In the rapidly evolving landscape of artificial intelligence, a groundbreaking development has emerged from the intersection of Large Language Models and distributed computing. Researchers have introduced Rudder, a software module that leverages LLM agents to dramatically improve the efficiency of distributed Graph Neural Network training. This innovation, detailed in a recent arXiv preprint (arXiv:2602.23556), represents a significant leap forward in addressing one of the most persistent challenges in large-scale AI training: communication bottlenecks.
The Problem: Communication Stalls in Distributed GNN Training
Graph Neural Networks have become essential tools for analyzing complex relational data, from social networks and recommendation systems to molecular biology and fraud detection. However, training these models at scale presents unique challenges. Unlike traditional neural networks that process grid-like data, GNNs operate on irregular graph structures where each node's computation depends on its neighbors.
When training on massive graphs that must be distributed across multiple computing nodes, the process becomes communication-intensive. Each training step requires fetching remote neighbor data, creating irregular communication patterns that can stall forward progress. Traditional prefetching methods—attempting to predict what data will be needed next—struggle with the dynamic nature of these systems, where what needs to be fetched changes with graph structure, distribution patterns, sampling parameters, and caching policies.
Rudder's Innovative Approach: LLM Agents as Adaptive Controllers
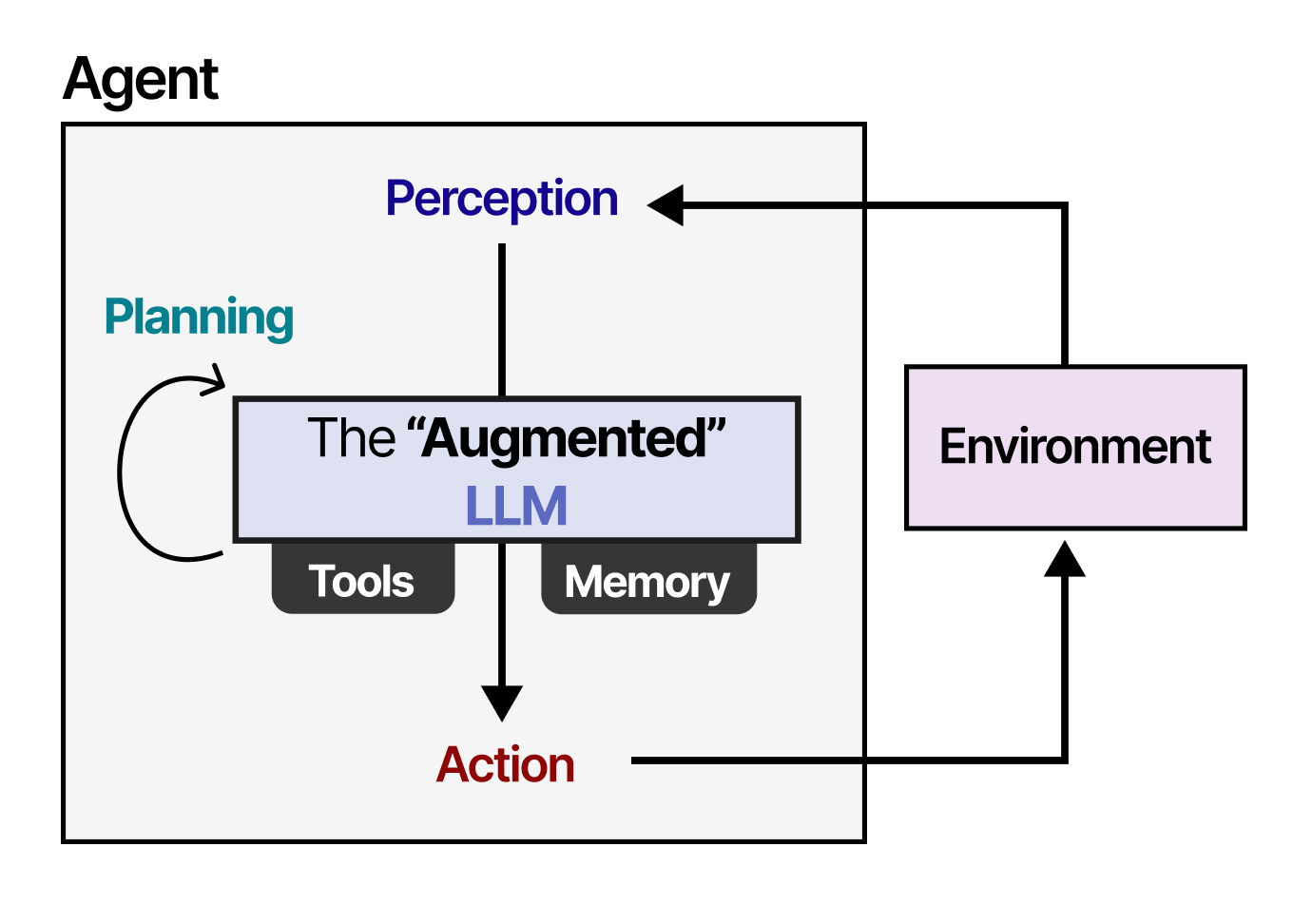
Rudder's core innovation lies in its use of Large Language Model agents as intelligent prefetching controllers. Unlike traditional machine learning classifiers or static heuristics, Rudder harnesses the emergent properties of contemporary LLMs—particularly their In-Context Learning capabilities and logical multi-step reasoning—to make dynamic prefetching decisions.
