
An arXiv paper (2603.10165) introduces OpenClaw-RL, a system that trains language models on natural conversation feedback instead of labeled datasets. It eliminates the need for human workers to manually gather, review, and score training data.
Key facts
- arXiv preprint 2603.10165.
- Replaces manual labeling with conversation feedback.
- Uses Process Reward Model for evaluative signals.
- Hindsight-Guided On-Policy Distillation for directive signals.
- Training runs in background without pausing tasks.
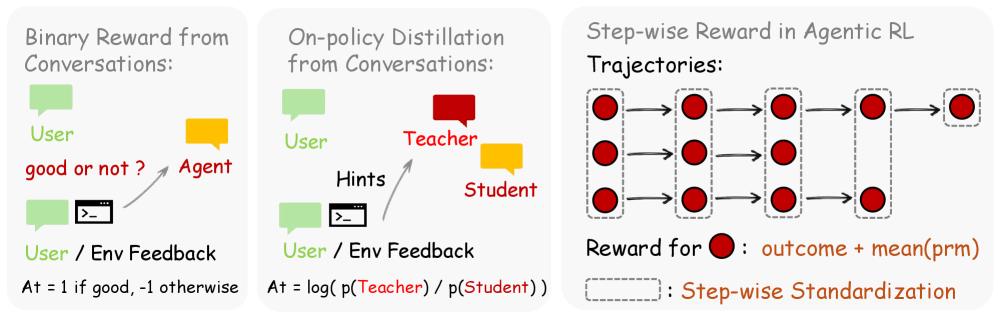
OpenClaw-RL, detailed in a preprint on arXiv (2603.10165) [per @rohanpaul_ai], proposes a method for continuous reinforcement learning from everyday user interactions. The core innovation is replacing the traditional reliance on manually labeled datasets with two signal types extracted from each conversation: evaluative signals (e.g., a user asking the same question again, indicating dissatisfaction) and directive signals (e.g., user corrections, error logs, terminal commands).
Evaluative signals feed into a Process Reward Model judge to produce numerical rewards. Directive signals are converted into word-level supervision through a technique called Hindsight-Guided On-Policy Distillation. This dual-signal approach allows a single policy to learn from diverse interaction types—personal chats, GUI clicks, software tasks—simultaneously.
The training runs in the background, meaning the model never pauses its normal operations to learn. By treating standard deployment as a continuous learning environment, the system adapts to individual user preferences without any manual data labeling. The paper claims this completely removes the traditional need for human workers to manually gather, review, and score massive datasets.
The Unique Take
OpenClaw-RL flips the dominant RL paradigm: current systems (like RLHF) discard natural feedback because they only care about final outcome success or failure. This paper argues that's akin to a student throwing away a teacher's notes after seeing a grade. By capturing both evaluative and directive signals, it extracts far more signal per interaction than binary reward models.
Limitations
While promising, the paper does not disclose benchmark results (e.g., SWE-Bench, HumanEval) comparing OpenClaw-RL against standard RLHF or supervised fine-tuning. The authors also do not specify the base model used, training compute, or dataset sizes. These omissions make it difficult to assess practical gains.
Key Takeaways
- OpenClaw-RL trains AI agents on natural conversation feedback, removing manual labeling.
- Uses evaluative and directive signals for continuous learning.
What to watch
Watch for benchmark evaluations (SWE-Bench, HumanEval) comparing OpenClaw-RL against RLHF and supervised fine-tuning, and for the authors to release code or model weights. If results show >10% improvement on software tasks, expect rapid adoption in AI agent deployment pipelines.








