What The Leak Revealed
Yesterday, a source code leak for Anthropic's Claude Code revealed a startling detail about its safety system for cybersecurity work. The entire guardrail was a single text file containing one instruction: "Be careful not to introduce security vulnerabilities."
This follows Anthropic's March 2026 launch of their agent development kit and the expansion of Claude Code's Auto Mode preview. The leak shows that even at one of the most sophisticated AI companies, safety boundaries for agents are often implemented as prompts—polite requests rather than enforced rules.
Why Prompt Guardrails Fail in Production
When you're developing with Claude Code, your CLAUDE.md file and system prompts feel effective. You write "never delete production data" or "don't run dangerous shell commands," and Claude generally complies. This works in development because you're testing controlled scenarios.
The problem is probabilistic. Claude follows your instructions because that response is statistically likely given your prompt—not because it's enforced. Three conditions break this approach:
Prompt Injection: Attackers can embed instructions in documents, emails, or database records your agent reads. Research shows attack success rates exceed 90% against prompt-based guardrails.
Multi-step Reasoning: Your safety check happens at the input boundary, but agents operate across multiple steps. A clean-looking input at step one can trigger a dangerous tool call at step three that no classifier ever saw.
Model Updates: Your guardrail was tuned against one model version. When Claude updates (like the recent Claude Opus 4.6 release), the probability distribution shifts. What worked last month might not work next month.
The OWASP Agentic Top 10, published in late 2025, documents ten agent-specific attack categories that happen entirely outside prompt guardrails' watch.
The Enforcement Gap in Your Claude Code Workflow
Consider this Claude Code tool call:
{
"name": "shell/execute",
"arguments": {"command": "rm -rf /"}
}

There's a critical moment between Claude deciding to call that tool and the tool actually executing. Prompt guardrails live before this moment—in your CLAUDE.md or system prompt. Runtime enforcement lives in that moment, intercepting the call before execution with deterministic policies.
What Runtime Enforcement Looks Like
Tools like Faramesh (mentioned in the source) demonstrate the approach. Instead of relying solely on prompts, you add an enforcement layer that wraps execution:
faramesh run your_agent.py
No SDK changes to your Claude Code setup. The layer checks every tool call against policies written in a domain-specific language:
agent claude-code-agent {
default deny
model "claude-3.5-sonnet"
framework "mcp"
rules {
deny! shell/* reason: "never shell in production"
defer file/write
when path contains "production"
notify: "team-lead"
reason: "production file modification"
permit file/*
when path contains "test"
}
}
This is deterministic. A shell command gets blocked every time. A production file write gets deferred for human approval every time. The model doesn't get a vote.
Immediate Actions for Claude Code Users
Audit Your
CLAUDE.md: Identify which instructions are safety-critical versus helpful guidance. Move critical rules out of prompts.Implement Tool-Level Validation: For any MCP servers you've connected to Claude Code, add validation logic before tool execution:
# In your MCP server tool implementation
def execute_shell(command):
if "rm -rf" in command or "format" in command:
raise PermissionError("Blocked by runtime policy")
# ... execute
Separate Development from Production: Use prompt-based guidance during development, but require runtime enforcement before deploying Claude Code agents to production environments.
Monitor Tool Call Patterns: Log all tool calls from Claude Code sessions. Review patterns where Claude attempts actions your prompts should have prevented.
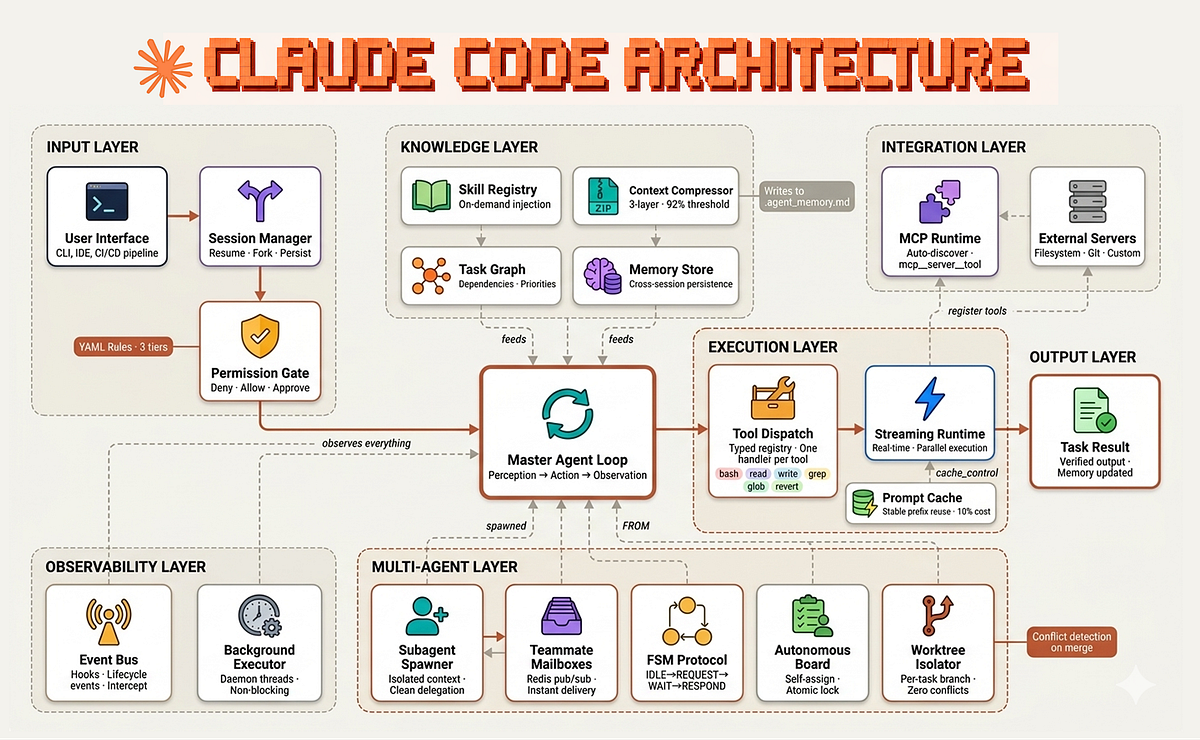
This leak isn't about Anthropic's competence—it's about the industry's current state. As Claude Code's architecture is built on MCP to connect to various backends, the enforcement layer needs to live at that integration point, not just in the prompt.
gentic.news Analysis
This revelation aligns with our previous coverage of Claude Code's architecture being built on the Model Context Protocol (MCP). The MCP connection point is precisely where runtime enforcement should occur—intercepting tool calls between Claude and connected services like GitHub, databases, or cloud platforms.
Historically, Anthropic has focused on model safety through Constitutional AI and system prompts. The leak suggests this approach extends to their developer tools like Claude Code and Claude Agent. As Anthropic reportedly considers an IPO and projects surpassing OpenAI in revenue, production-ready safety for their agent ecosystem becomes increasingly critical.
The timing is notable following Anthropic's March 2026 introduction of 'long-running Claude' capabilities. Longer-running agents increase the attack surface for prompt injection and multi-step reasoning attacks that bypass prompt guardrails.
For developers, this means treating your CLAUDE.md as helpful documentation, not security policy. The real safety layer needs to be in code that executes deterministically between Claude's intent and your system's action.