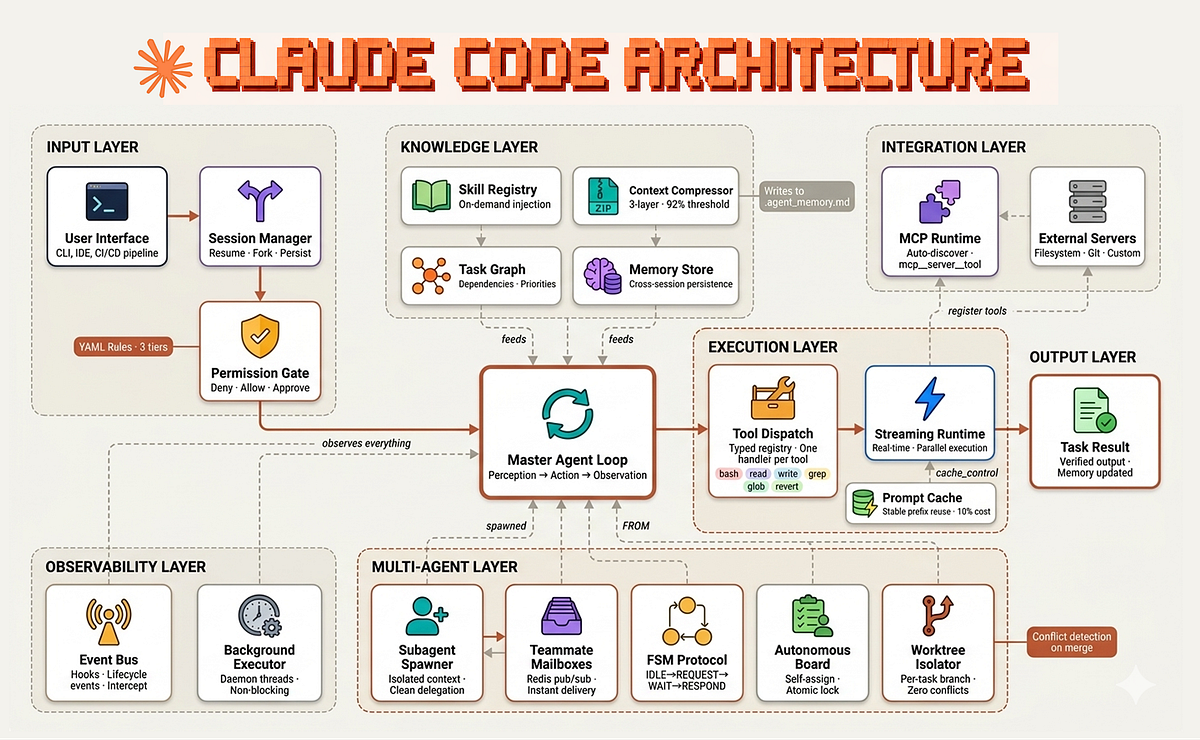
Thariq Shihipar from Anthropic's Claude Code team recently revealed how their internal team uses hundreds of skills clustered into nine categories. The most surprising insight? Skills aren't just for automation—they're primary knowledge containers for deep domain context.
This answers a critical question for developers: where does detailed repository knowledge go when you're trying to keep CLAUDE.md under the recommended 200 lines? According to Anthropic's own practice, the answer is: put it in skills.
The Skill-as-Knowledge Pattern
Looking at Anthropic's nine skill categories, at least three function primarily as knowledge repositories:
- Library & API Reference (edge cases and code snippets)
- Incident Runbooks (symptoms to investigation steps)
- Data & Analysis (reference data plus scripts)
These skills wear an "action wrapper" (slash command, trigger description) for discoverability, but their core content is context, not automation.
The Gotchas Section: Your Living Knowledge Base
Anthropic's "Build a Gotchas Section" tip reveals their approach: the highest-signal content in any skill is the gotchas section.
Here's how it works:
- Day 1: Your
billing-libskill says "How to use the internal billing library" - Month 3: It has four gotchas covering proration rounding, test-mode webhook gaps, idempotency key expiration, refund ID semantics
Knowledge accumulates over time as Claude trips on things. Each gotcha becomes a permanent addition to your team's institutional knowledge.
Hub-and-Spoke Structure for Complex Knowledge
Their queue-debugging skill demonstrates a scalable pattern:
queue-debugging/
├── SKILL.md (30 lines: symptom-to-file routing table)
├── stuck-jobs.md
├── dead-letters.md
└── retry-storms.md
This is structurally identical to having a CLAUDE.md knowledge table pointing to .claude/knowledge/*.md files. Same progressive disclosure. Same "keep the hub lean, push detail to the spokes" principle.
One Primitive or Two?
The source author notes: "If this thread had existed two months ago, we might not have built a separate knowledge layer at all."

