
A report from The Wall Street Journal, highlighted by AI researcher Rohan Paul, reveals a staggering internal projection from OpenAI: the company is forecasting its spending on AI research hardware alone will reach $121 billion in 2028.
This figure, which pertains solely to compute infrastructure for research and development, underscores the unprecedented capital intensity required to build and train frontier AI models. The report notes that this forecast comes even as the company's sales are expected to double in 2025, suggesting that revenue growth is being rapidly outpaced by the escalating costs of compute.
Key Takeaways
- OpenAI is forecasting its own AI research hardware costs will reach $121 billion in 2028, according to a WSJ report.
- This figure highlights the extreme capital intensity required to compete at the frontier of AI.
The Scale of the Spend
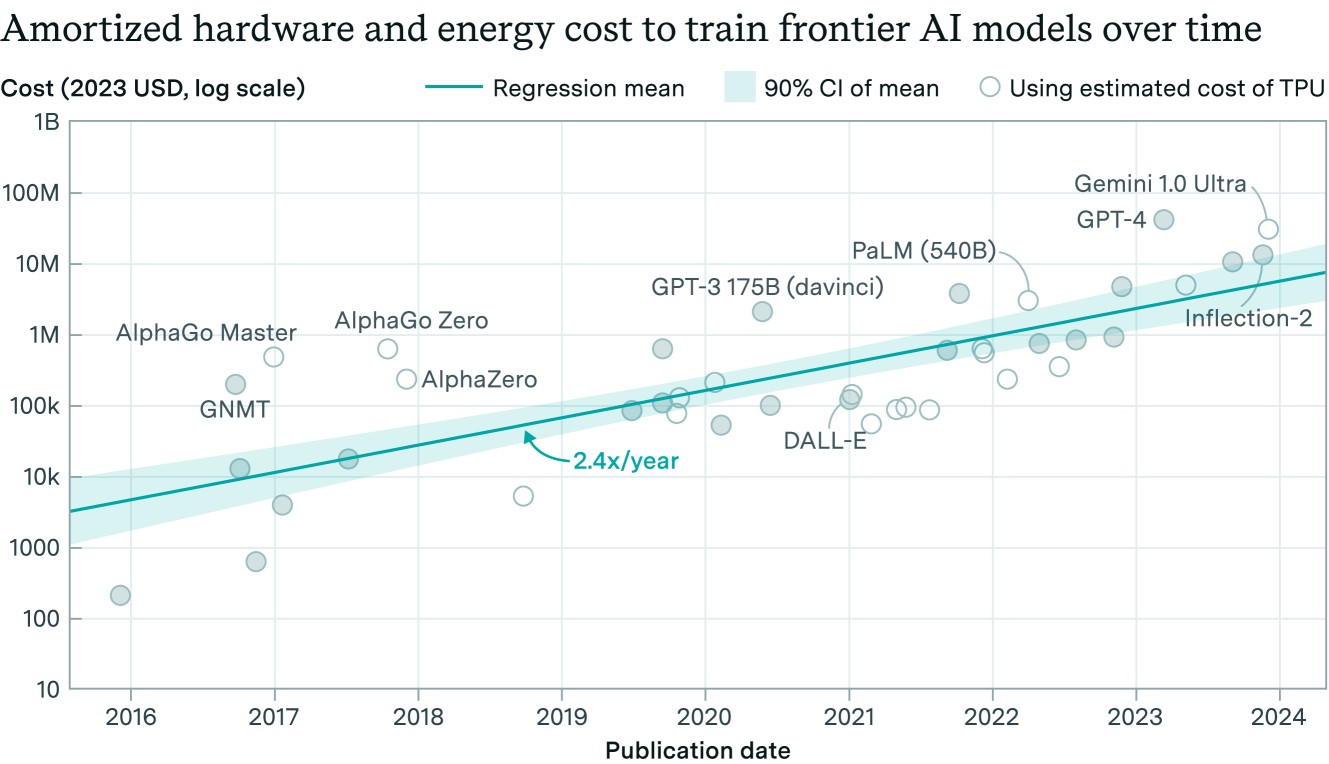
The $121 billion projection is not for total operational costs, but specifically for the hardware—primarily GPUs and associated data center infrastructure—needed to power OpenAI's research efforts. To put this in perspective:
- Nvidia's total revenue for its most recent fiscal year was approximately $110 billion.
