A new academic paper with a provocative title seeks to cut through the hype and ambiguity surrounding Artificial General Intelligence (AGI) by proposing a concrete, capability-based definition. Titled "What the F*ck Is Artificial General Intelligence?" (arXiv:2503.23923), the work argues that AGI should be understood not as "human-level AI" but as an "artificial scientist"—a system judged by its ability to discover and adapt across many domains with autonomy.
The core argument moves the goalpost from performing well on static benchmarks to possessing a foundational capacity for general adaptation under constraints. The authors define intelligence as "adaptability under limits of compute, memory, and energy." Therefore, AGI is a system that can adapt "at least as generally as a human scientist."
Key Takeaways
- A new paper defines AGI as an 'artificial scientist'—a system that adapts as generally as a human scientist under computational limits.
- This reframes the goal from passing benchmarks to autonomous planning, causal learning, and exploration.
What the Paper Proposes
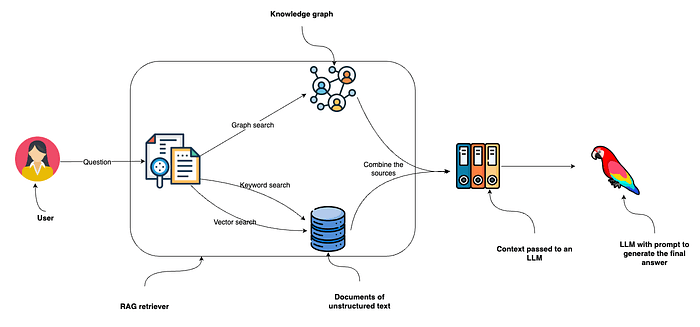
The paper contends that the prevailing benchmarks for AGI—such as passing the Turing test, achieving human-level performance on specific exams, or matching broad cognitive abilities—are insufficient. These measure snapshots of capability, not the underlying, general-purpose adaptive engine.
Instead, the authors propose evaluating AGI by a system's ability to function as an autonomous scientist. This entails:
- Planning and executing experiments to gather new information.
- Learning cause-and-effect relationships from data and interaction.
- Balancing exploration (trying new things) with exploitation (using known strategies).
- Operating with significant autonomy to pursue defined goals.
The "artificial scientist" is not necessarily an AI that writes academic papers, but one that embodies the scientific method as a core adaptive process. Its intelligence is measured by the breadth and efficiency of its adaptation, not by its mimicry of human test-taking.
Why This Definition Matters
This reframing has direct implications for AI research and evaluation:
- Shifts Benchmark Focus: It argues against chasing higher scores on static datasets (like MMLU or GPQA) and towards developing and testing meta-capabilities like experimental design and causal reasoning in novel environments.
- Emphasizes Efficiency: By baking compute, memory, and energy constraints into the definition of intelligence, it highlights sample efficiency and resource-aware learning as core AGI components, not just afterthoughts.
- Clarifies the Target: The vague "human-level" goal is replaced with a more specific, albeit still extremely ambitious, target: the generalized adaptive prowess of a human scientist. This provides a clearer, if not easier, research direction.
The paper enters a crowded field of AGI definitions. It stands in contrast to benchmarks like ARC-AGI (which focuses on novel task generalization) or Chinchilla's laws (which focus on scaling), by prioritizing the process of autonomous discovery over the outcome on predefined tasks.
gentic.news Analysis

This paper is a direct contribution to the ongoing, critical debate about AGI benchmarks and definitions, a topic gentic.news has covered extensively, including in our analysis of Meta's "AGI Sparks" framework and OpenAI's "Levels" classification system. Unlike corporate taxonomies often tied to product roadmaps, this academic work attempts a first-principles, capability-driven definition.
The proposed shift towards an "artificial scientist" aligns with observable trends in frontier AI research. The intense focus on reasoning, planning, and agentic workflows—evident in projects like Google's Gemini Advanced with planning modules, OpenAI's o1 models, and xAI's Grok-3—shows the industry is already investing in the components the paper describes. The definition essentially formalizes the high-level goal of this entire research vector.
However, the definition's practicality is an open question. How does one quantitatively measure "adaptation as generally as a human scientist"? While more precise than "human-level," it risks remaining a qualitative, philosophical benchmark. The field still lacks the equivalent of a "Science-Bench"—a rigorous, scalable suite of tasks to evaluate autonomous discovery. Until such benchmarks are developed and widely adopted, the "artificial scientist" definition may serve more as a north star for researchers than as a concrete evaluation tool for engineers.
Frequently Asked Questions
What is the new definition of AGI proposed in the paper?
The paper defines AGI as an "artificial scientist"—a system that can adapt as generally and efficiently as a human scientist under constraints of computation, memory, and energy. This means it must be capable of autonomous experimental planning, learning cause-and-effect, balancing exploration with action, and operating independently across a wide range of novel tasks.
How is this different from other definitions of AGI?
Most common definitions measure AGI against human performance on specific tests or tasks (like passing the Turing test or scoring highly on professional exams). This definition moves away from static, human-mimicking benchmarks. Instead, it focuses on the underlying, general-purpose process of adaptation and discovery that allows a human scientist to tackle unknown problems, which the authors argue is the true hallmark of intelligence.
What are the main criticisms of current AGI benchmarks?
The paper implies that current benchmarks are flawed because they test performance on known, static datasets. This rewards pattern recognition and interpolation within a fixed distribution but does not adequately measure an AI's ability to generate novel hypotheses, design experiments to test them, understand causality, or adapt efficiently to truly unforeseen challenges—which are core to general intelligence.
What would an AI system built to this definition look like?
It would likely be a highly autonomous agentic system. Instead of just answering prompts, it would be given a high-level goal (e.g., "discover a new catalyst for carbon capture") and would autonomously plan a research strategy, simulate or run experiments, analyze results, form new hypotheses, and iterate—all while managing its computational budget. It's less like a chatbot and more like a self-driving lab or a fully autonomous research assistant.