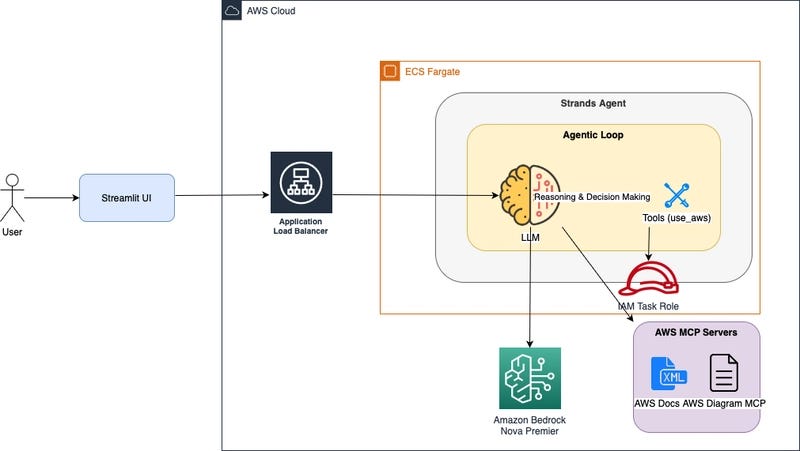
NVIDIA has released Audio Flamingo Next, a new open-source audio-language model positioned as a significant advancement in multimodal AI. The model's headline features are its ability to process 30-minute audio inputs and perform time-grounded reasoning, allowing it to understand and reference specific moments within long-form audio. Trained on a massive dataset of over 1 million hours of audio, NVIDIA claims it outperforms larger models on tasks involving speech, sound, and music understanding.
Key Takeaways
- NVIDIA has launched Audio Flamingo Next, a next-generation open audio-language model supporting 30-minute audio inputs and time-grounded reasoning.
- Trained on over 1 million hours of data, it reportedly outperforms larger models on key audio understanding benchmarks.
What's New: Long-Context Audio Understanding
The primary technical leap with Audio Flamingo Next is its extended context window for audio. While many existing audio models are limited to clips of a few minutes, this model can ingest and reason about audio sequences up to 30 minutes long. This enables applications like analyzing full meetings, lectures, podcasts, or musical compositions in a single pass.
A core architectural feature enabling this is time-grounded reasoning. The model can identify, reference, and answer questions about specific temporal segments within the audio (e.g., "What was said at the 12-minute mark?"). This moves beyond simple classification or transcription to deep, temporally-aware comprehension.
