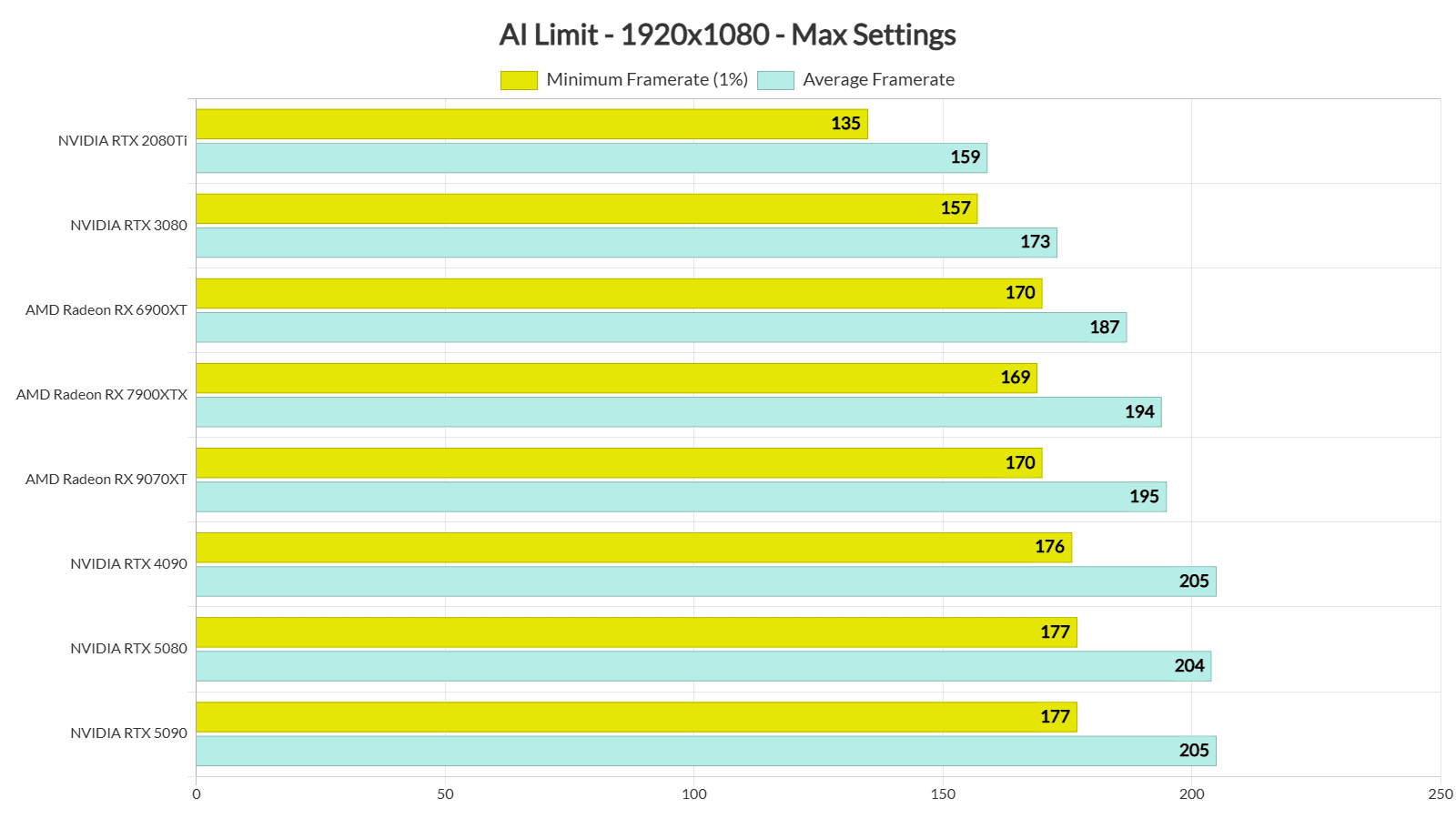
In a recent social media post, prominent AI researcher and Wharton professor Ethan Mollick announced that "another benchmark has been saturated" after asking Claude Code to complete and visualize the task. This brief statement captures a significant moment in artificial intelligence development—the point where standardized tests originally designed to measure AI capabilities are becoming trivial for advanced models to master.
