LeBonCoin replaced a fine-tuned LLM with a lightweight multimodal transformer, achieving better accuracy at 20-40x fewer parameters.
Key Takeaways
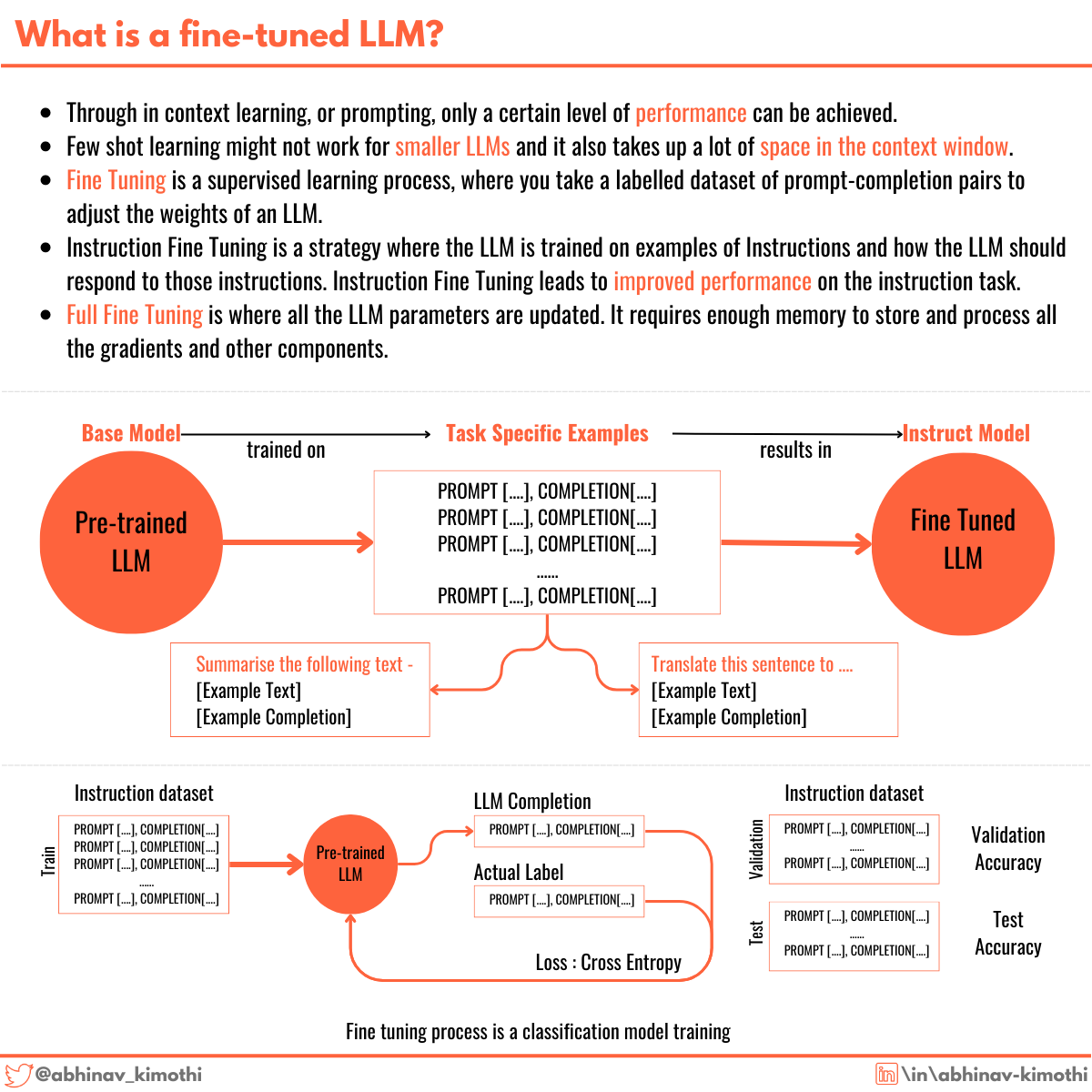
- LeBonCoin's ML team built a custom late-fusion transformer that uses pre-computed visual embeddings and character n-gram text vectors to predict ad attributes.