Technical Details & Performance Claims
According to the announcement from NVIDIA, the model was trained on a diverse corpus exceeding 1 million hours of audio data. This likely includes a mix of speech, environmental sounds, and music. The "open" designation suggests the model weights or code will be made available to the research community, continuing NVIDIA's trend of releasing foundational models like Nemotron and contributing to open projects.
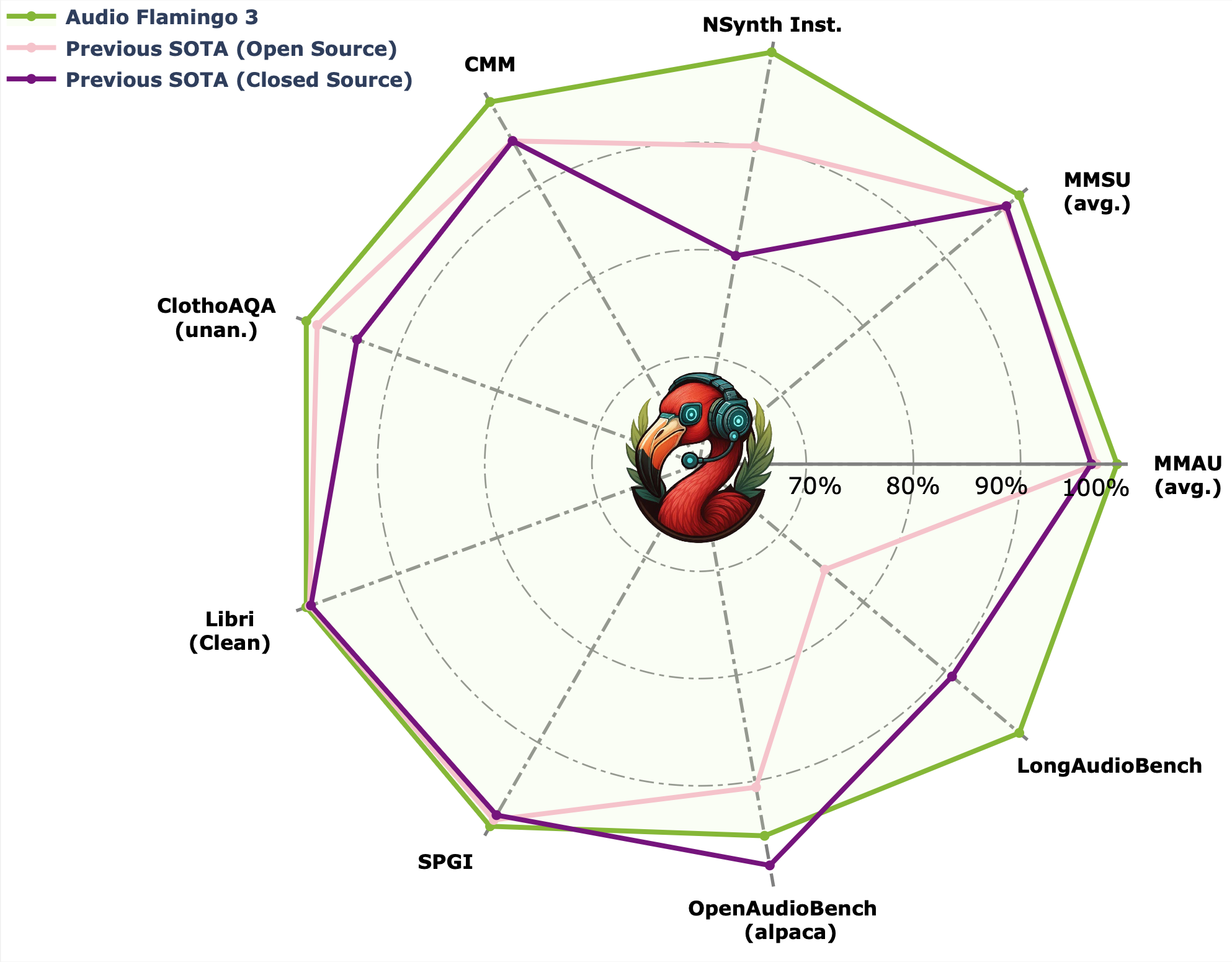
NVIDIA states that Audio Flamingo Next "outperforms larger models on speech, sound, and music understanding." This implies benchmark results where a more efficiently designed, potentially smaller model surpasses larger, less specialized counterparts on specific audio tasks. However, the announcement tweet does not cite specific metrics, datasets (like AudioCaps, Clotho, or LibriSpeech), or model sizes for comparison.
How It Works: The Flamingo Architecture Evolution
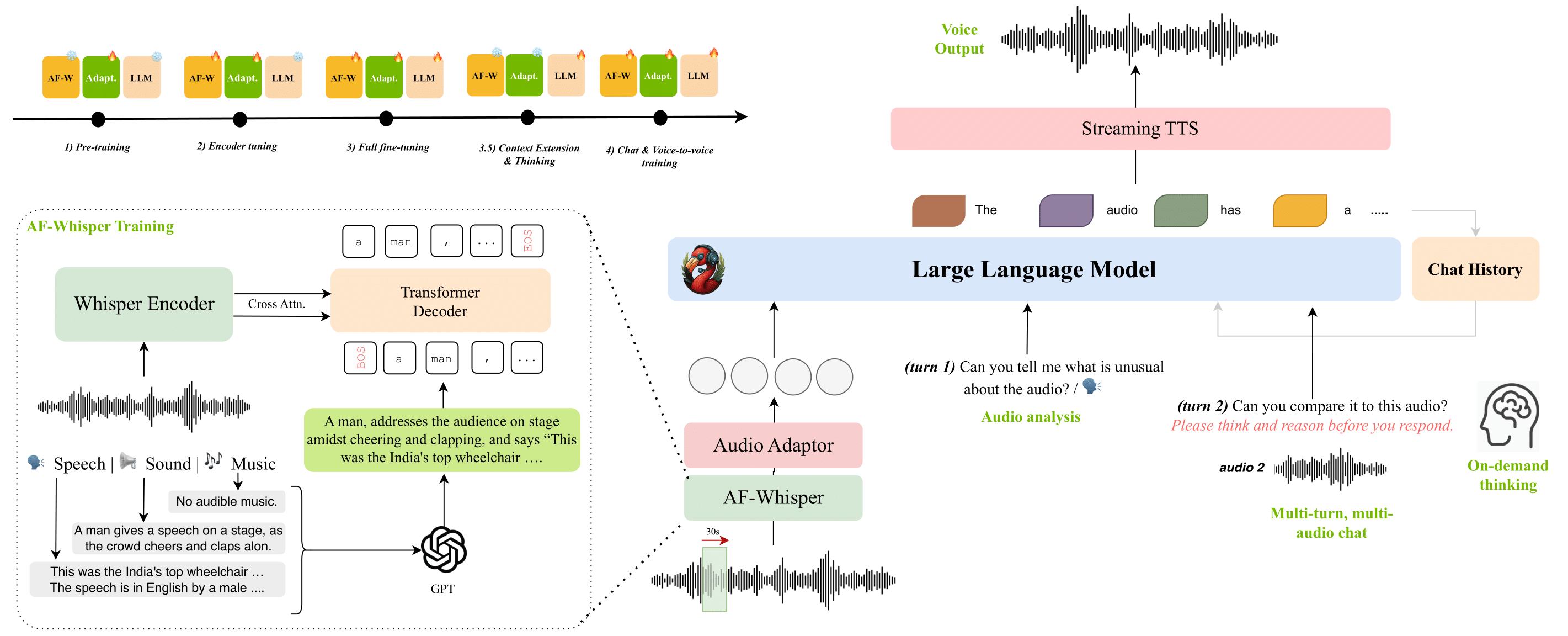
Audio Flamingo Next builds upon the Flamingo family of vision-language models, originally developed by DeepMind. The Flamingo architecture is known for its efficient few-shot learning capabilities, achieved by fusing pretrained vision encoders and language models with novel cross-attention layers.
