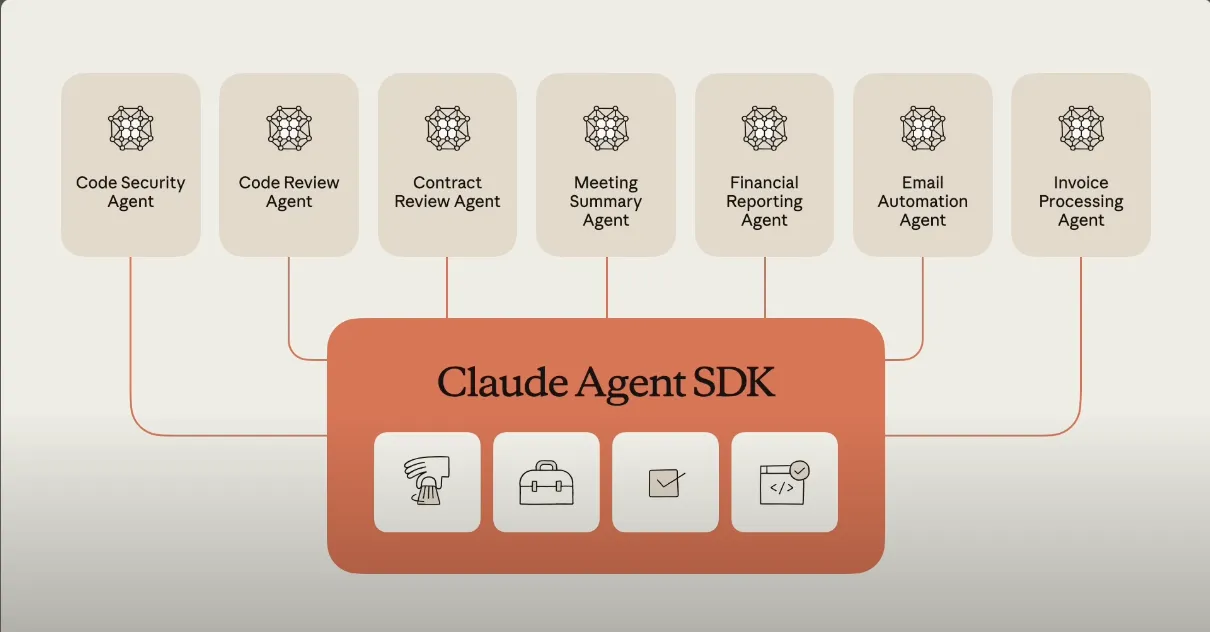
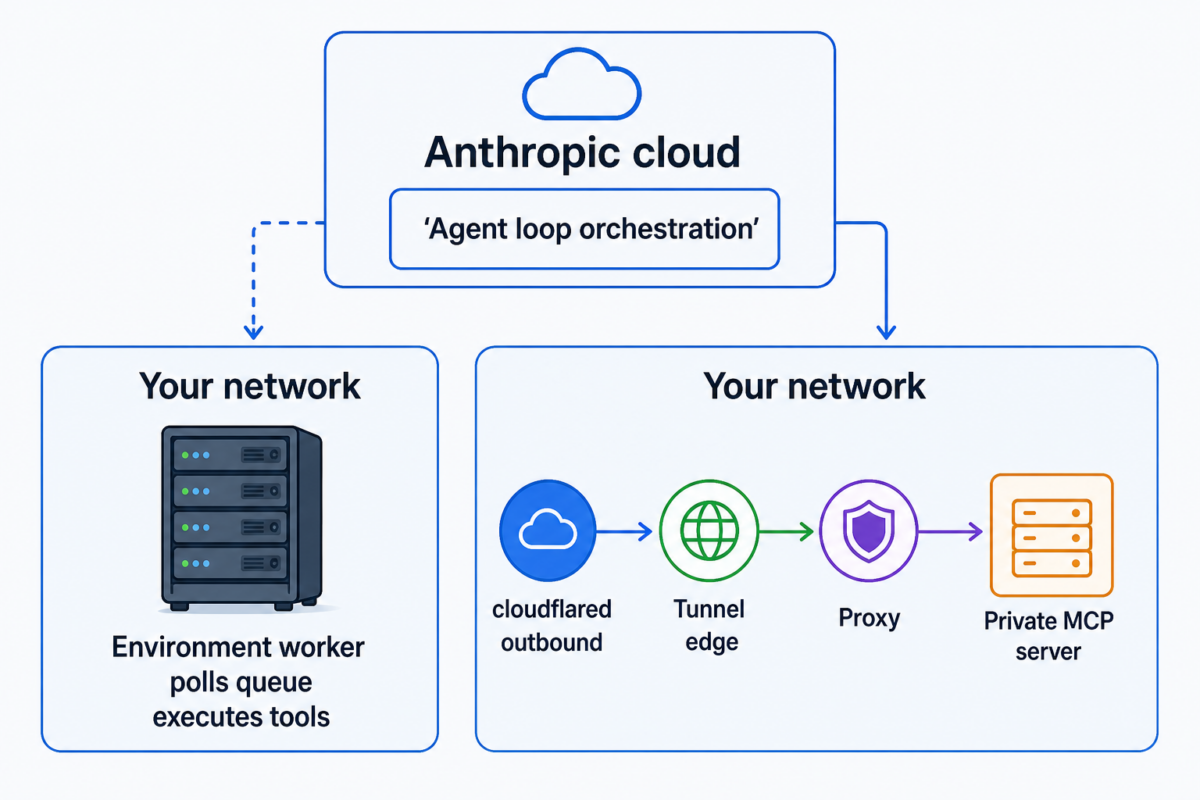
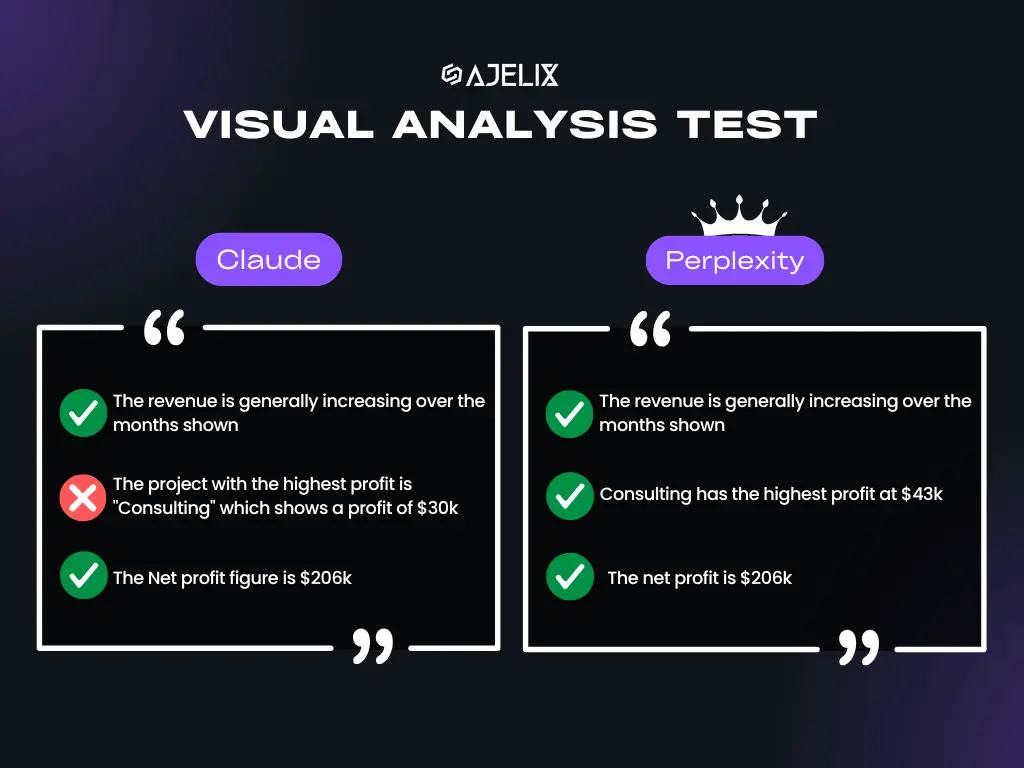
A claim circulating on social media platform X (formerly Twitter) alleges that Anthropic's Claude AI assistant possesses a secret, unadvertised operational mode. According to a tweet from user @hasantoxr, this mode is called the "Benjamin Franklin Persuasion & Leverage Machine."
The tweet, which has gained traction, states that this mode "diagnoses exactly why your…" before being cut off, suggesting it analyzes arguments or situations to identify persuasive levers. The original post and subsequent retweets contain no technical documentation, code snippets, API examples, or benchmark data to substantiate the claim. The feature's existence, capabilities, and intended use case remain unverified by Anthropic.
What Was Claimed?
The core of the claim is the existence of a specialized, hidden function within Claude, named after Benjamin Franklin, a historical figure often associated with diplomacy and persuasive writing. The naming implies a focus on rhetorical strategy and influence. The truncated description—"diagnoses exactly why your…"—hints at an analytical function, possibly designed to deconstruct conversations, negotiations, or written content to find points of advantage or weakness.
