially switch to a more robust, simpler forecasting model for affected SKUs until the situation stabilizes.
- Computer Vision for Quality Control: In luxury manufacturing, a vision model inspecting leather goods or watch components must be exceptionally reliable. A self-healing pipeline could monitor for drift caused by new material batches or subtle lighting changes on the factory floor, automatically recalibrating or flagging the need for human retraining.
The shift here is from reactive MLOps (a model fails, an alert fires, a team scrambles) to proactive and autonomous AI operations. This aligns with the broader industry trend we've observed, where compute scarcity and high costs, as noted in our March 11th analysis, force a prioritization of automation for high-value, critical-path AI systems to ensure maximum ROI and reliability.