
NVIDIA's NeMo RL speculative decoding achieves a 1.8× rollout generation speedup on 8B models. The technique projects a 2.5× end-to-end speedup at 235B parameters, cutting RL training wall-clock time by over half.
Key facts
- 1.8× rollout generation speedup at 8B parameters
- Projected 2.5× end-to-end speedup at 235B
- Reduces RL training wall-clock time by over half
- Validated on internal benchmarks by NVIDIA
- Part of NeMo open-source framework
NVIDIA published research showing speculative decoding applied to reinforcement learning (RL) training in NeMo yields significant wall-clock speedups. The key result: a 1.8× faster rollout generation on 8B-parameter models, with a projected 2.5× end-to-end speedup at 235B parameters [According to the source].
Why speculative decoding fits RL

Speculative decoding is a well-known inference-time optimization — a small draft model proposes tokens that a large target model accepts or rejects in parallel. NVIDIA's contribution is applying this to RL rollouts, where the policy model generates trajectories that a reward model scores. The draft model runs on the same GPU, reducing idle time on the large model.
The unique take: this is not a new architecture or training algorithm — it's a systems-level optimization that directly addresses the bottleneck in RL training: generation latency. Most RL-for-LLM work (PPO, GRPO, REINFORCE) spends the majority of time on rollout generation, not gradient updates. Speeding rollouts by 1.8× at 8B translates to roughly halving the total training time for that model size.
Projected gains at scale
NVIDIA projects the speedup grows with model size. At 235B, the end-to-end gain hits 2.5×. This is consistent with the observation that larger models have more headroom for speculative decoding — the draft model's acceptance rate improves because larger models are more predictable in their token choices.
The company validated the approach on internal benchmarks but did not release public benchmark numbers or the draft model architecture. The research is part of NeMo, NVIDIA's open-source framework for building and customizing generative AI models.
Implications for RL training costs
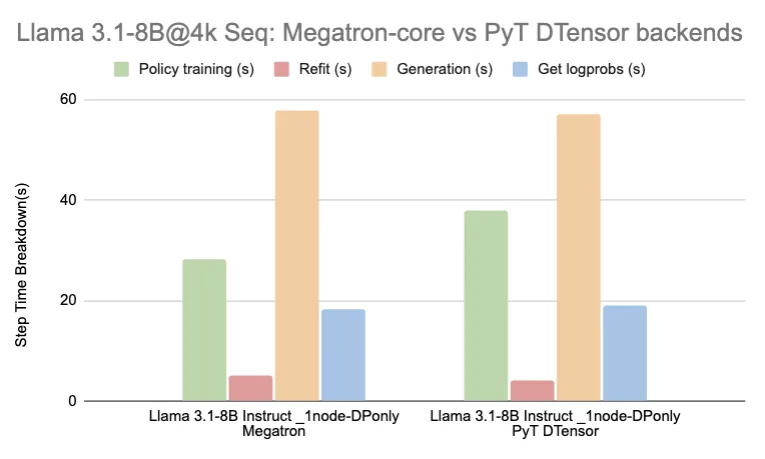
RL training of large language models is compute-intensive. OpenAI, Google DeepMind, and Anthropic all use RL (RLHF, RLAIF) to align models. A 2.5× speedup at 235B could cut the training cost for a frontier model by tens of millions of dollars, assuming the draft model overhead is minimal.
NVIDIA's approach does not change the RL algorithm — it's a drop-in optimization for NeMo users. The company has not announced a release date for the feature.
What to watch
Watch for NVIDIA to release the feature in a NeMo update, likely at or before GTC 2027 in March. Also track whether competitors (Google with Gemini, Meta with LLaMA) publish similar speculative decoding benchmarks for RL training.








