Key Takeaways
- An IBM article critiques monolithic recommendation engines for trying to do too much with one score.
- It proposes a layered architecture—candidate generation, ranking, and business logic—to improve performance and adaptability.
- This is a direct, practical framework for engineering teams.
The Innovation — What the source reports

The core thesis from IBM's Data Science in Practice blog is stark: "Most recommendation systems fail for a simple reason: they expect a single score to do too much work." This single score—often a predicted click-through rate (CTR) or purchase probability—is forced to simultaneously represent user relevance, business value, novelty, and fairness. The result is a brittle, monolithic system that is difficult to debug, optimize, or adapt to new business goals.
The proposed solution is an architectural shift: decomposing the recommendation pipeline into distinct, purpose-built layers. While the full article is behind a link, the premise points to a well-established but often under-implemented best practice in production ML systems.
Why This Matters for Retail & Luxury
For luxury and retail, where customer lifetime value, brand perception, and margin are paramount, a one-dimensional "relevance" score is particularly inadequate. Consider these concrete scenarios:
- The High-Margin Push: A monolithic system might rank a high-relevance, low-margin accessory above a slightly less relevant, but exceptionally high-margin ready-to-wear item. A layered system can separate the "relevance" prediction from a subsequent business logic layer that applies margin-based boosting.
- New Product Launch & Cold Start: Launching a new handbag collection is a critical commercial moment. A single-score system, trained on historical engagement, will inherently deprioritize these items due to lack of data. A dedicated candidate generation layer can be programmed to inject new collection items into the pool, while the ranking layer assesses their potential fit for each user.
- Personalization vs. Curation: Luxury is not just about predicting taste; it's about guiding it. A layered architecture allows brands to separate algorithmic personalization ("customers who viewed this also viewed...") from editorial curation ("Our Creative Director's Picks") and then blend them intelligently in a final business logic layer.
- Fairness and Diversity: Avoiding repetitive recommendations of the same product category (e.g., only showing black loafers) requires explicit diversity logic. Trying to bake this into a single model score corrupts its predictive accuracy. A post-ranking re-ranker layer can enforce diversity rules without compromising the core relevance model.
Business Impact
The impact is operational excellence and strategic agility. Quantifying it depends on the starting point, but the gains are clear:
- Improved Debugging & Uptime: When recommendations degrade, teams can isolate the issue to a specific layer (e.g., candidate generation is stale, ranking model drifted, business rules are misconfigured) instead of retraining a massive monolithic model.
- Faster Experimentation: New ranking models, candidate sources, or business rules (e.g., "boost sustainability-labeled products by 15%") can be tested and deployed independently, accelerating the innovation cycle.
- Balanced Metrics: Moving beyond a single engagement metric (like CTR) allows for the optimization of a composite goal—e.g., (0.7 * Relevance Score) + (0.2 * Margin Score) + (0.1 * Diversity Score)—aligning algorithms directly with business KPIs.
Implementation Approach
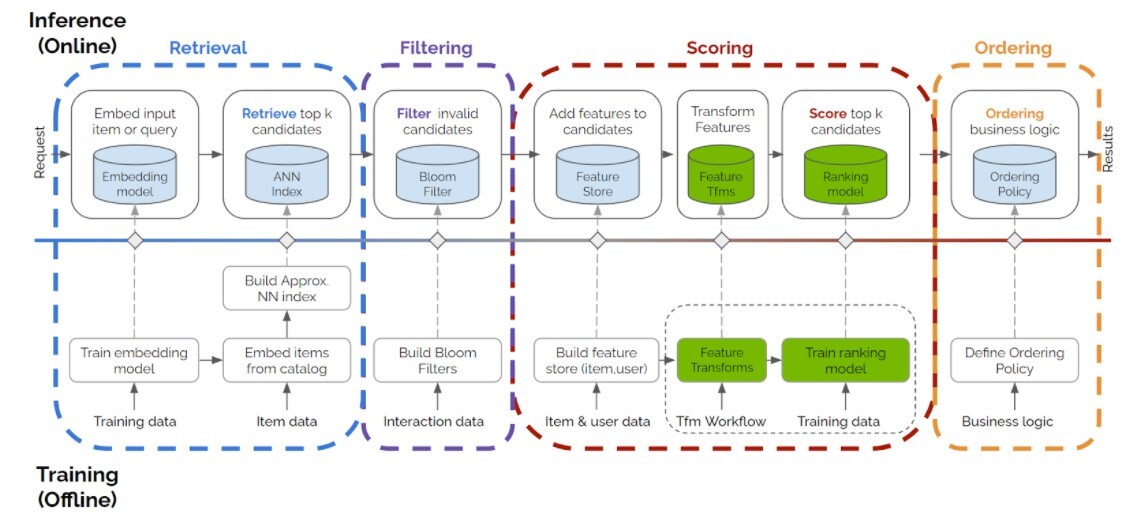
Implementing this requires a move from a single-model endpoint to a orchestrated pipeline. The typical layers are:
- Candidate Generation (Recall): Retrieves hundreds to thousands of potentially relevant items from a massive catalog. Techniques include collaborative filtering (e.g., IAT compression for user sequences), content-based filtering, or simple popularity filters. This is about breadth and speed.
- Ranking (Precision): Takes the candidate pool and scores each item for personalized relevance using a more complex model (e.g., a deep neural network). This is where most traditional recommender system research, like the recent arXiv study on data scaling, is focused.
- Business Logic & Re-ranking: Applies hard rules and soft boosts. This layer enforces inventory constraints, promotes strategic items, ensures diversity, and blends in editorial content. It's often rule-based or uses a lightweight model to re-order the top-N list from the ranking layer.
Technical requirements include a feature store for consistent data, a model serving platform (like KServe, Seldon, or proprietary cloud AI), and workflow orchestration (Apache Airflow, Kubeflow). The complexity is moderate but manageable for teams with MLOps maturity; the effort is front-loaded in redesigning the data pipeline.
Governance & Risk Assessment
- Privacy: A layered system often means more models and services touching user data. A robust data governance framework, with clear lineage and access controls between layers, is essential, especially under regulations like GDPR.
- Bias: Bias can be introduced or amplified at any layer. Candidate generation can create availability bias, ranking models can perpetuate historical bias, and business rules can encode human bias. Each layer requires its own fairness audits.
- Maturity: This is not a novel research concept but a battle-tested production pattern used by leading tech and retail companies. The risk lies not in the architecture's novelty but in the operational overhead of managing multiple interconnected components.
gentic.news Analysis
This IBM perspective aligns with a clear industry trend toward the decomposition and specialization of AI systems, moving away from the "magic black box" model. It directly connects to two key threads we've been tracking:
First, it provides the production architecture for leveraging advanced research like the Instance-As-Token (IAT) compression method we covered on April 13th. That research optimizes the candidate generation layer by efficiently modeling long user behavior sequences. IBM's layered framework is precisely where such an innovation would be deployed—improving recall without complicating the ranking stage.
Second, it contextualizes findings like the recent arXiv study (April 9th) which found no saturation point for data in traditional recommender systems. That research primarily benefits the ranking layer, where larger, higher-quality datasets continuously improve the precision of relevance scoring. The layered approach ensures that these gains in ranking are not undermined by a poor candidate generation pool or misaligned business rules.
For luxury AI leaders, the takeaway is that the competitive edge in recommendations will come less from a single algorithmic breakthrough and more from orchestrating specialized components—each informed by cutting-edge research but governed by clear business objectives. The next phase is not just about better models, but about smarter, more transparent pipelines.