For Audio Flamingo, the vision encoder is replaced with an audio encoder (likely a pretrained model like Whisper or CLAP). The key innovation is adapting the cross-modal perceiver blocks to handle long, sequential audio data and to learn temporal alignments between audio features and text tokens. The "time-grounded" capability likely stems from the model learning to associate text queries with specific temporal embeddings or attention masks over the audio sequence.
Potential Applications & Limitations
Applications:
- Long-form Content Analysis: Automated summarization and Q&A for lectures, earnings calls, and legal proceedings.
- Advanced Audio Search: Finding specific moments in podcasts or video archives using natural language.
- Accessibility Tools: Creating detailed, navigable transcripts for deaf and hard-of-hearing users.
- Music AI: Analyzing song structure, identifying instruments or themes, and generating descriptive metadata.
Limitations & Open Questions:
- The announcement lacks published benchmarks, making independent verification of the "outperforms larger models" claim impossible for now.
- The computational cost of processing 30-minute audio contexts during inference is not specified.
- The exact openness of the model (full weights, code, or a limited license) is unclear from the initial tweet.
gentic.news Analysis
NVIDIA's release of Audio Flamingo Next is a strategic move to solidify its position as a provider of full-stack AI infrastructure, from hardware (H100/B100 GPUs) to foundational software models. By open-sourcing a state-of-the-art audio model, they are seeding the ecosystem with tools designed to run efficiently on their hardware, encouraging development that locks into their platform. This follows their successful playbook with vision models and frameworks like Omniverse.
This launch directly challenges other major players in the audio-AI space. OpenAI's Whisper dominates speech transcription but is not natively a long-context, reasoning model. Google's USM and Meta's AudioCraft families focus on speech and music generation, respectively. Audio Flamingo Next carves out a distinct niche by combining long-context understanding with reasoning, a combination we've seen gain traction in text (Claude, GPT-4) and is now logically extending to audio.
The emphasis on "time-grounded reasoning" is the most technically significant aspect. It addresses a fundamental weakness in most multimodal models: poor temporal grounding. A model can describe a video or audio clip, but pinpointing when something happens is a harder alignment problem. NVIDIA's claim suggests they've made meaningful progress here, which would have ripple effects for video understanding models as well.
For practitioners, the key signal is the shift from audio classification/transcription to audio reasoning. The next wave of audio AI applications won't just be "what is this sound?" but "what happened in this 30-minute file, and at what times?" Developers should monitor the model's release for fine-tuning capabilities and API latency, as these will determine its practical utility versus more established, narrower audio tools.
Frequently Asked Questions
What is Audio Flamingo Next?
Audio Flamingo Next is an open-source audio-language model developed by NVIDIA. It can process and understand audio clips up to 30 minutes long, answering questions and performing reasoning tasks with specific references to timestamps within the audio.
How does Audio Flamingo Next differ from OpenAI's Whisper?
Whisper is primarily a robust speech recognition (transcription) model. Audio Flamingo Next is a multimodal reasoning model that understands not just speech, but also environmental sounds and music. It goes beyond transcription to perform question-answering, summarization, and temporal grounding based on audio content.
What does "time-grounded reasoning" mean?
Time-grounded reasoning means the model can understand and reference specific moments in time within a long audio sequence. For example, you can ask, "What did the speaker say about the budget 15 minutes into the call?" and the model can identify and respond based on that exact segment.
When will Audio Flamingo Next be available?
The initial announcement was made via a research tweet. Typically, NVIDIA follows such announcements with a detailed paper, benchmark results, and the release of model weights or code on platforms like Hugging Face or GitHub in the following days or weeks. Developers should watch NVIDIA's AI research pages for the official release.