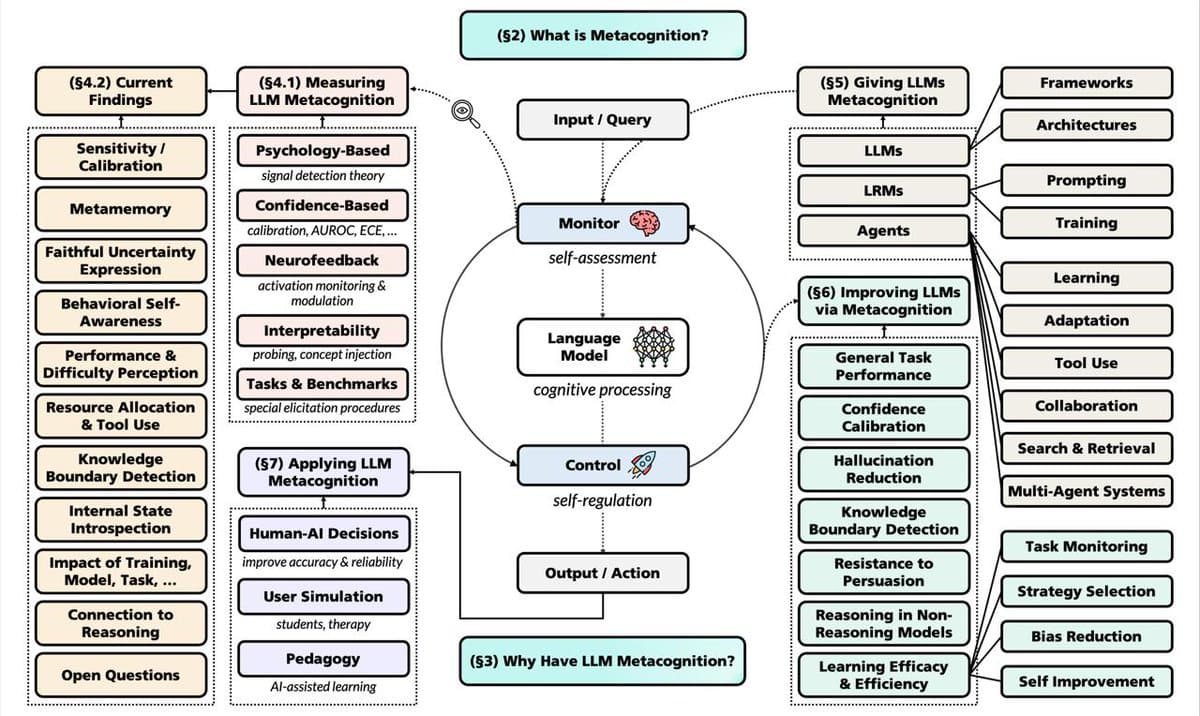
Key Takeaways
- A new benchmark called the Novel Operator Test reveals that large language models can perform every step of logical reasoning correctly yet still declare the wrong final answer.
- This dissociation between reasoning process and output accuracy challenges assumptions about LLM reliability for complex tasks.
What Happened

Researchers have published a paper titled "Correct Chains, Wrong Answers: Dissociating Reasoning from Output in LLM Logic" that introduces a novel benchmark revealing a critical flaw in how we evaluate large language models. The core finding: LLMs can execute every step of chain-of-thought reasoning perfectly while still producing incorrect final answers.
The research team created the Novel Operator Test, which separates operator logic from operator names to distinguish between genuine reasoning and pattern retrieval. By evaluating Boolean operators under unfamiliar names across depths 1-10 on five models (testing up to 8,100 problems each), they demonstrated a reasoning-output dissociation that existing benchmarks cannot detect.
Technical Details
The benchmark's design is elegant in its simplicity. Instead of using familiar Boolean operator names like "AND" or "OR," researchers assigned novel names to these operators while keeping their logical truth tables identical. This approach isolates whether models are performing genuine logical reasoning or simply retrieving memorized patterns associated with familiar terminology.
Key findings include:
- Claude Sonnet 4 at depth 7: All 31 errors had verifiably correct reasoning steps but wrong declared answers
- Mixed-operator chains: 17 out of 19 errors exhibited the same pattern of correct reasoning with wrong outputs
- Two distinct failure types: Strategy failures at depth 2 (where models attempt terse retrieval, with +62 percentage point improvement from scaffolding) and content failures at depth 7 (where models reason fully but err systematically, with +8-30pp improvement, and 0/300 errors post-intervention)
- Trojan operator experiment: Using XOR's truth table under a novel name confirmed that the operator name alone doesn't gate reasoning (p ≥ 0.49)
- Llama's performance: Showed a novelty gap widening to 28 percentage points at depth 8-9, with the Trojan operator achieving 92-100% accuracy, isolating genuine difficulty with novel logic from name unfamiliarity
This research fundamentally challenges the assumption that correct chain-of-thought reasoning guarantees correct final answers—a premise that underlies much of current LLM evaluation methodology.
Retail & Luxury Implications
While this research doesn't directly address retail applications, its implications for AI reliability in business contexts are profound. For luxury and retail companies deploying LLMs for critical functions, this dissociation between reasoning and output represents a significant risk factor.
Potential impact areas include:
Automated Pricing and Inventory Logic: If an LLM-based system correctly reasons through supply chain constraints, demand forecasting, and margin calculations but still outputs incorrect pricing recommendations, the financial consequences could be substantial.
Customer Service Escalation Routing: Models might correctly analyze customer sentiment, issue complexity, and agent availability in their reasoning chain but still route high-value clients to inappropriate support tiers.
Personalized Recommendation Systems: The reasoning behind why a particular product should be recommended to a specific customer might be logically sound, but the final recommendation could be wrong due to this output dissociation.
Supply Chain Optimization: LLMs assisting with logistics planning might correctly process all constraints and variables in their reasoning but output suboptimal or even contradictory routing decisions.
The research suggests that current evaluation methods—which often focus on reasoning chain correctness—may be insufficient for production systems. Retail AI teams need to implement additional validation layers that specifically test for this reasoning-output dissociation in their domain-specific applications.
Implementation Considerations
For technical leaders in retail, this research indicates several necessary adjustments to LLM deployment strategies:
Enhanced Validation Protocols: Beyond checking reasoning steps, systems must include independent verification of final outputs against ground truth or multiple reasoning paths.
Novelty Testing: Before deploying LLMs to new domains or problem types, teams should test whether the model is performing genuine reasoning or pattern matching by creating "novel operator" equivalents in their specific domain.
Scaffolding Requirements: The research shows significant improvements (+62pp) from providing proper scaffolding at depth 2, suggesting that carefully designed prompts and context can mitigate some failure modes.
Monitoring for Systematic Errors: The content failures at depth 7 that were systematic (+8-30pp improvement) indicate that certain error patterns may be predictable and detectable in production systems.
Governance & Risk Assessment
This research elevates several risk categories for retail AI deployments:
- Accuracy Risk: Even with correct reasoning, wrong outputs create direct business impact
- Detection Difficulty: These errors won't be caught by reasoning-focused evaluation methods
- Domain Transfer Risk: Models that perform well on familiar retail concepts may fail when encountering novel situations
- Explainability Gap: The dissociation between reasoning and output complicates trust and debugging
Maturity assessment: This is early-stage research that identifies a fundamental limitation in current LLM capabilities. Production systems should treat LLM outputs as requiring additional verification layers, particularly for high-stakes decisions.