
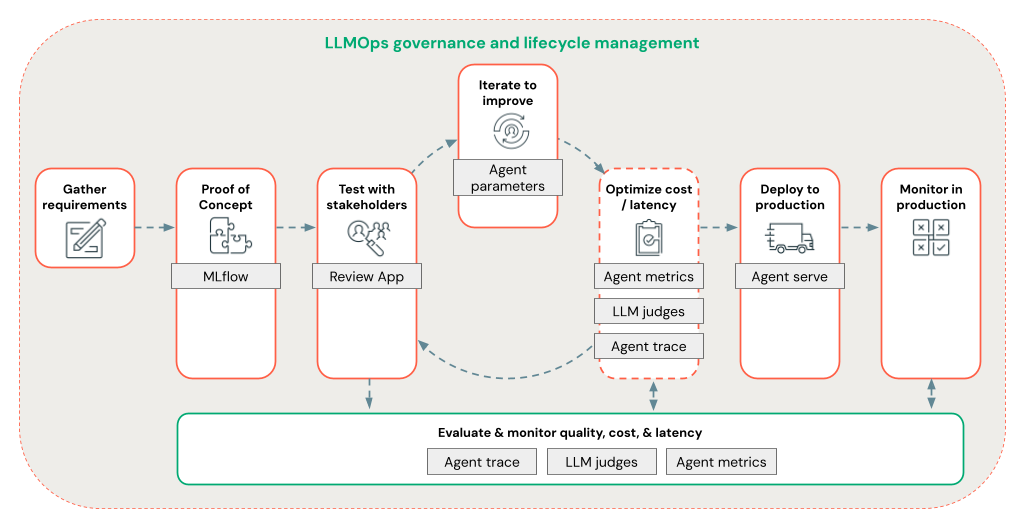
A 12-metric evaluation framework for production AI agents emerged from 100+ real-world deployments. The framework targets task success rate, cost, latency, tool use quality, and safety.
Key facts
- 12 metrics across 5 categories from 100+ agent deployments.
- Target task success rate above 85% without human intervention.
- Median cost per task target: $0.12.
- Latency P95 must stay under 5 seconds for user-facing agents.
- Tool call accuracy measured on first-attempt correctness.
A new evaluation framework for production AI agents, detailed in a Towards Data Science post, distills 12 metrics from over 100 real-world deployments. The framework covers five categories: task success, cost, latency, tool use quality, and safety [According to Building an Evaluation Harness for Production AI Agents].
Task success rate is measured as the proportion of tasks completed without human intervention, with a target above 85%. Cost per task includes API calls, compute, and human escalation costs, with a median target of $0.12 per task. Latency P95 must stay under 5 seconds for user-facing agents, per the deployments analyzed. Tool call accuracy tracks whether the agent selects and invokes the correct tool on the first attempt.
The unique take: This framework moves beyond research benchmarks like SWE-Bench or GAIA, which measure capability but not production viability. The 12-metric system explicitly penalizes agents that succeed but cost too much or take too long—tradeoffs research benchmarks ignore.
Safety metrics include refusal rate for out-of-scope tasks and hallucination frequency per 100 tasks. The framework also measures robustness: how performance degrades under adversarial inputs or distribution shifts.
A key design choice: the framework weights metrics by business context. For customer support agents, cost per task and latency carry 2x weight over task success. For coding agents, tool call accuracy and success rate dominate.
The framework does not disclose specific deployment companies or the exact distribution of metric values—the author notes this is proprietary. [According to the post], the 100+ deployments span e-commerce, banking, healthcare, and software development.
Comparisons to METR’s long-horizon evaluations show overlap on task success and cost, but METR focuses on frontier model capability while this framework targets operational metrics for production systems.
What to watch
Watch for the framework's adoption by Google Cloud's Vertex AI or by open-source agent frameworks like LangGraph. A public benchmark dataset from the deployments would validate the targets.








