A new research paper introduces Memory Intelligence Agent (MIA), a framework that addresses the fundamental limitation of static memory systems in AI agents. By treating memory as a living system rather than a passive database, MIA achieves significant performance improvements, including a 9% boost for GPT-5.4 on the challenging LiveVQA benchmark.
The Problem with Static Agent Memory
Current memory-augmented agents typically treat memory as a retrieval problem: store past trajectories, retrieve similar ones when needed, and hope the retrieved context helps with the current task. This approach has two critical flaws:
- Memory becomes stale - As environments and tasks evolve, static memory representations lose relevance
- Storage costs grow without bound - Accumulating raw trajectories creates unsustainable memory overhead
"Memory systems for agents need to evolve, not just accumulate," the researchers note, highlighting the core insight behind their work.
What MIA Does Differently
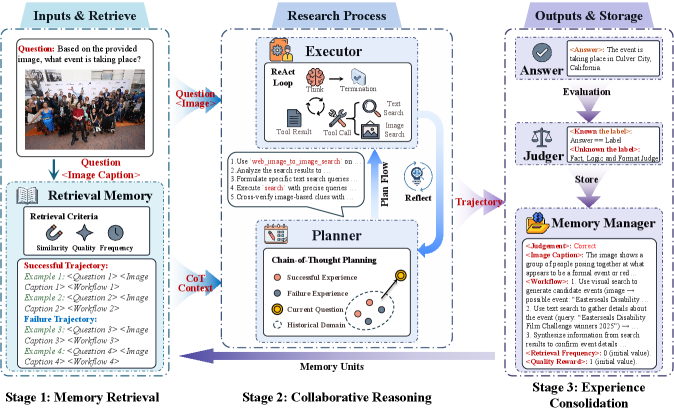
MIA introduces three interconnected components that work together dynamically:
1. Non-parametric Memory Manager
This component handles compressed trajectory storage, efficiently organizing past experiences without the parameter bloat of traditional approaches. It serves as the system's long-term memory, storing experiences in a compressed format that balances detail with storage efficiency.
2. Parametric Planner
Trained via reinforcement learning, the Planner generates search strategies for memory retrieval and utilization. Unlike static retrieval systems, this component learns optimal strategies for when and how to access different types of memory based on the current task context.
3. Executor
This component carries out the planned actions, with the paper demonstrating effectiveness even with lightweight 7B parameter models.
Key Innovation: Bidirectional Memory Conversion
The breakthrough in MIA is its ability to convert between parametric and non-parametric memory representations bidirectionally:
- Parametric → Non-parametric: Learned strategies and patterns can be distilled into compressed memory representations
- Non-parametric → Parametric: Stored experiences can inform and update the Planner's strategies during operation
This bidirectional flow creates a feedback loop where memory informs strategy and strategy informs memory storage, creating what the researchers call a "living system" rather than a static database.
Test-Time Learning: Memory That Evolves During Inference
Most critically, MIA implements test-time learning where the Planner updates on-the-fly during inference. This means the system doesn't just retrieve from memory—it learns from each interaction and updates its strategies in real-time, preventing the staleness problem that plagues static memory systems.
Performance Results
The paper reports substantial improvements across multiple benchmarks:
LiveVQA with GPT-5.4 Up to 9% Challenging visual question answering benchmark Average across 11 benchmarks 31% Using lightweight 7B Executor Comparison to 32B model +18% MIA with 7B Executor outperforms much larger 32B baselineThese results demonstrate that intelligent memory management can provide greater performance gains than simply scaling model size. The 7B MIA system outperforming a 32B baseline by 18% suggests that memory architecture may be as important as parameter count for agent performance.
Technical Implementation Details
The framework's alternating RL training approach allows the Planner to develop increasingly sophisticated memory utilization strategies. During training, the system cycles between:
- Collecting experiences through interaction
- Updating the Planner based on success/failure signals
- Converting valuable patterns into non-parametric memory
- Using enriched memory to inform future planning
This creates a virtuous cycle where better memory leads to better strategies, which in turn lead to more valuable memories being stored.
Why This Matters for AI Agent Development
MIA addresses several critical challenges in agent design:
- Scalability: By compressing trajectories and evolving strategies, MIA avoids the unbounded memory growth problem
- Adaptability: Test-time learning ensures the system remains relevant as tasks and environments change
- Efficiency: The 7B Executor's strong performance suggests memory intelligence can reduce compute requirements
For practitioners building research agents, question-answering systems, or any application requiring long-term context, MIA provides a blueprint for moving beyond simple retrieval-augmented generation toward truly adaptive memory systems.
Limitations and Future Directions
The paper doesn't specify computational overhead of the bidirectional conversion process or training time requirements for the RL-based Planner. Additionally, while the 11-benchmark average improvement is impressive, individual benchmark results would provide clearer guidance on where MIA provides the most value.
Future work could explore:
- Application to multimodal agents beyond language models
- Integration with different RL algorithms for the Planner
- Optimization of the compression algorithms in the Memory Manager
- Deployment in real-world systems with continuous learning requirements
gentic.news Analysis
This research arrives at a critical juncture in agent development. Following OpenAI's GPT-5.4 release in late 2025, which emphasized improved reasoning but maintained traditional memory approaches, the field has been searching for more sophisticated memory architectures. MIA's bidirectional conversion mechanism represents a significant departure from the retrieval-augmented generation (RAG) paradigm that has dominated since 2023.
The 9% improvement on LiveVQA is particularly noteworthy given GPT-5.4's already strong performance on this benchmark. LiveVQA, which tests real-time visual understanding and reasoning, has been a challenging frontier for AI systems. This aligns with our coverage of Google's Gemini 2.5 Pro, which also showed memory-intensive improvements on complex reasoning tasks but through different architectural approaches.
What makes MIA strategically interesting is its efficiency claim. The paper's finding that a 7B model with MIA outperforms a 32B baseline by 18% suggests we may be entering an era where memory architecture innovations provide better returns than pure scale. This could have significant implications for the economics of AI deployment, potentially enabling more capable agents on edge devices or with lower cloud compute costs.
The test-time learning component connects to broader trends in adaptive systems. As we noted in our analysis of Microsoft's AutoGen 2.0 framework, the ability to learn during deployment is becoming increasingly important for real-world applications. MIA's approach of updating the Planner during inference represents a more integrated approach than the separate fine-tuning pipelines common in current systems.
Frequently Asked Questions
How does MIA differ from traditional RAG systems?
MIA moves beyond simple retrieval by implementing bidirectional conversion between parametric (learned) and non-parametric (stored) memory, plus test-time learning that updates strategies during inference. Traditional RAG systems only retrieve from static memory without evolving their retrieval strategies or memory representations based on new experiences.
What benchmarks did MIA improve on besides LiveVQA?
While the paper mentions an average 31% improvement across eleven benchmarks, it specifically highlights LiveVQA with GPT-5.4 (9% improvement) and shows MIA with a 7B Executor outperforming a 32B baseline by 18%. The other ten benchmarks aren't named in the available summary, but the consistent average improvement suggests broad applicability.
Does MIA require retraining the base model like GPT-5.4?
No, MIA appears to work as a framework that augments existing models. The 9% improvement on GPT-5.4 suggests MIA can be applied to pre-trained models without modifying their core parameters, instead working through the Planner and Memory Manager components that interface with the base model.
What are the computational costs of MIA's bidirectional memory conversion?
The paper summary doesn't provide details on computational overhead. This is a key practical consideration—while MIA improves performance, the bidirectional conversion and test-time learning likely add inference latency and memory usage that would need to be evaluated against the performance gains for specific applications.