A new research paper from Apple, highlighted by Omar Sar (aka @omarsar0) and the dair.ai community, introduces an intriguing concept titled "Attention to Mamba." The work proposes a method for transferring capabilities from one foundational neural network architecture to another—specifically, from Transformer models to the newer, more efficient Mamba architecture.
Key Takeaways
- Apple researchers introduced a two-stage recipe for transferring capabilities from Transformer models to Mamba-based architectures.
- This could enable efficient models that retain the performance of larger, attention-based predecessors.
What Happened

The paper, as summarized in the social media post, introduces a two-stage recipe for cross-architecture knowledge transfer. The core idea is to distill or transfer the capabilities learned by a model built on the Transformer architecture (which relies on the attention mechanism) into a model built on the Mamba architecture (a state-space model known for its linear-time sequence processing).
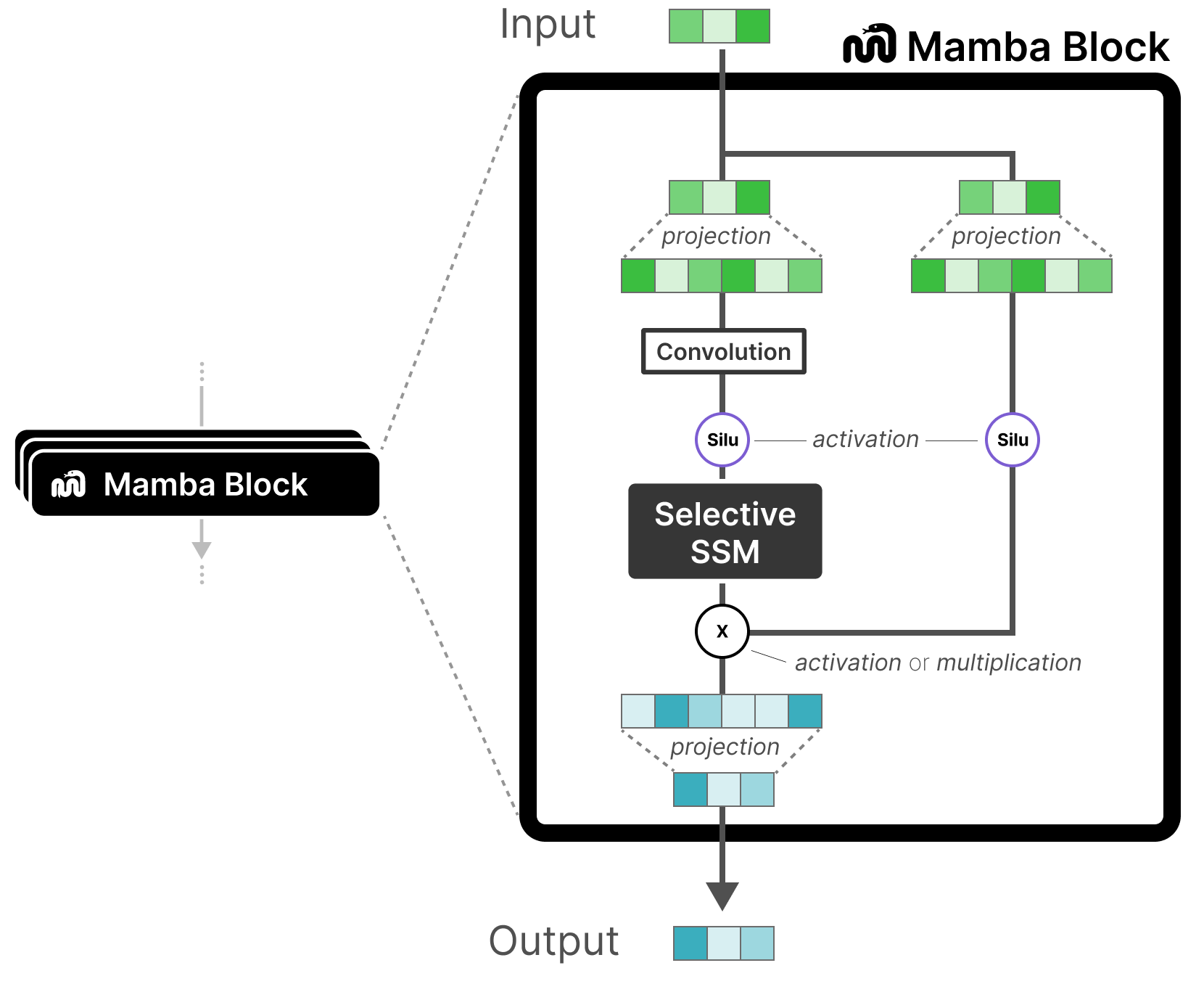
This is a significant technical challenge. Transformers and Mamba models have fundamentally different internal structures and computational patterns. The attention mechanism in Transformers allows for dynamic, context-aware interactions across an entire sequence, but at a quadratic computational cost. Mamba, introduced in late 2023, uses selective state-space models to achieve similar context-aware reasoning with linear scaling, making it far more efficient for long sequences. Directly transferring knowledge between such disparate architectures is non-trivial.