Embedded within the state-of-the-art AWS DistDGL framework, Rudder operates by:
- Monitoring system states including graph characteristics, distribution patterns, and computational progress
- Analyzing patterns in data access and communication requirements
- Generating adaptive prefetching strategies that evolve with changing conditions
- Minimizing communication overhead by predicting and fetching only what's necessary
What makes this approach particularly remarkable is that the LLM agents demonstrate effective control even with substantial undertraining, leveraging their zero-shot learning capabilities to adapt to unseen configurations.
Performance Breakthroughs: Up to 91% Improvement
Evaluations conducted on the NERSC Perlmutter supercomputer using standard datasets reveal staggering performance gains:
- 91% improvement in end-to-end training performance over baseline DistDGL with no prefetching
- 82% improvement over static prefetching methods
- Over 50% reduction in communication overhead
These results demonstrate that Rudder doesn't just marginally improve existing systems—it fundamentally transforms how distributed GNN training handles communication. The system's ability to adapt to "unseen configurations" suggests robust generalization capabilities that could make it valuable across diverse application domains.
Technical Implementation and Integration
Rudder's architecture represents a sophisticated integration of several cutting-edge technologies. The system operates as a middleware layer within distributed training frameworks, intercepting data requests and making intelligent prefetching decisions. Key technical components include:
- State representation modules that transform system conditions into natural language prompts
- LLM reasoning engines that analyze current states and predict future requirements
- Action translation layers that convert LLM outputs into concrete prefetching operations
- Feedback loops that continuously improve decision-making based on outcomes
The open-source implementation, available at https://github.com/aishwaryyasarkar/rudder-llm-agent, provides researchers and practitioners with access to this transformative technology.
Broader Implications for AI Systems Design
Rudder's success signals several important shifts in how we approach AI system design:
1. LLMs as System Controllers: This work demonstrates that LLMs can effectively control complex computational processes, not just generate text. Their reasoning capabilities make them suitable for dynamic optimization tasks.
2. Adaptive Systems Architecture: The research highlights the limitations of static optimization in dynamic environments and points toward more adaptive, learning-based control systems.
3. Cross-Paradigm Innovation: By applying natural language processing techniques to distributed systems problems, Rudder exemplifies the creative cross-pollination driving AI advancement.
4. Energy and Resource Efficiency: The dramatic reduction in communication overhead translates directly to energy savings and more efficient resource utilization—critical considerations as AI models grow increasingly large and computationally intensive.
Future Directions and Applications
The Rudder framework opens numerous avenues for future research and application:
- Extension to Other Distributed Systems: The principles could apply to other communication-intensive distributed computations beyond GNN training
- Integration with Emerging Hardware: Combining Rudder's software intelligence with specialized networking hardware could yield even greater improvements
- Multi-Objective Optimization: Future versions could balance performance with other considerations like energy consumption or fairness in resource allocation
- Federated Learning Applications: Similar approaches could optimize communication in privacy-preserving distributed learning scenarios
Challenges and Considerations
While Rudder represents a significant advance, several challenges remain:
- Latency of LLM Reasoning: The time required for LLM inference must be balanced against prefetching benefits
- Generalization Limits: While impressive, the system's performance on radically different graph types requires further validation
- Integration Complexity: Deploying such systems in production environments presents engineering challenges
- Resource Requirements: The computational overhead of running LLM agents must be justified by performance gains
Conclusion: A New Paradigm for Distributed AI
Rudder represents more than just an optimization technique—it signals a paradigm shift in how we approach distributed AI training. By treating communication optimization as an adaptive control problem solvable through LLM reasoning, the researchers have demonstrated that the boundaries between different AI subfields are increasingly porous and productive.
As AI systems continue to scale and distributed training becomes the norm rather than the exception, innovations like Rudder will be essential for making these systems practical, efficient, and sustainable. The work also suggests that we've only begun to explore the potential applications of LLMs beyond their original text generation purposes.
The preprint, while not yet peer-reviewed, offers compelling evidence that the future of efficient AI training may depend not just on better algorithms or hardware, but on smarter coordination between computational elements—coordination that increasingly looks like the kind of reasoning we associate with intelligence itself.
Source: arXiv:2602.23556, "Rudder: Steering Prefetching in Distributed GNN Training using LLM Agents"