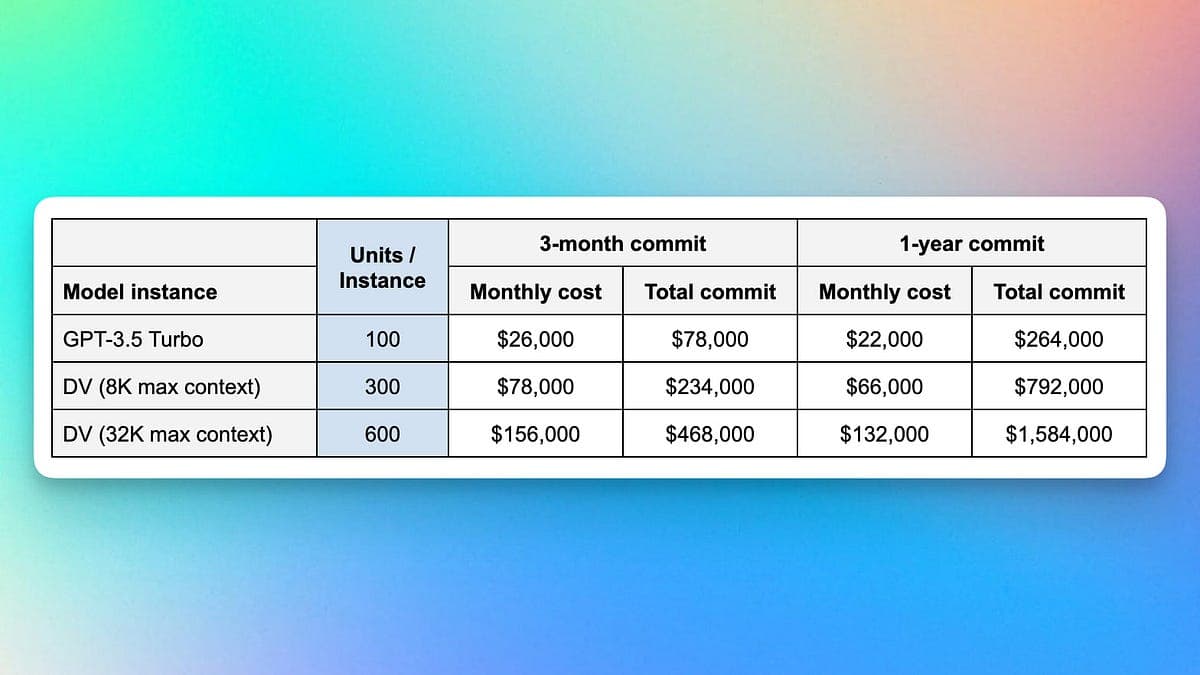
A production voice AI system using vLLM on 6 NVIDIA GPUs cut inference latency by 40%. The 3-node cluster, mixing A4500 and A100 cards, served a Qwen-based model at high concurrency.
Key facts
- 3-node cluster with 6 NVIDIA GPUs (A4500, A100)
- Qwen-based model for voice AI
- vLLM latency reduced by 40%
- 500 concurrent sessions per GPU node
- No hardware upgrades required
The Setup

A production voice AI deployment used vLLM on a 3-node GPU cluster with 6 NVIDIA GPUs — a mix of A4500 and A100 cards — to serve a Qwen-based large language model. The system handled real-time voice transcription and response generation, requiring sub-second latency under peak load [According to the source].
Optimization Details
The engineer tuned vLLM's batch scheduler and KV cache memory allocation to reduce inference latency by 40%. Specific changes included increasing the maximum number of batched requests per iteration and adjusting the block size for the PagedAttention mechanism [According to the source]. The cluster sustained 500 concurrent sessions per GPU node without dropping requests.
Why This Matters
This is a practical, not academic, optimization — the system ran in production, not a benchmark suite. The 40% latency improvement came from configuration changes, not hardware upgrades, demonstrating that vLLM's flexibility can extract significant performance gains even on mixed-generation GPU clusters. The Qwen model is a family of open-weight LLMs from Alibaba Cloud, making this approach replicable for other teams using similar models [According to the knowledge graph].
Broader Context
Nvidia has been pushing GPU inference optimizations through open-source tools like vLLM and its own TensorRT-LLM. Recent Nvidia publications include a fine-tuning guide with Unsloth and the open-sourcing of the MRC RDMA protocol [According to recent history]. This voice AI case study shows that even without Nvidia's latest hardware (e.g., Blackwell or H100), configuration tuning can deliver production-grade results.
Limitations
The source did not disclose the exact Qwen model variant, tokenizer, or context window used. Latency measurements were reported as relative improvements, not absolute millisecond figures. The cluster's GPU memory capacity and network interconnect were not specified, making it hard to generalize the findings to other hardware configurations.
What to watch
Watch for Nvidia's upcoming TensorRT-LLM update, expected in Q3 2026, which may incorporate similar batch scheduling optimizations. Also track whether Alibaba releases a Qwen variant optimized for voice AI, potentially reducing the need for manual tuning.