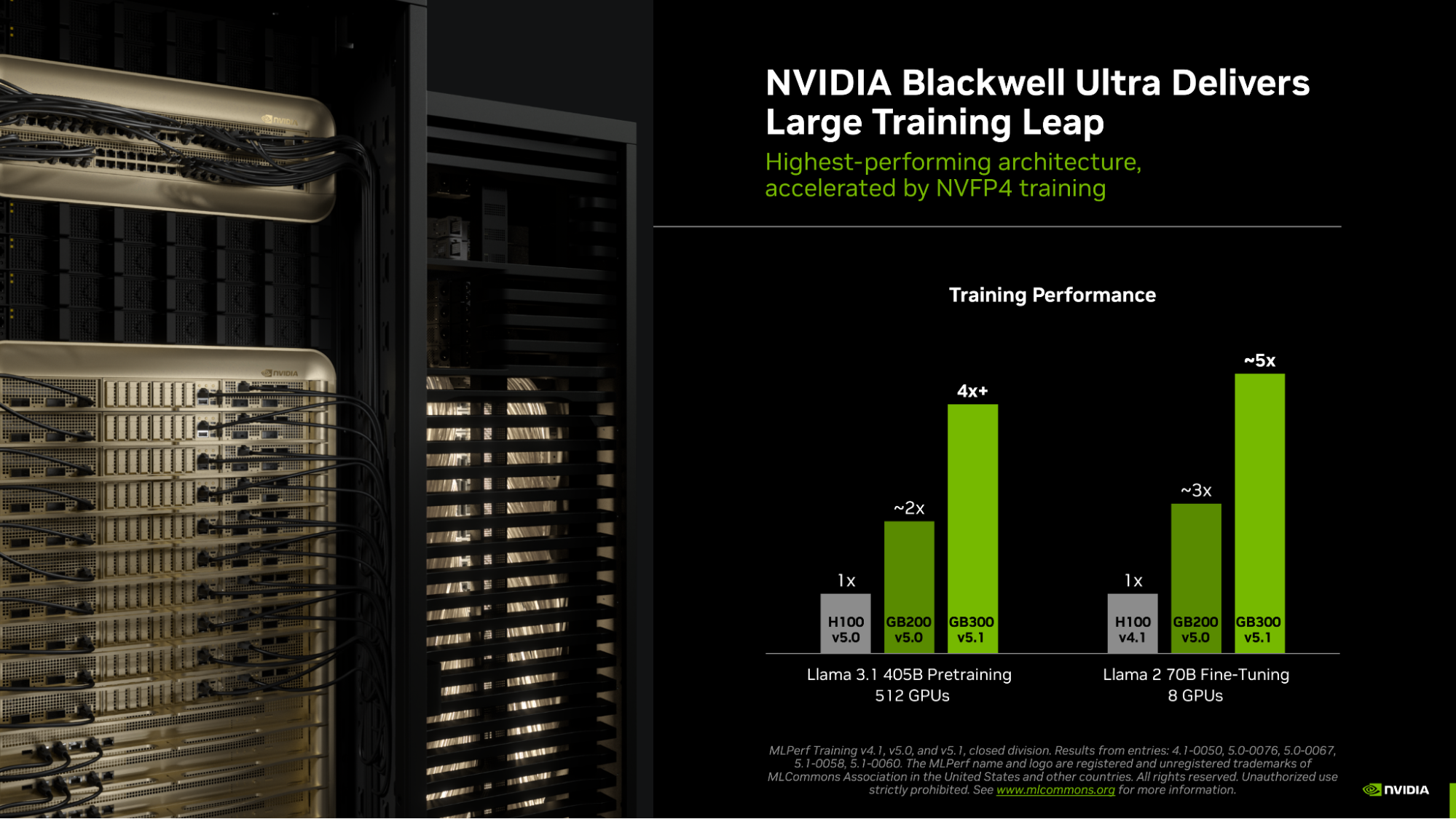
NVIDIA Blackwell swept all seven benchmarks in MLPerf Training 6.0. The GB300 NVL72 delivered up to 1.6x faster training than GB200 NVL72, using NVFP4 precision across 8,192 GPUs.
Key facts
- NVIDIA won all 7 benchmarks in MLPerf Training 6.0.
- GB300 NVL72 achieved up to 1.6x faster training than GB200 NVL72.
- deepseek-v3-671b" class="entity-chip">DeepSeek-V3 671B trained on 8,192 GPUs via NVLink.
- New MoE workloads DeepSeek-V3 671B and GPT-OSS-20B added.
- NVFP4 precision used for Nemotron 3 Ultra 550B-parameter model.
NVIDIA's Blackwell platform dominated MLPerf Training 6.0, the latest peer-reviewed industry benchmark suite for AI training performance, according to NVIDIA's blog post. The platform achieved the fastest time to train on every benchmark, including two new mixture-of-experts (MoE) pretraining workloads: DeepSeek-V3 671B and GPT-OSS-20B. NVIDIA was the only platform with submissions across all seven benchmarks in the suite.
The standout result came from the GB300 NVL72 rack-scale system, which delivered up to 1.6x faster training than the GB200 NVL72 at the same scale. Key Blackwell Ultra capabilities driving this improvement include higher compute density with NVFP4 precision, expanded memory capacity, and a higher power ceiling that lets the GPU sustain peak performance. NVIDIA also showcased NVFP4 training methods that increase performance while meeting strict accuracy requirements across large- and small-scale pretraining as well as fine-tuning workloads.
MoE Training at Scale
Large-scale MoE training faces the same all-to-all communication challenge as MoE inference — tokens must be routed across GPUs to reach the right expert subnetwork. NVIDIA's fifth-generation NVLink Switches connect all 72 GPUs within each rack-scale system with high bandwidth into a unified pool of compute and memory, enabling them to act as one giant GPU. [According to NVIDIA], this NVLink bandwidth advantage is what makes MoE training fast and efficient at scale.
To support distributed training at scale, NVIDIA offers two complementary scale-out networking platforms — NVIDIA Quantum InfiniBand and NVIDIA Spectrum-X Ethernet — giving data centers flexibility to build large-scale clusters optimized for their infrastructure. On DeepSeek-V3 671B, NVIDIA submitted results using 8,192 GPUs, the largest Blackwell cluster in MLPerf Training history.
Historical Context and Competition
This sweep comes as NVIDIA faces increasing competition from custom silicon and alternative architectures. Google's TPU v6, AMD's MI400, and Cerebras CS-3 have all posted competitive results in previous MLPerf rounds. However, NVIDIA's ability to deliver both the fastest single-system performance and the largest-scale distributed training results — while being the only vendor to submit across all benchmarks — reinforces its dominant position in AI training infrastructure.
The GB300 NVL72's 1.6x speedup over the GB200 NVL72 is particularly notable given that Blackwell was only introduced in early 2026. This rapid generational improvement suggests NVIDIA's engineering cadence remains aggressive, likely driven by Jensen Huang's directive to maintain a one-year architecture cycle.
What to Watch
Watch for the MLPerf Inference 7.0 results expected in Q4 2026, where NVIDIA will face pressure from AMD's MI400 and Google's TPU v6 on latency-sensitive workloads. Also monitor whether CoreWeave or other cloud providers can replicate NVIDIA's 8,192-GPU DeepSeek-V3 training result on their own clusters, which would validate the scalability claims independently.



Source: blogs.nvidia.com
Key Takeaways
- NVIDIA Blackwell swept MLPerf Training 6.0 across all seven benchmarks.
- GB300 NVL72 delivered 1.6x speedup over GB200 NVL72 using NVFP4 and 8,192 GPUs.