
Key Takeaways
- An expert article diagnoses the primary reasons RAG systems fail in production, focusing on poor retrieval, lack of proper evaluation, and architectural oversights.
- This is a crucial reality check for teams deploying AI assistants.
What Happened
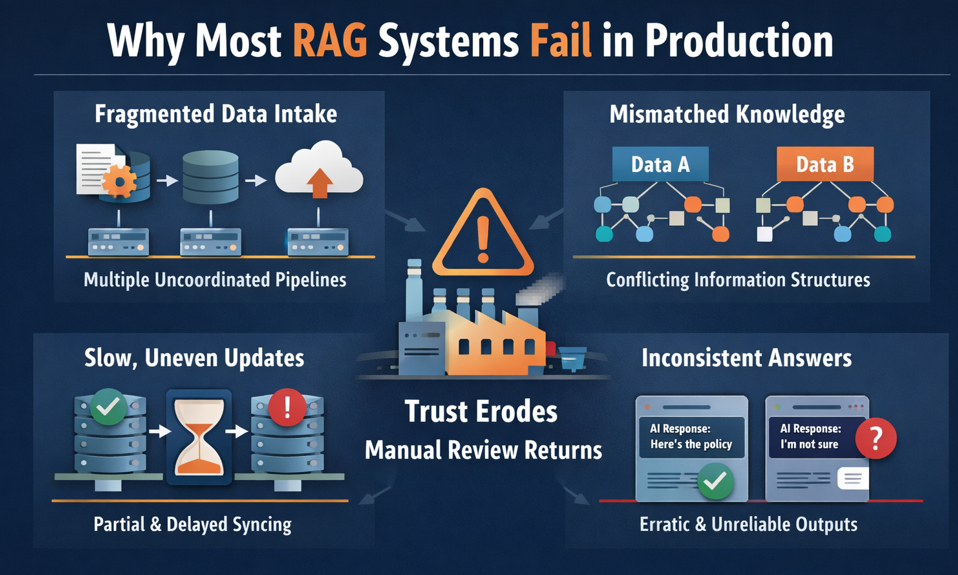
A new analysis published on Medium, titled "Why Most RAG Systems Fail in Production," provides a stark, practitioner-focused critique of the common pitfalls that derail Retrieval-Augmented Generation (RAG) systems after deployment. The article moves beyond the hype of proof-of-concepts to examine the systemic issues—poor context retrieval, inadequate evaluation, and architectural naivety—that cause these AI systems to stumble when real users depend on them.
Technical Details: The Core Failure Points
The article argues that failure is rarely due to the core LLM's intelligence but to the supporting "plumbing" of the RAG pipeline. The primary culprits identified are:
- Ineffective Retrieval: The most common point of failure. Using naive similarity search (e.g., basic vector cosine similarity) on poorly chunked documents often retrieves irrelevant or incomplete context. The system might find a paragraph mentioning a product's "silk blend" but miss the crucial sizing chart or care instructions on the next page, leading to incomplete or wrong answers.
- The Illusion of Evaluation: Teams often rely on superficial metrics like retrieval recall or generic LLM benchmarks (e.g., MMLU) that do not reflect real-world, domain-specific performance. A system might score 95% on a synthetic test but fail to correctly answer a customer's specific question about a boutique's return policy for personalized items.
- Architectural Oversimplification: Treating RAG as a simple "vector store + LLM" combo ignores necessary complexity. Real-world queries are multi-hop ("Find bags similar to this one from last season but in a larger size"), require filtering by metadata (price range, region, collection), or need hybrid search combining keywords with semantic meaning. A simplistic architecture cannot handle this.
- Neglect of Data Quality and Chunking: Garbage in, gospel out. If the source knowledge base—product catalogs, style guides, CRM notes—is inconsistent, outdated, or chunked without regard for semantic boundaries, the retrieval system has no chance of finding the right information.
Retail & Luxury Implications

For retail and luxury brands investing in AI concierges, internal knowledge assistants, or personalized shopping guides, this analysis is a vital blueprint for what not to do.
- Customer-Facing Chatbots: A failed RAG system powering a customer service bot doesn't just return "I don't know." It confidently hallucinates an incorrect delivery date for a limited-edition handbag or provides wrong care instructions for a cashmere sweater, directly damaging brand trust and potentially ruining products.
- Internal Knowledge Management: A RAG system for store associates that fails to retrieve the correct protocol for handling a VIP client's special request or the latest sustainability report data leads to inconsistent service and operational friction.
- Personalization Engines: If the retrieval component of a personalization engine misunderstands a client's past purchases and preferences, it will recommend irrelevant items, wasting a high-value marketing opportunity and annoying the customer.
The gap between a demo that works on curated examples and a production system that handles the messy, varied, and high-stakes queries of luxury retail is vast. This article underscores that bridging it requires meticulous attention to retrieval engineering, not just model selection.
Implementation Approach: Moving Beyond Failure
To avoid these pitfalls, the implied path forward involves:
- Invest in Advanced Retrieval: Move beyond basic vector search. Implement reranking models (like cross-encoders) to re-score initial retrievals for better precision, as highlighted in the related coverage on "Advanced RAG Retrieval." Use hybrid search combining dense vectors with sparse keyword matching and strict metadata filtering.
- Build Domain-Specific Evaluation: Create a rigorous test suite of real user queries (e.g., from customer service logs) and have human experts grade the answers. Track metrics like answer faithfulness (no hallucination), context relevance, and completeness.
- Architect for Complexity: Design the system to handle multi-step reasoning, conditional filtering, and fallback strategies. This may involve an agentic or orchestration layer that decides when to search, when to ask for clarification, and when to escalate to a human—a concept touched upon in the related piece on "Agentic BI Limitations."
- Curate the Knowledge Base: Treat your product data, brand archives, and policy documents as a first-class asset. Implement robust data pipelines for cleaning, structuring, and semantically chunking this information before it ever reaches the vector database.