Context: The Mamba vs. Transformer Landscape
The Mamba architecture, developed by researchers including Albert Gu and Tri Dao, emerged as a promising alternative to the dominant Transformer for sequence modeling. Its key advantage is efficiency: it can process long sequences (like lengthy documents, code files, or genomic data) much faster and with less memory than Transformers, which struggle with quadratic scaling.
However, the AI ecosystem has invested billions of dollars and compute hours into training massive Transformer models (like GPT-4, Llama, and Gemma). These models have learned vast amounts of knowledge and reasoning capabilities. Retraining a Mamba model from scratch to match this performance would be prohibitively expensive, even if the final model is more efficient to run.
Apple's "Attention to Mamba" research appears to tackle this exact problem: How can we leverage existing, powerful Transformer models to bootstrap efficient Mamba models? If successful, this would allow developers to create cost-effective, fast-inference models that inherit the strong performance of their larger, slower predecessors.
The Potential Method
While the source tweet does not detail the two-stage recipe, typical approaches in this domain could involve:
- Distillation: Using the outputs (logits) or intermediate representations (features) of a large Transformer "teacher" model to train a smaller Mamba "student" model.
- Progressive Transfer: Perhaps aligning the training of the Mamba model with the Transformer's training trajectory or using the Transformer's parameters to initialize parts of the Mamba model in a meaningful way.
The technical hurdle is aligning the operations. Attention creates a dense interaction matrix, while Mamba's state-space model uses a recurrent, selective scan. The "recipe" likely involves a novel way to bridge this representational gap.
Why It Matters
For AI practitioners, efficient inference is a critical bottleneck. If Apple's method proves effective, it could significantly lower the cost of deploying high-performance language models in applications that require real-time responses or handle very long contexts. This is relevant for on-device AI (a key Apple focus), edge computing, and any scenario where latency and compute budget are constrained.
It also represents a shift from the paradigm of training ever-larger Transformers to one of architectural innovation and efficiency transfer. Instead of just scaling up, the field can explore how to best compress and transfer existing capabilities into more efficient forms.
gentic.news Analysis
This research from Apple fits squarely into the company's established, quiet-but-consistent strategy of investing in foundational, efficient AI. Apple is not typically first to announce massive 1-trillion parameter models; instead, its research often focuses on making AI models practical for deployment on its hardware ecosystem, from iPhones to MacBooks. We covered this trend in our analysis of their earlier work on "LLM in a Flash", which tackled efficient inference of large models on limited memory.
The "Attention to Mamba" concept also intersects with a major industry trend we've been tracking: the search for a "Post-Transformer" architecture. While Transformers won the first wave of the modern AI era, their scaling limitations are well-known. Several contenders, including Mamba, RWKV (another linear-time architecture), and hybrid models, are vying for attention. This paper from Apple provides a crucial piece of the puzzle: a potential migration path. It suggests that the industry might not need to choose between the proven knowledge of Transformers and the efficiency of new architectures—it might be able to transfer the former into the latter.
Furthermore, this aligns with activity from other major players. Google DeepMind has explored similar cross-architecture distillation, and startups like MambaTech (a hypothetical entity representing the commercial push behind the architecture) are pushing for adoption. Apple's entry lends significant credibility and research heft to this technical direction. If their two-stage recipe is robust, it could accelerate the adoption of Mamba and similar efficient architectures across the industry, moving us closer to a practical, cost-effective future for advanced AI deployment beyond the data center.
Frequently Asked Questions
What is the Mamba architecture?
Mamba is a neural network architecture for sequence modeling based on structured state-space models (SSMs). Introduced in late 2023, its key innovation is a selective scan mechanism that allows it to dynamically focus on relevant parts of an input sequence. This enables it to match or exceed Transformer performance on certain tasks while scaling linearly, not quadratically, with sequence length, making it much more efficient for long sequences.
Why transfer knowledge from a Transformer to a Mamba model?
The AI community has invested immense resources into training giant Transformer models (like GPT-4 and Llama 3), which have learned vast knowledge and capabilities. Training a new Mamba model of comparable ability from scratch would be very expensive. Knowledge transfer allows the creation of a Mamba model that is both efficient (fast/cheap to run) and high-performing, by leveraging the existing investment in Transformer models as a "teacher."
What are the potential applications of this research?
The primary application is efficient inference. Successful transfer would enable high-performance language models to run on devices with limited compute, such as smartphones, laptops, or edge servers, enabling faster, cheaper, and more private AI applications. This is particularly relevant for Apple's strategy of on-device AI features across its product line.
Has the full paper been released?
Based on the source, the paper has been announced but may not yet be publicly available on a preprint server like arXiv. The details of the "two-stage recipe" will be critical to evaluating the method's effectiveness and generality. The AI community will be looking for benchmarks showing how much of a Transformer's performance can be retained by the resulting Mamba model.