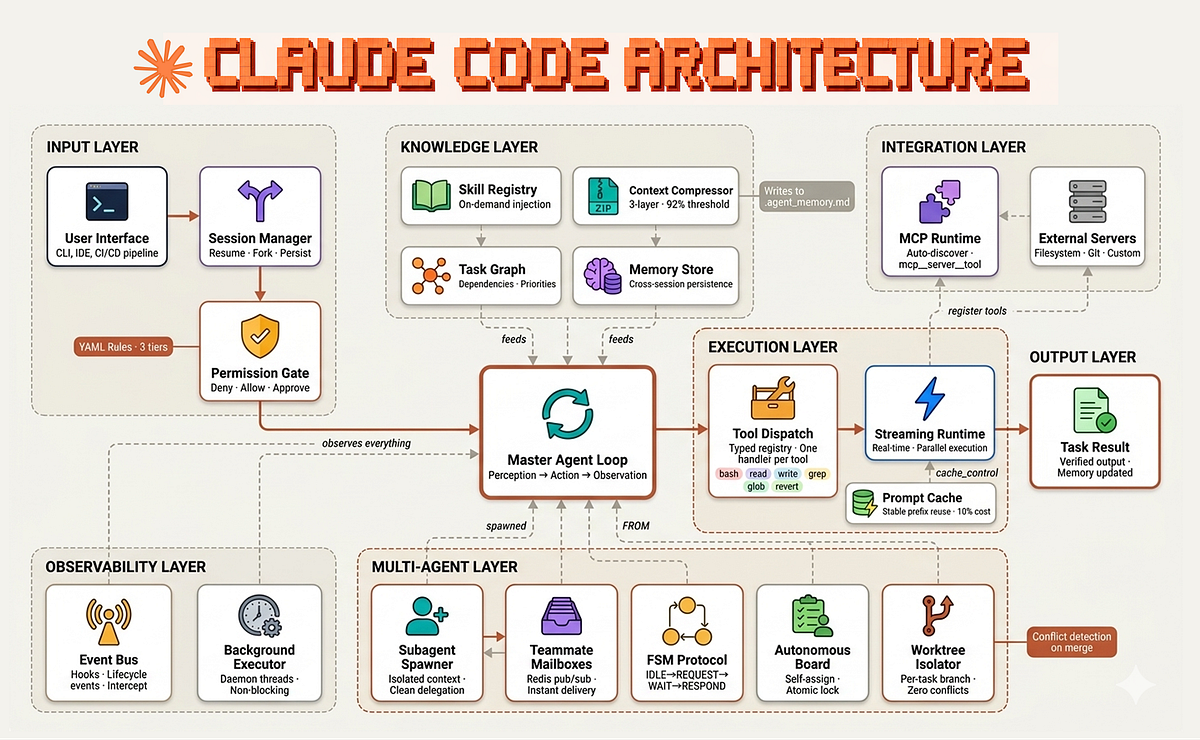
In a groundbreaking study that examines how humans interact with artificial intelligence, Anthropic has uncovered a concerning psychological phenomenon: the more polished and fluent AI-generated content appears, the less likely users are to question its accuracy or verify its claims. The company's newly developed AI Fluency Index (AFI)—a metric derived from analyzing nearly 10,000 anonymized conversations with its Claude models—reveals that users' critical engagement drops significantly when faced with professionally formatted outputs.
The AI Fluency Index: Measuring Human-AI Interaction
Anthropic's research team developed the AI Fluency Index as a comprehensive framework for understanding how effectively users collaborate with AI systems. The index measures several dimensions of interaction, including prompt quality, iteration patterns, verification behaviors, and outcome success rates. By analyzing thousands of real-world conversations, researchers identified clear patterns in how users approach AI-generated content.
The most striking finding emerged around verification behaviors. When Claude produced polished outputs like complete documents, small applications, or professionally formatted reports, users were 3.7 percentage points less likely to fact-check the information or question underlying assumptions. This verification gap represents a significant shift in user behavior based purely on the presentation quality of AI-generated content.