- It outperformed a fine-tuned VLM while running on CPU with sub-200ms latency, offering calibrated probabilities and 15-minute retraining cycles.
What Happened

Louis-Victor Pasquier, Senior ML Engineer at LeBonCoin (the French classifieds giant), published a detailed technical post describing how his team's custom multimodal transformer outperformed a fine-tuned Vision-Language Model (VLM) for attribute prediction — while being dramatically more efficient.
This is the sequel to a previous post where the team showed that one hour of LLM fine-tuning beat three weeks of RAG engineering. Now they've gone a step further: they replaced the fine-tuned LLM entirely with a purpose-built architecture.
Technical Details
The Problem
LeBonCoin's Cognition team automates ad attribute filling (brand, color, memory capacity, etc.) when users upload items. Text-only classifiers fail when users upload a photo with a sparse title like "Couch for sale." The team needed to "see" the image.
Their fine-tuned VLM solved this but introduced MLOps challenges: massive parameter counts, heavy GPU reliance, and high inference latency from generative autoregressive generation.
The Architecture
Pasquier's insight: the VLM's visual understanding capability could be extracted much more cheaply. LeBonCoin already had a ConvNeXt model fine-tuned on their own images for visual search. He asked: why not just grab those embeddings directly?
The result is a modular, late-fusion transformer:
- Visual Backbone: A 200M-parameter ConvNeXt (fine-tuned on LeBonCoin data) serves as a frozen embedding provider, outputting 700-dimensional vectors for up to 10 images per ad.
- Text Representation: A character-level n-gram count vectorizer (2-5 grams, vocabulary capped at 10,000) — lightweight and robust to typos.
- Fusion Layer: A transformer with only 1.6M parameters. Both text and image vectors are projected into a shared embedding dimension, with a CLS token and learnable modality embeddings to distinguish data types.
- Classification Heads: Independent dense layers for each ad attribute (<100k parameters).
The Results
The custom transformer outperformed the fine-tuned LLM on exact match precision and overall precision across categories like phones and furniture.
Parameter Count: 20x to 40x reduction. The fuser is just 1.6M parameters — less than 1% of the total model size (the ConvNeXt backbone accounts for the rest).
Latency: Transformer inference is sub-10ms. End-to-end (including network calls and embedding extraction) is under 150ms at p95 — all on CPU. The LLM could take several seconds on GPU.
Training Speed: 15 minutes on a 4-CPU machine with 500k samples. Because ConvNeXt embeddings are archived on upload, retraining the fuser is dirt cheap.
Calibrated Probabilities: Unlike LLMs, this model outputs well-calibrated confidence scores, enabling intelligent thresholding and rejection of low-confidence predictions.
Retail & Luxury Implications
This is directly relevant to any e-commerce or marketplace operation that needs to extract structured attributes from user-generated content (ads, listings, product uploads).
Key Lessons for Retail AI Teams
Domain-specific embeddings beat general-purpose models for structured prediction tasks. LeBonCoin's ConvNeXt was fine-tuned on their own images — not ImageNet or LAION-5B.
Generative models are overkill for discriminative tasks. Predicting a sofa's color doesn't require a model trained on the entire internet. This is a critical insight for cost-conscious retail teams.
Calibrated probabilities matter for production systems. If you're auto-filling attributes, you need to know when to abstain (e.g., "I'm 40% confident this is blue"). LLMs struggle with this.
Latency is a UX issue. Sub-200ms on CPU means real-time attribute prediction as users upload photos. Several seconds on GPU would degrade the experience.
Where This Applies
- Luxury resale platforms (Vestiaire Collective, The RealReal): Auto-filling brand, condition, color, material from user photos
- E-commerce marketplaces (Farfetch, Net-a-Porter): Product listing enrichment at scale
- Inventory management: Extracting attributes from supplier catalogs
- Visual search: This architecture could be adapted for retrieval-augmented attribute prediction
The Maturity Gap
This is a production-proven approach at LeBonCoin scale (millions of ads per week). However, it requires:
- A pre-existing domain-specific visual backbone (or the compute to train one)
- Clean attribute taxonomies
- Labeled training data for classification heads
For luxury retailers with complex attribute hierarchies (e.g., "Burgundy calfskin leather" vs. "Burgundy suede"), the classification head design would need careful attention.
