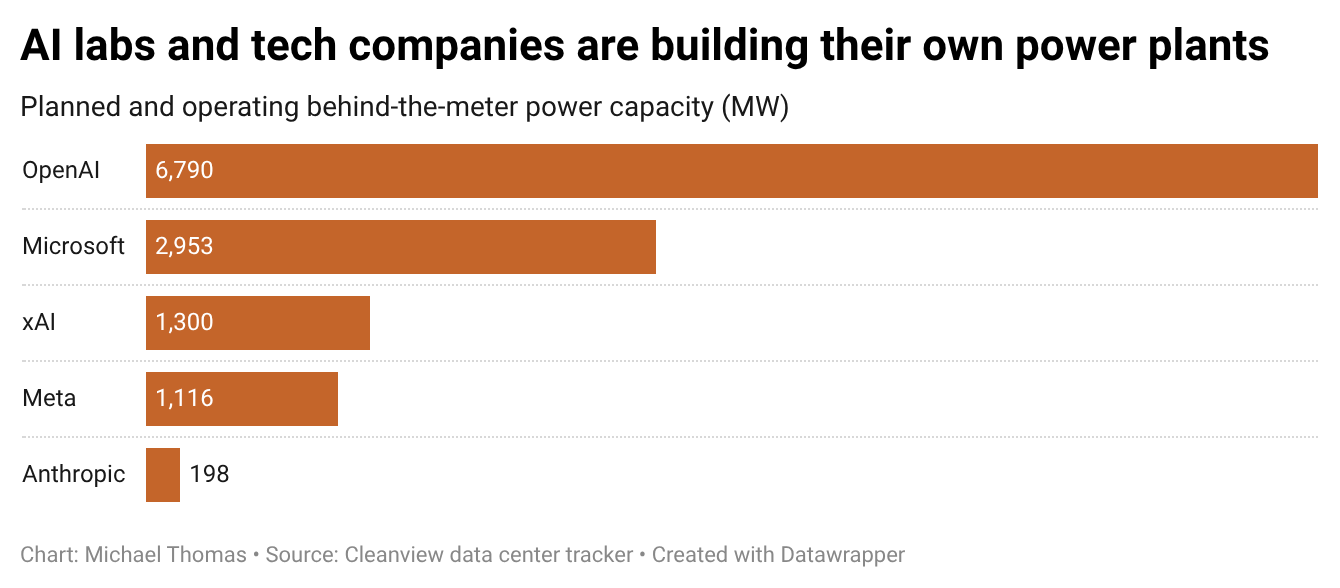
OpenAI researchers trained a model via RL on 'beneficial traits' like truthfulness and corrigibility, improving 44 of 53 safety benchmarks. The method, which differs from Anthropic's constitution-based approach, also made models resistant to harmful fine-tuning and adversarial prompts.
Key facts
- Model improved on 44 of 53 safety benchmarks.
- Training on health data improved non-health evaluations like reward hacking.
- Adversarial prompts had far less effect on beneficial-trait model.
- Method differs from Anthropic's constitutional approach.
- Researchers call it 'selective persistence' — resists harmful steering.
OpenAI has published a new alignment technique that uses small doses of reinforcement learning (RL) on specific behavioral traits — truthfulness, epistemic humility, corrigibility, transparency in reasoning, fairness, and concern for human well-being — to make models safer across domains. According to The Decoder, the researchers trained the model on realistic conversations covering healthcare, education, science, law, and engineering, mixing only a small share of this 'beneficial trait' data into the regular RL post-training pipeline.
Generalization across domains
The model improved on 44 out of 53 independent benchmarks measuring deception, honesty, sycophancy, reward hacking, and health and mental health scenarios. Training on health data alone also improved non-health evaluations like reward hacking and deception detection; the reverse held true — training without any health or science data still boosted performance on health benchmarks. The researchers conclude that RL training reinforces basic behavioral patterns that work across domains.
Resistance to adversarial steering
Adversarial prompts that badly destabilized the baseline model had far less effect on the beneficial-trait model. Harmful fine-tuning was also less able to erode the trained traits. The model stayed just as steerable for helpful instructions as before. The researchers call this 'selective persistence' — the model resists harmful steering without losing useful flexibility.
A different path than Anthropic
OpenAI's method differs sharply from Anthropic's alignment approach. OpenAI relies on empirically measurable behavioral traits reinforced through RL in realistic scenarios. Anthropic works with an explicit 'Claude constitution,' a written values document that serves as the top-level guide for training and behavior. OpenAI leans heavily on benchmarks: 44 out of 53 evaluations show improvements that generalize across domains and evaluation methods. Anthropic takes a more principles-based approach where the model is supposed to understand why certain behaviors are desired, grounded in constitutional texts and high-quality training examples. A direct comparison of the two approaches doesn't exist yet.
What this means for alignment research
The finding that small RL doses on desired traits generalize across domains is notable because prior work has shown that misalignment from training on problematic behavior in one domain can spread to other areas. OpenAI's result suggests the reverse also works — good behavior generalizes just as broadly. This could have implications for how AI companies structure their safety training pipelines, potentially reducing the need for exhaustive domain-specific safety data.
Key Takeaways
- OpenAI trained a model via RL on beneficial traits, improving 44 of 53 safety benchmarks.
- The method differs from Anthropic's constitution-based approach and makes models resistant to harmful steering.
What to watch
Watch for a direct benchmark comparison between OpenAI's RL-based approach and Anthropic's constitutional method. No such comparison exists yet, but both labs are likely to publish follow-up work. Also watch for whether OpenAI integrates this technique into GPT-5.3-Codex-Spark or GPT-5.5 Instant.

Source: the-decoder.com