
BioMatrix, a decoder-only model from an undisclosed lab, maps molecules, proteins, and language into one shared token space. Trained on 304B tokens, it achieves state-of-the-art on 77 of 80 biological tasks.
Key facts
- 304B tokens in training corpus.
- Decoder-only architecture for sequences, structures, language.
- SOTA on 77 of 80 biological tasks.
- First biological model with native multimodal generation.
- Lab and parameter count not disclosed.
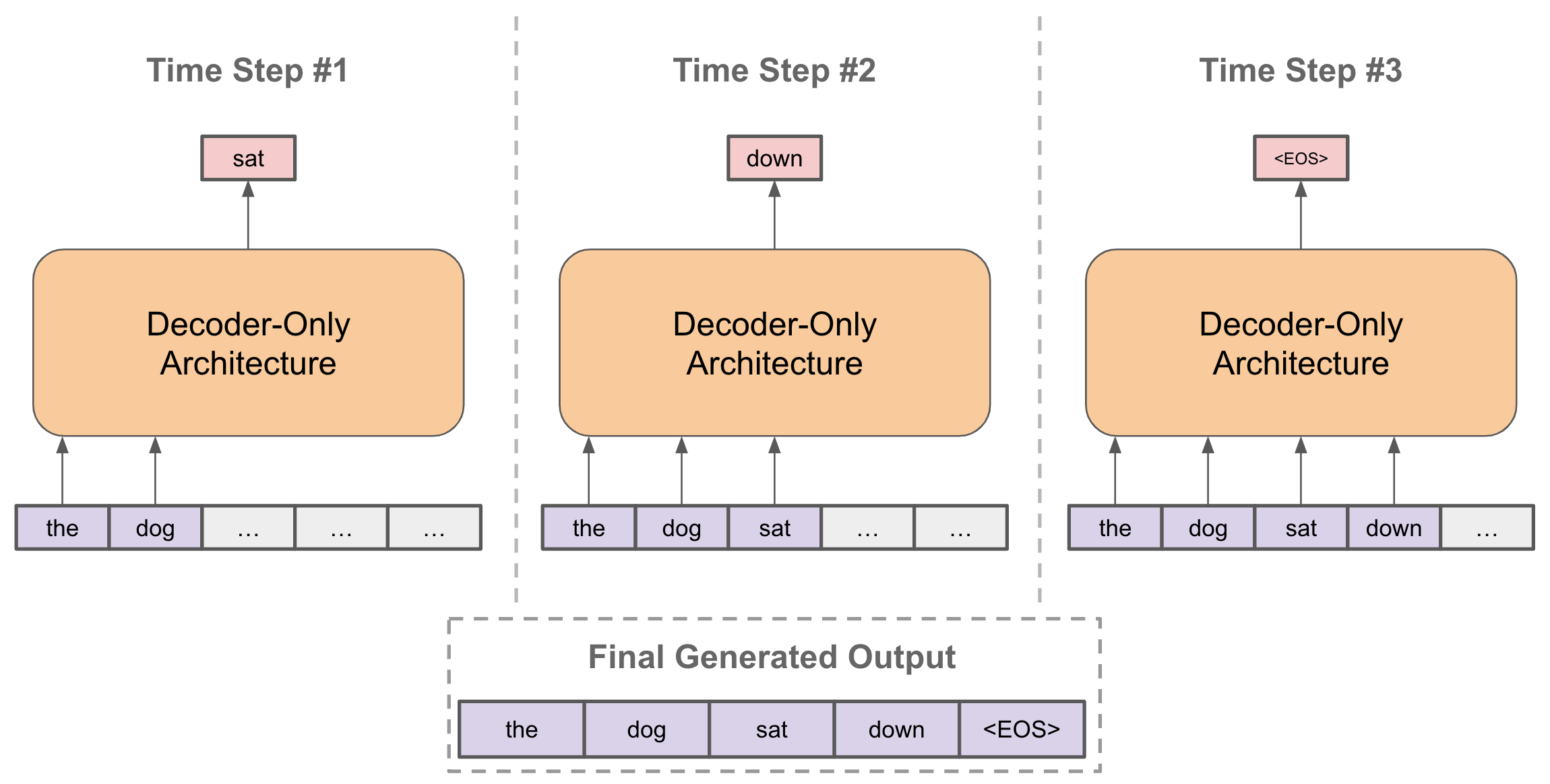
BioMatrix, announced via @HuggingPapers, is described as the first biological foundation model to natively read and generate sequences, structures, and language. Its single decoder-only architecture maps molecules and proteins into one shared token space, unifying modalities that previously required separate encoders or task-specific heads.
The training corpus of 304B tokens covers protein sequences, molecular graphs, and natural language, though the exact data composition and source are not disclosed. On a benchmark spanning 80 tasks — likely including fold prediction, binding affinity, and molecular property prediction — BioMatrix achieves SOTA on 77, a 96% win rate that suggests the unified token space transfers effectively across modalities.
Why a single decoder matters
Most biological models use encoder-only (e.g., ESM-2) or encoder-decoder architectures. A decoder-only design, popularized by GPT-style language models, allows native generation of sequences and structures without task-specific heads. This architectural choice implies the model can autoregressively generate novel proteins or molecules conditioned on natural language prompts, a capability that encoder-only models cannot match.
What remains unknown
The announcement lacks details on model size, parameter count, training hardware, and exact benchmark definitions. Without a published paper or code release, replicating the claimed SOTA results is impossible. The source tweet also does not name the lab or organization behind BioMatrix, making independent verification difficult. The 304B token count is large by biology standards — comparable to the training data of ESM-2 (around 250M sequences) — but the tokenization scheme and vocabulary size are unspecified.
Comparison to prior work
Recent biological foundation models like ESM-2 (encoder-only, 3B parameters), ProtGPT2 (decoder-only, 738M parameters), and MolT5 (encoder-decoder for text+molecule) have each advanced specific subdomains. BioMatrix claims to unify all three modalities. If validated, this would represent a step toward a single model that can perform drug discovery, protein engineering, and molecular generation without task-specific fine-tuning.
What to watch
Watch for a preprint or code release from the lab behind BioMatrix. If the 77/80 SOTA claim holds under independent replication, expect a wave of decoder-only biological models. If no paper appears within 60 days, treat the announcement as marketing.