Business Impact
Cost Savings
- Inference: CPU vs. GPU. For a platform processing millions of ads per week, this is a significant infrastructure cost reduction.
- Training: 15 minutes on a cheap machine vs. hours of GPU time for LLM fine-tuning.
- Maintenance: Frequent retraining to keep up with catalog changes is now trivial.
Performance Gains
- Higher accuracy on attribute prediction
- Lower latency (sub-200ms vs. seconds)
- Calibrated confidence scores enable better downstream decision-making
Competitive Advantage
LeBonCoin has published their approach publicly. Any competitor can replicate it — but the moat is in the domain-specific visual backbone and the labeled training data.
Implementation Approach
Technical Requirements
- Visual Backbone: A CNN or ViT fine-tuned on your domain images. ConvNeXt is one option; ResNet, EfficientNet, or a small ViT could work.
- Text Encoder: Character n-gram vectorizer (lightweight, robust to typos). For longer descriptions, a small transformer encoder might help.
- Fusion Transformer: Standard multi-head attention with modality embeddings. PyTorch or TensorFlow.
- Serving: KServe or similar for the embedding endpoint; CPU inference for the fuser.
Complexity
- Medium. The architecture is straightforward but requires MLOps maturity to manage the embedding pipeline and model retraining.
- Team skills needed: ML engineering, PyTorch/TensorFlow, MLOps (Kubernetes, KServe).
- Timeline: 4-8 weeks for a team with existing infrastructure.
Potential Pitfalls
- Over-reliance on the visual backbone quality. If your images are noisy or domain-shifted, embeddings may be poor.
- Attribute taxonomy drift. The classification heads need retraining when attributes change.
- Calibration may degrade on rare attribute values.
Governance & Risk Assessment
Maturity
- Production-ready. LeBonCoin has deployed this in production at scale.
- Well-documented. The architecture and results are fully described.
Risks
- Bias: If the visual backbone was trained on biased data (e.g., over-representing certain colors or materials), predictions will be biased. Regular auditing is needed.
- Privacy: ConvNeXt embeddings are extracted from user-uploaded images. Ensure embeddings don't encode personally identifiable information.
- Adversarial robustness: Prompt injection is less relevant here (no text generation), but adversarial images could fool the visual backbone.
Compliance
- GDPR: Embeddings could be considered personal data if they can be reverse-engineered to reveal user information. Pseudonymization and access controls are recommended.
- Explainability: The transformer's attention weights provide some interpretability, but not full explainability.
gentic.news Analysis
This post is a masterclass in pragmatic AI engineering. It directly addresses the tension between "use the latest LLM" and "build the right tool for the job."
The Trend: Specialization Over Generalization
LeBonCoin's journey mirrors what we're seeing across retail AI: the initial excitement about LLMs is giving way to more targeted architectures. Fine-tuning a 4B or 8B parameter model for a simple classification task was always going to be overkill. The insight here — that domain-specific embeddings plus a tiny transformer can beat a general-purpose VLM — is one that many retail teams will find valuable.
The MLOps Angle
The most impressive part isn't the architecture; it's the operational efficiency. 15-minute retraining cycles on CPU means the model can keep pace with a rapidly changing catalog. This is exactly what retail teams need when product attributes change seasonally or when new categories are added.
What This Means for Luxury
For luxury retailers, the attribute prediction problem is harder: "Is this a 'midnight blue' or 'navy'?" "Is the material 'calfskin' or 'lambskin'?" The architecture is sound, but the classification heads would need to handle fine-grained distinctions. That said, the calibrated probabilities are a huge advantage — you can set a confidence threshold and route low-confidence predictions to human reviewers.
The Bottom Line
This is a production-proven alternative to LLM-based attribute prediction that is cheaper, faster, and more accurate. Any retail or marketplace team doing structured data extraction from user-generated content should study this approach.