The Benchmark Saturation Trend
Mollick's observation continues a pattern that has accelerated throughout 2024. Major AI benchmarks—from coding challenges like HumanEval to reasoning tests like MMLU (Massive Multitask Language Understanding)—are being conquered by models at an unprecedented rate. What once took years of incremental improvement now happens in months, with models like Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5 Pro regularly achieving near-perfect scores on established evaluation frameworks.
This benchmark saturation phenomenon represents both a triumph and a challenge for the AI community. On one hand, it demonstrates remarkable progress in model capabilities; on the other, it reveals the limitations of current evaluation methodologies. As Mollick noted in previous discussions, when benchmarks become too easy, they lose their utility as meaningful measures of advancement.
Why Benchmarks Matter (Until They Don't)
Benchmarks have served as crucial milestones in AI development for decades. They provide standardized, reproducible ways to compare different models, track progress over time, and identify areas needing improvement. The ImageNet competition revolutionized computer vision, while GLUE and SuperGLUE benchmarks transformed natural language processing.
However, the current wave of saturation reveals several limitations:
- Narrow specialization: Models can be optimized for specific benchmarks without necessarily developing general capabilities
- Data contamination: Training data may include benchmark examples, leading to inflated scores
- Lack of real-world relevance: Benchmarks often measure isolated skills rather than practical application
- Diminishing returns: Once models reach near-perfect scores, further improvements become difficult to quantify
The Visualization Component
Mollick specifically mentioned asking Claude Code to "make it visual," suggesting the benchmark involved not just solving a problem but creating a visual representation of the solution. This highlights an important evolution in AI evaluation—moving beyond text-based answers to multimodal outputs that combine reasoning, coding, and visualization capabilities.
Modern AI systems are increasingly expected to handle complex, multi-step tasks that mirror real-world workflows. A model that can solve a mathematical problem, implement the solution in code, and create an explanatory visualization demonstrates more sophisticated understanding than one that simply produces a correct numerical answer.
Implications for AI Development
The saturation of existing benchmarks necessitates a paradigm shift in how we evaluate AI systems. Several approaches are emerging:
Dynamic Benchmarks: Tests that adapt difficulty based on model performance or generate novel problems to prevent memorization.
Real-World Evaluation: Measuring performance on practical tasks like software development, scientific research, or creative projects rather than standardized tests.
Multi-Modal Challenges: Assessments that require combining language, vision, audio, and reasoning capabilities.
Adversarial Testing: Deliberately designing challenging edge cases to probe model limitations rather than measuring average performance.
The Human-AI Collaboration Dimension
Mollick's approach—asking an AI to complete and visualize a benchmark—itself represents an important trend: evaluating AI not in isolation but as part of human-AI collaborative workflows. The most valuable AI systems may not be those that score highest on benchmarks but those that most effectively augment human capabilities in complex, open-ended tasks.
This perspective suggests future evaluation frameworks might measure:
- How much AI assistance improves human performance
- The quality of AI explanations and reasoning transparency
- Adaptability to novel situations beyond training data
- Efficiency in real-world problem-solving contexts
Looking Forward
As benchmarks continue to saturate, the AI community faces both technical and philosophical questions. What constitutes meaningful progress once models achieve near-perfect scores on existing tests? How do we design evaluation frameworks that remain challenging as capabilities advance? What aspects of intelligence remain difficult to measure?
Mollick's brief observation points toward several likely developments:
- Benchmark proliferation: More specialized, challenging benchmarks targeting specific capabilities
- Evaluation methodology innovation: New approaches like automated red teaming, real-world deployment tracking, and longitudinal studies
- Shift toward application metrics: Greater emphasis on how AI performs in actual use cases rather than artificial tests
- Increased focus on limitations: More systematic investigation of where models fail rather than just where they succeed
Conclusion
The saturation of another benchmark, as noted by Ethan Mollick, marks both an achievement and a turning point. It celebrates the remarkable capabilities of current AI systems while challenging researchers to develop more sophisticated ways to measure progress. As AI continues to advance, our evaluation frameworks must evolve alongside the technology, ensuring we have meaningful ways to understand, compare, and guide development toward beneficial outcomes.
The coming years will likely see increased experimentation with evaluation methodologies, greater emphasis on real-world performance, and more nuanced understanding of what constitutes genuine intelligence versus benchmark optimization. How we measure AI progress will fundamentally shape what kinds of AI systems we develop—making this an essential conversation for researchers, developers, and society at large.
Source: Ethan Mollick (@emollick) on Twitter/X