Context & Lack of Official Information
As of this reporting, Anthropic has not released any official statement, research paper, or product update confirming or detailing such a feature. The claim originates solely from a social media post without accompanying evidence. In the AI development community, rumors of "secret modes" or "hidden capabilities" in large language models (LLMs) occasionally surface, often related to:
- Internal testing tools used by developers before public release.
- Specialized system prompts or "jailbreaks" discovered by users that elicit unusual model behavior.
- Misinterpretations of a model's standard reasoning capabilities when applied to specific tasks like debate or analysis.
Without official details, it is impossible to assess whether this refers to a dedicated model variant, a constrained system prompt used internally, a fine-tuned version for specific enterprise clients, or is an unsubstantiated rumor.
The Broader Landscape of AI and Persuasion
The claim touches on a real and active area of AI research and concern: the potential for LLMs to become highly effective persuasion engines. Research has demonstrated that LLMs can generate tailored, compelling arguments and are increasingly being integrated into sales, marketing, and negotiation software. Anthropic's own research has heavily emphasized AI safety and alignment, making the alleged name and purpose of this mode particularly notable if true.
Key questions this rumor raises, absent official confirmation:
- Mechanism: Is it a separate model, a fine-tuned version of Claude Opus or Sonnet, or simply a structured system prompt?
- Access: Who has access? Is it an internal R&D tool, an enterprise-only feature, or a public capability awaiting launch?
- Capability: What specific metrics or benchmarks would define a "Persuasion & Leverage Machine"? How would its performance be measured against a base model?
- Ethics & Safety: How would such a tool be constrained to prevent misuse in manipulative or coercive contexts—a core concern for a company like Anthropic?
gentic.news Analysis
This rumor, while unverified, intersects with several established trends and entities within our knowledge graph. First, it directly involves Anthropic, a entity currently marked as 📈 Trending, indicating a high frequency of recent news and developments. This activity spike is likely driven by the competitive launch of Claude 3.5 Sonnet and its strong performance on coding benchmarks, which we covered in detail last month. The claim of a secret persuasion mode aligns thematically with Anthropic's published work on Constitutional AI and model alignment, but would represent a sharp, applied turn towards instrumental reasoning capabilities.
Second, the theme of AI persuasion connects to broader industry movements. Our previous reporting on OpenAI's o1 model series highlighted the industry push towards enhanced reasoning and strategic planning within LLMs. A "leverage diagnosis" tool would be a concrete, applied step in that direction. Furthermore, this rumor emerges amidst growing scrutiny from policymakers and regulators concerning the use of AI in targeted advertising, political campaigning, and financial negotiations—domains where "leverage" is a key commodity.
If there is substance to this claim, it likely represents an internal prototyping tool or a specialized application for a closed beta. Anthropic's strategy, as tracked in our KG, has been to release capabilities incrementally after extensive safety testing. A full public release of an unconstrained "persuasion engine" would contradict their established pattern and risk significant reputational damage. A more plausible scenario is that this is a misinterpretation of Claude's advanced chain-of-thought reasoning when applied to negotiation role-play or textual analysis prompts.
Frequently Asked Questions
Is Claude's 'Benjamin Franklin' mode real?
There is no official confirmation from Anthropic. The claim originates from a single social media post without supporting evidence such as documentation, screenshots, or API responses. It should be treated as an unverified rumor until Anthropic makes a statement or evidence is produced.
What would an AI persuasion mode actually do?
In theory, a specialized AI mode for persuasion could analyze a given text, conversation transcript, or scenario to identify logical fallacies, emotional appeals, value alignments, and potential points of compromise or pressure. It could then generate strategic advice or draft counter-arguments designed to increase the likelihood of a desired outcome. This goes beyond standard text generation into the realm of strategic analysis and instrumental reasoning.
Why is this rumor significant if it's not confirmed?
It highlights intense public and professional interest in the frontier capabilities of LLMs, particularly around reasoning, strategy, and influence. It also tests Anthropic's communication transparency and touches on core ethical debates about developing AI that can systematically optimize for human persuasion—a dual-use technology with high potential for misuse.
How does this relate to Anthropic's focus on AI safety?
Anthropic's foundational research is built on Constitutional AI, which aims to align models with human intent and ethical principles. Developing a tool explicitly for "leverage" and persuasion would require exceptionally robust safeguards to prevent manipulation and ensure the tool is used consensually and transparently. The rumor, therefore, creates a tension between commercial application of advanced reasoning and the company's public safety-first ethos.