Dropout, introduced by Hinton et al. in 2012, randomly disables 20-50% of neurons per training iteration. This counterintuitive technique reduces overfitting by preventing neural networks from relying on individual neurons.
Key facts
- Dropout rates typically range from 0.2 to 0.5.
- Dropped neurons skip forward and backward propagation.
- Dropout is disabled during inference.
- Each epoch trains a different subnetwork architecture.
- Dropout acts as implicit ensemble learning.
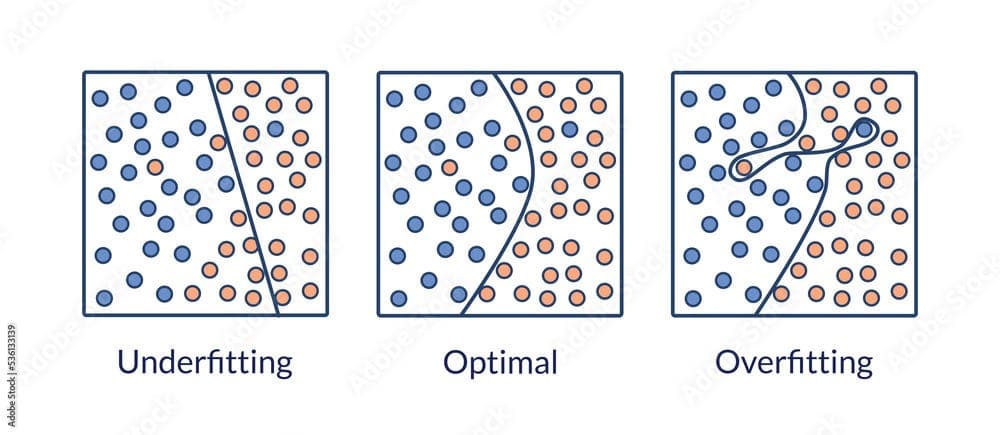
The core problem dropout addresses is overfitting in neural networks. Modern networks with millions of parameters can memorize training data rather than learning generalizable patterns. According to Understanding Dropout, a model that achieves very high training accuracy may perform poorly on test data because it creates decision boundaries too specific to the training set.
How Dropout Works
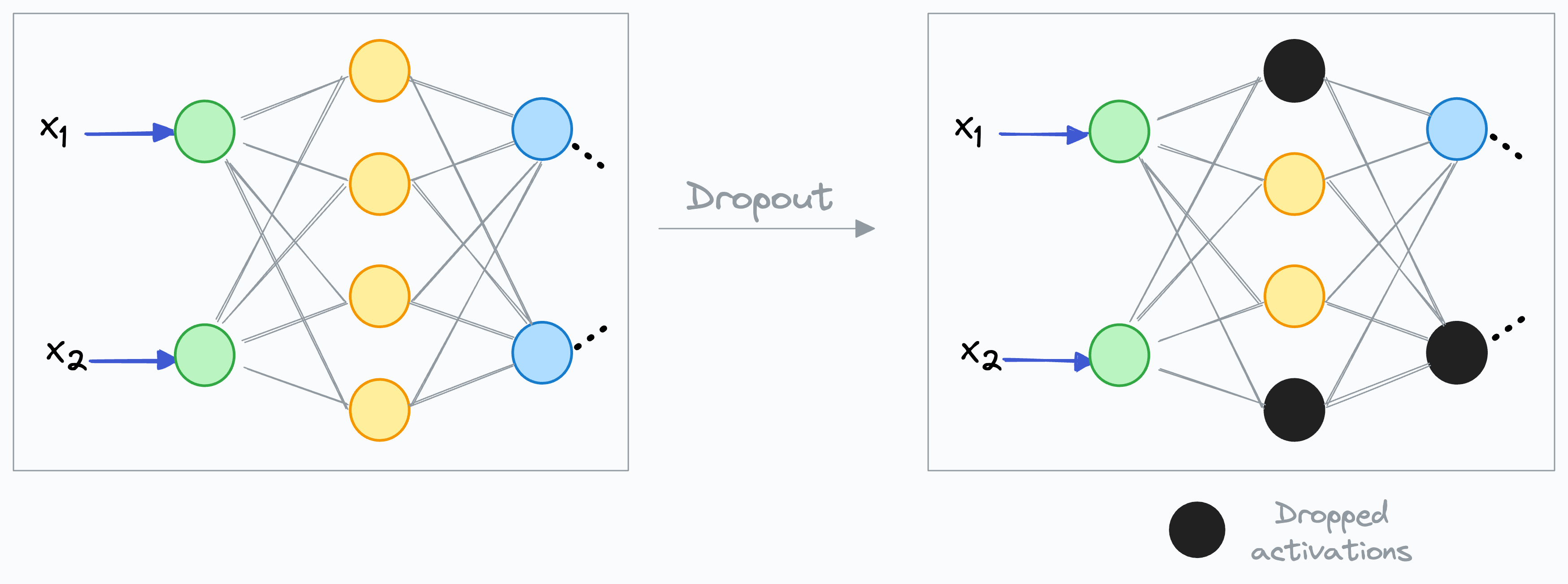
During each training iteration, dropout randomly disables a subset of neurons. The dropout rate p controls the probability — p = 0.2 drops 20% of neurons, p = 0.5 drops 50%. Dropped neurons do not participate in forward propagation or backpropagation for that iteration. Because neurons are selected randomly each epoch, the network effectively trains on a slightly different architecture every time, preventing any single neuron from becoming indispensable.
Why Dropout Improves Generalization
The mechanism is analogous to Random Forests. Rather than relying on a single decision tree, Random Forests train many trees and combine predictions. Dropout creates a similar implicit ensemble: each training iteration trains a different subnetwork. Over many epochs, the model learns from many variations of itself, distributing learning across multiple pathways. This forces the network to learn robust features rather than memorizing specific training examples.
Inference Behavior

During inference (testing), dropout is turned off — all neurons remain active. The network combines knowledge learned across all subnetworks, analogous to gathering opinions from many experts. This is why dropout often improves performance on unseen data despite removing neurons during training.
Practical Dropout Rates
Commonly used dropout values range from 0.2 to 0.5, though the optimal rate depends on dataset and architecture. A regression experiment with a two-hidden-layer network (128 neurons each) showed that increasing dropout rates changed prediction behavior, though the source did not report specific accuracy deltas.
What to watch
Watch for extensions of dropout to transformer architectures — recent work on structured dropout for attention heads and adaptive dropout rates based on neuron importance could further improve large language model training efficiency.
Source: pub.towardsai.net