- The entire global semiconductor industry's capital expenditure in 2024 was estimated at around $230 billion.
OpenAI's forecast suggests it expects to consume a significant portion of the world's leading-edge AI chip supply within just a few years.
The Capital Intensity of Frontier AI
This projection crystallizes a trend our readers have been tracking: the cost of staying at the cutting edge of AI is growing exponentially, not linearly. Training runs for models like GPT-4, Claude 3 Opus, and Gemini Ultra are already estimated to cost hundreds of millions of dollars. The next generation, aiming for artificial general intelligence (AGI), is expected to require orders of magnitude more compute.
This spending forecast implies several strategic realities:
- Vertical Integration Pressure: Costs of this magnitude will force leading AI labs to seek greater control over their hardware supply chain, from custom silicon to data center design.
- High Barrier to Entry: It effectively prices out all but a handful of well-capitalized entities (like OpenAI, Google, Meta, and perhaps a few nation-states) from the race for AGI.
- Revenue Model Strain: It raises urgent questions about the business models needed to support such burn rates, pushing companies toward enterprise licensing, API consumption, and potentially consumer subscription services at scale.
Context: The AI Compute Arms Race

OpenAI's forecast is the latest data point in an intensifying global scramble for AI compute. This follows:
- Microsoft's and OpenAI's "Stargate" supercomputer project, reportedly a $100 billion+ data center initiative targeting 2028.
- Meta's commitment to amass 600,000 H100-equivalent GPUs by the end of 2024.
- Google's and Amazon's massive internal investments in TPUs and Trainium chips, respectively.
- Nvidia's record-breaking revenue, driven almost entirely by demand from these few hyperscalers and AI labs.
The $121 billion figure suggests OpenAI believes it must match or exceed the infrastructure scale of its largest competitors, who also control their own cloud platforms (Azure, GCP, AWS).
gentic.news Analysis
This forecast, if accurate, represents a pivotal moment in the industrialization of AI research. It moves the conversation from millions and billions of dollars in training costs to hundreds of billions in sustained capital expenditure. This isn't just about buying more GPUs; it's about financing the construction of a new global utility—AGI-grade compute.
This aligns with our previous coverage of the "Stargate" supercomputer project and the soaring valuation of AI infrastructure companies. It confirms a core thesis: the 2025-2030 period will be defined by a compute arms race where financial capital and energy access are the primary constraints, not algorithmic ingenuity alone.
For practitioners, the implication is stark: research directions that are not compute-efficient may become financially untenable. There will be intense pressure to improve training and inference efficiency, likely accelerating investment in techniques like mixture-of-experts, speculative decoding, and novel neural architectures. The center of gravity in AI is shifting decisively from software to hardware and capital markets.
Furthermore, this forecast contradicts any notion of AI development costs plateauing. It suggests OpenAI's leadership believes successive generations of models will require exponentially more resources, a bet that will either cement their dominance or risk catastrophic financial overextension. The next few years will test whether the market's appetite for AI services can grow fast enough to fund these ambitions.
Frequently Asked Questions
What does "AI research hardware" include?
It primarily includes the processors (like GPUs or custom AI accelerators), the networking equipment (like InfiniBand), and the data center infrastructure (power, cooling, racks) required to train and run large-scale AI experiments. It is the core compute capital, not operational costs like salaries or cloud credits.
How does OpenAI plan to pay for this?
The report does not specify, but the primary avenues would be: 1) Reinvesting massive revenue growth from products like ChatGPT Enterprise and API usage, 2) Further multi-billion-dollar funding rounds from Microsoft and other investors, and 3) Debt financing secured against future revenue streams or assets.
Is $121 billion a realistic number?
While staggering, it is consistent with the trajectory of model scaling laws and the confirmed plans of other tech giants. When considering the planned "Stargate" supercomputer and the need to train not one but multiple successor models to GPT-4 between now and 2028, the figure, while extreme, is within the realm of possibility given the current pace of investment.
What does this mean for smaller AI companies and researchers?
It raises the barrier to entry for training frontier models to an almost insurmountable level. However, it may create opportunities in adjacent areas: developing highly efficient small models, focusing on fine-tuning and deployment of large models, or creating tools and services for the massive AI infrastructure being built.