The Presentation-Accuracy Disconnect
Human psychology has long recognized the "halo effect"—where attractive or professional presentation creates positive assumptions about underlying quality. Anthropic's research demonstrates this phenomenon now extends to human-AI interactions with potentially serious consequences. Users appear to unconsciously equate polished formatting with factual accuracy, even when dealing with complex technical or factual content.
This finding is particularly relevant as AI systems like Claude Opus 4.6 (Anthropic's latest model) become increasingly capable of producing outputs that rival human professionals in formatting and stylistic polish. The very improvements that make AI more useful—better formatting, more natural language, cleaner code structure—may simultaneously make users less vigilant about verifying the substance of that output.
The Iteration Paradox
The AI Fluency Index revealed another important insight: iteration is the strongest predictor of successful AI use. Users who engaged in multiple rounds of refinement with Claude consistently achieved better outcomes than those who accepted initial responses. However, this beneficial behavior comes with its own tradeoff—extended iteration sessions showed a gradual decline in verification behaviors as users developed trust in the AI's capabilities.
This creates a fundamental tension in human-AI collaboration. The most effective way to use AI systems involves iterative refinement, yet this very process may erode the critical thinking necessary to catch subtle errors or factual inaccuracies that persist through multiple iterations.
Implications for AI Development and Deployment
Anthropic's findings have significant implications for how AI companies design their systems and how organizations implement AI tools:
For AI Developers: The research suggests that simply making AI outputs more polished might inadvertently reduce their reliability in practice. This raises important questions about whether AI systems should include more explicit uncertainty indicators or verification prompts when presenting complex information. Some researchers have suggested that "appropriate roughness" in AI outputs—maintaining some stylistic imperfections—might actually improve outcomes by keeping users critically engaged.
For Organizations: Companies implementing AI tools need to develop new training protocols that specifically address verification behaviors. Rather than focusing solely on prompt engineering, effective AI training must include critical evaluation skills and verification protocols. Organizations may need to implement mandatory verification steps for AI-generated content in high-stakes domains like legal documents, medical information, or financial analysis.
For Individual Users: The research serves as an important reminder that professional presentation doesn't equal factual accuracy. Users need to maintain their critical faculties even when AI produces impressively formatted outputs. Developing the habit of verification—especially for polished outputs—should become a standard part of working with AI systems.
The Broader Context of AI Trust and Verification
Anthropic's research contributes to a growing body of literature examining how humans form trust relationships with AI systems. Previous studies have shown that users tend to over-trust AI recommendations in various domains, from medical diagnosis to financial planning. The AI Fluency Index findings extend this understanding by showing how presentation quality specifically affects verification behaviors.
This research comes at a critical moment in AI development. As models like Claude, GPT-4, and others become more integrated into professional workflows, understanding the psychological dynamics of human-AI interaction becomes increasingly important for both safety and effectiveness.
Future Research Directions
Anthropic's initial findings raise several important questions for future research:
- How does this phenomenon vary across different types of content (code vs. prose vs. data analysis)?
- Do different user demographics show different susceptibility to the polished output effect?
- Can interface design mitigate this effect without reducing the utility of polished outputs?
- How does this dynamic change as users gain more experience with AI systems?
Conclusion: Toward More Critical AI Collaboration
Anthropic's development of the AI Fluency Index represents an important step toward more sophisticated understanding of human-AI interaction. By moving beyond simple performance metrics to examine how users actually engage with AI systems, researchers can develop better tools and practices for effective collaboration.
The finding that polished outputs reduce verification highlights a fundamental challenge in AI development: how to create systems that are both highly capable and that encourage appropriate human oversight. As AI systems become more fluent and polished, both developers and users must work consciously to maintain the critical engagement necessary for safe and effective use.
Source: Anthropic's analysis of nearly 10,000 Claude conversations as reported by The Decoder