Their team ended up with two primitives:
- Knowledge files hold domain context (what Claude should know)
- Skills hold executable actions (what Claude should do)
But Anthropic's approach shows you can handle both with one extension point, one concept to learn. Simpler.
When Separation Makes Sense
The author's team found value in separation when:
- Knowledge is shared across multiple skills - A data pipeline knowledge file is read by four different generic skills (running jobs, querying databases, querying ES, accessing S3)
- Knowledge needs to be accessed without invoking skills - Evaluation suite results interpretation requires context separate from the procedural skill that runs the tests
How To Apply This Today
1. Convert Your Knowledge Files to Skills
Take any .claude/knowledge/*.md file and wrap it in a skill:
# Create a knowledge skill
mkdir -p .claude/skills/library-reference
cat > .claude/skills/library-reference/SKILL.md << 'EOF'
# billing-library-reference
## Description
Reference for our internal billing library with accumulated gotchas
## Gotchas
- Proration rounds to nearest cent, not floor
- Test mode webhooks don't fire for subscription updates
- Idempotency keys expire after 24 hours
- Refund IDs must be prefixed with "ref_"

## Usage
Use this skill when working with billing operations
EOF
2. Implement Hub-and-Spoke for Complex Domains
For debugging knowledge:
# Hub file
cat > .claude/skills/debug-queues/SKILL.md << 'EOF'
# debug-queues
## Routing Table
- Jobs stuck for >1 hour → see stuck-jobs.md
- Dead letter queue growing → see dead-letters.md
- Retry storms detected → see retry-storms.md
EOF
# Spoke files in same directory
echo "# Stuck Jobs Troubleshooting..." > .claude/skills/debug-queues/stuck-jobs.md
3. Start a Gotchas Section in Every Skill
Even your automation skills should have a gotchas section:
## Gotchas
- [2024-05-15] The deploy script fails if AWS session token expired
- [2024-05-22] Test database must be seeded before running integration tests
- [2024-06-01] Cache invalidation takes 5 minutes, not immediate

The Evolution of Claude Code Abstractions
Skills didn't exist a year ago. Claude Code launched with commands, then skills arrived, the two overlapped for months, and eventually commands folded into skills. The core abstraction for extending Claude Code changed twice in twelve months.
This rapid evolution suggests: build for adaptability. Whether you choose skills-as-knowledge or separate knowledge files, ensure your knowledge can survive the next abstraction shift.
gentic.news Analysis
This insight from Anthropic's internal team follows their ongoing refinement of Claude Code's extension system, which began with simple commands and evolved into the more sophisticated skills architecture we have today. The revelation that skills serve dual purposes—both automation and knowledge storage—aligns with our previous coverage of how teams are pushing CLAUDE.md beyond its original design constraints.
The hub-and-spoke pattern mentioned here directly connects to our article "How to Structure Complex Repositories for Claude Code" where we recommended similar progressive disclosure techniques. What's new is Anthropic's explicit endorsement of using skills as living knowledge bases with gotcha sections that accumulate institutional wisdom over time.
This development also reflects a broader trend in AI-assisted development tools: the convergence of documentation and automation. Where teams previously maintained separate runbooks, API docs, and scripts, Claude Code's skills abstraction allows these to exist as a single, executable knowledge unit. As the ecosystem matures, we're seeing teams standardize on fewer, more powerful primitives rather than proliferating specialized tools.
The author's note about abstraction shifts is particularly relevant given Claude Code's rapid evolution. Teams building on this platform should design their knowledge systems to be portable between abstraction layers, whether that means keeping knowledge in markdown files that can be wrapped in different containers or using skills in ways that separate content from presentation.